Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens ci-dessous :
Qu’est-ce que la synthèse par Chain of Density
- Commencer par une synthèse initiale
- Affiner la synthèse de manière itérative pour la rendre plus concise tout en préservant les informations clés
- Augmenter la densité des entités et des détails techniques à chaque itération
Pourquoi utiliser Weave
- Suivre votre pipeline LLM : utilisez Weave pour enregistrer automatiquement les entrées, les sorties et les étapes intermédiaires de votre processus de synthèse.
- Évaluer les sorties du LLM : créez des évaluations cohérentes de vos synthèses à l’aide des outils intégrés de Weave.
- Créer des opérations composables : combinez et réutilisez des opérations Weave dans différentes parties de votre pipeline de synthèse.
- Intégrer à du code existant : ajoutez Weave à votre code Python existant avec un minimum de surcharge.
Configurer l’environnement
Pour obtenir une clé API Anthropic :
- Inscrivez-vous et créez un compte sur https://www.anthropic.com.
- Accédez à la section API dans les paramètres de votre compte.
- Générez une nouvelle clé API.
- Stockez la clé API de façon sécurisée dans votre fichier
.env.
weave.init([PROJECT_NAME]) initialise un nouveau projet Weave pour la tâche de synthèse.
Définir le modèle ArxivPaper
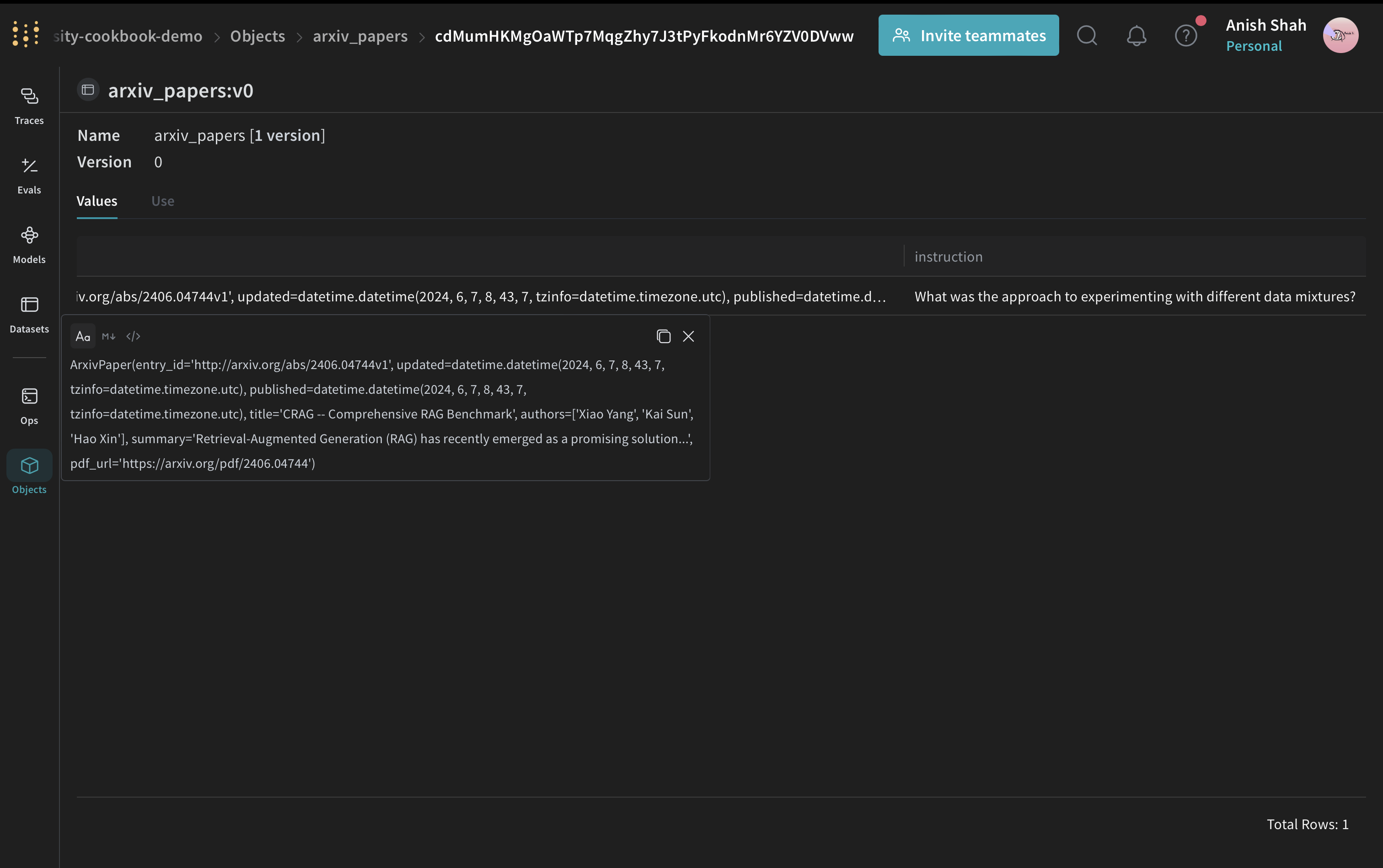
ArxivPaper pour représenter les données :
Charger le contenu du PDF
ArxivPaper contient des métadonnées et l’URL d’un PDF, mais le pipeline de synthèse a besoin du texte complet de l’article. Pour utiliser le contenu complet de l’article, ajoutez une fonction permettant de charger et d’extraire le texte des PDF :
Implémenter la synthèse par Chain of Density
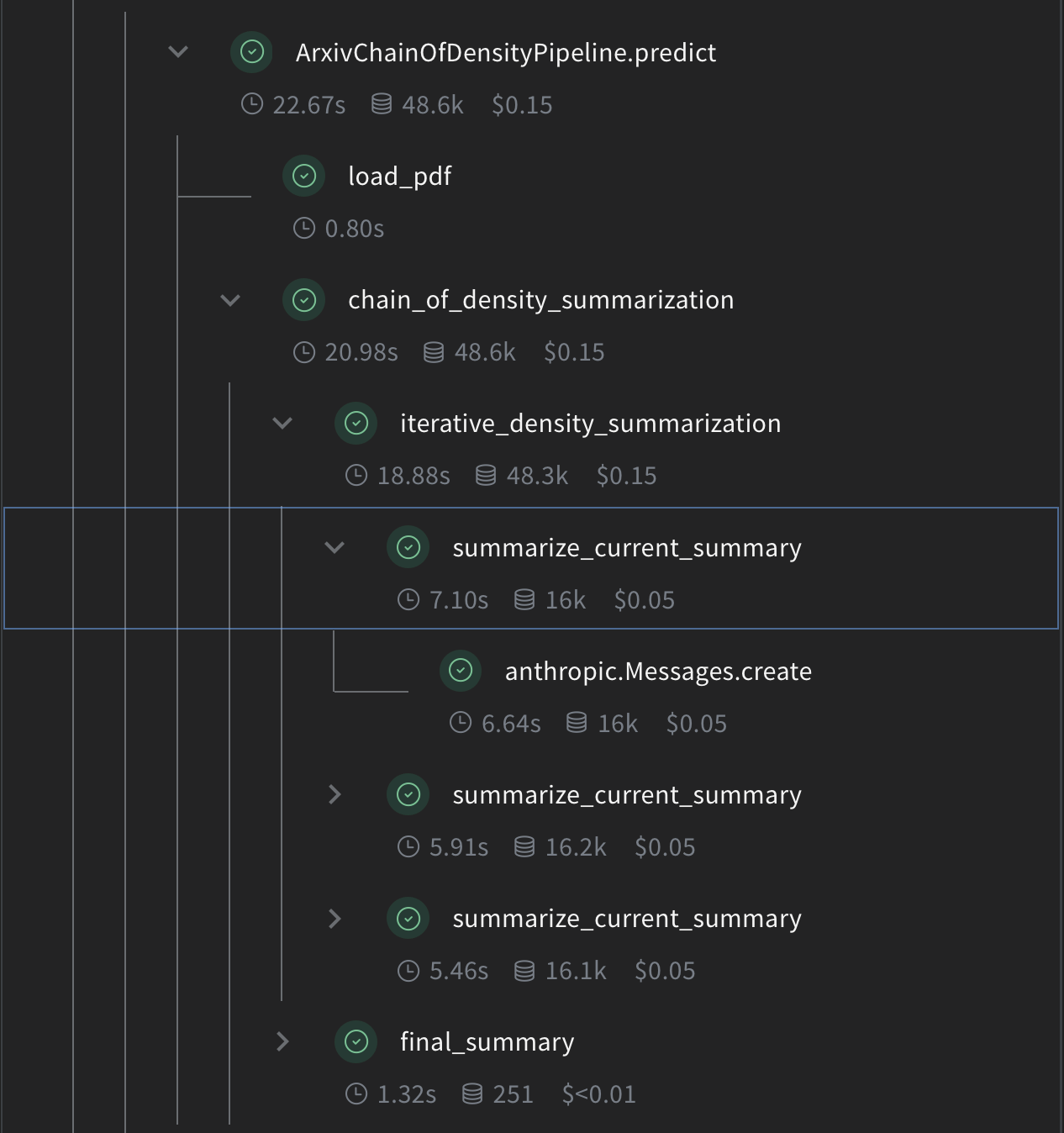
summarize_current_summary: génère une unique itération de synthèse à partir de l’état actuel.iterative_density_summarization: applique la technique CoD en appelantsummarize_current_summaryplusieurs fois.chain_of_density_summarization: orchestre l’ensemble du processus de synthèse et renvoie les résultats.
@weave.op() permettent à Weave de suivre les entrées, les sorties et l’exécution de ces fonctions.
Créer un modèle Weave
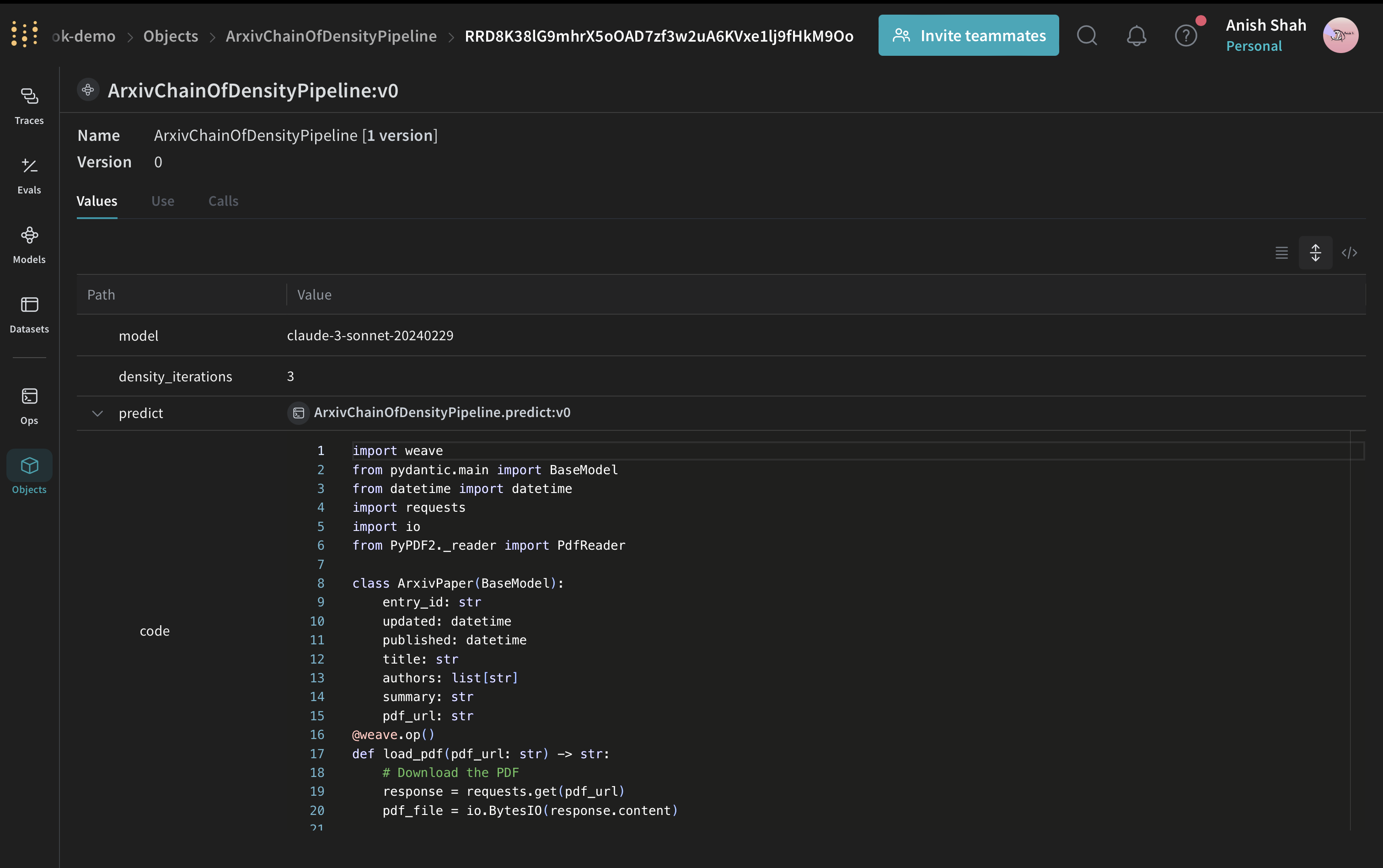
ArxivChainOfDensityPipeline encapsule la logique de synthèse sous la forme d’un modèle Weave, avec plusieurs avantages clés :
- Suivi automatique des expériences : Weave capture les entrées, les sorties et les paramètres de chaque exécution du modèle.
- Gestion des versions : Les modifications apportées aux attributs ou au code du modèle sont automatiquement versionnées, ce qui crée un historique clair de l’évolution de votre pipeline de synthèse au fil du temps.
- Reproductibilité : La gestion des versions et le suivi vous permettent de reproduire tout résultat ou toute configuration antérieurs de votre pipeline de synthèse.
- Gestion des hyperparamètres : Les attributs du modèle (comme
modeletdensity_iterations) sont clairement définis et suivis d’une exécution à l’autre, ce qui facilite l’expérimentation. - Intégration avec l’écosystème Weave : L’utilisation de
weave.Modelfonctionne avec d’autres outils Weave, comme les évaluations et les fonctionnalités de serving.
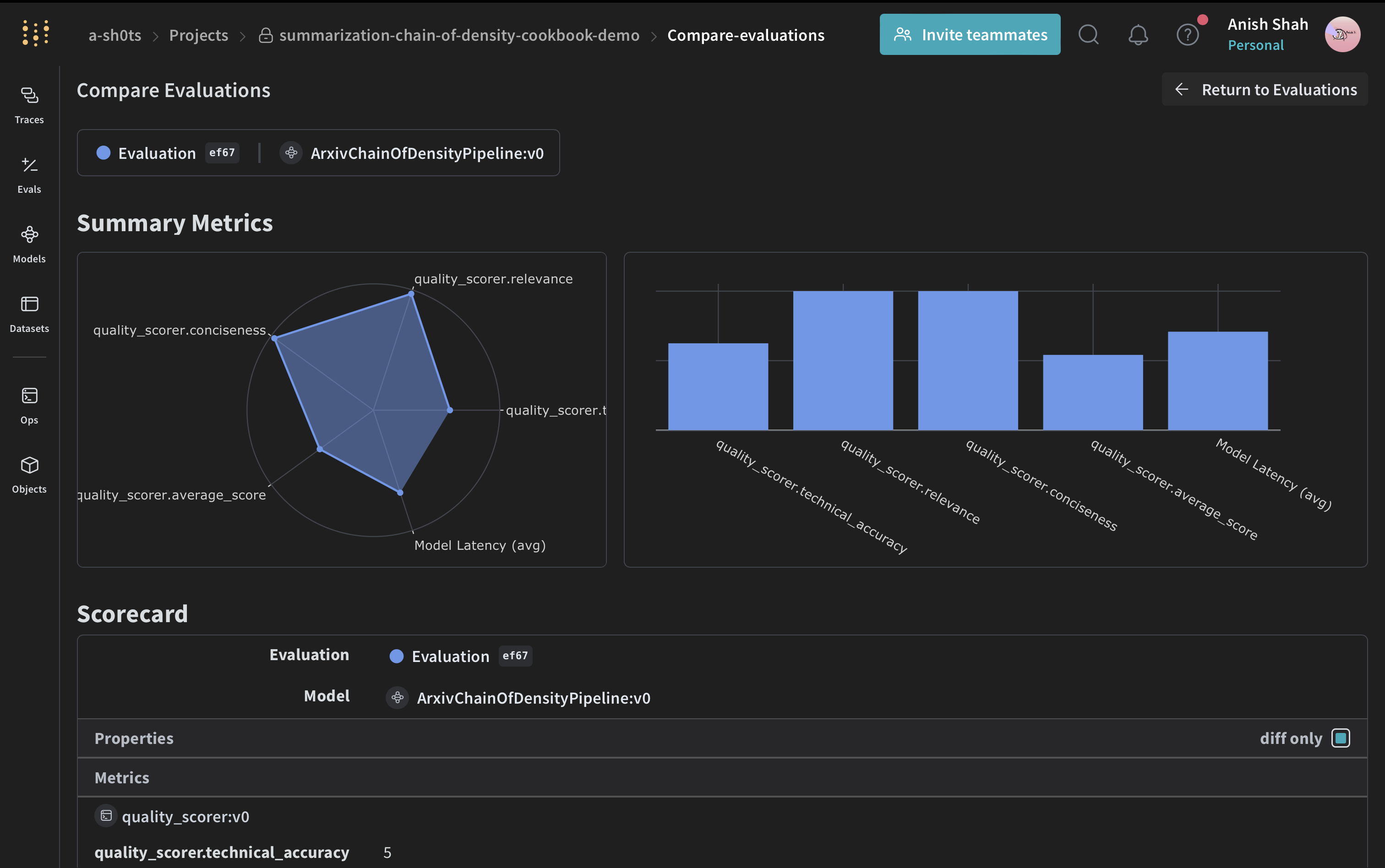
Implémenter des métriques d’évaluation
Créer un dataset Weave et lancer l’évaluation
Conclusion
- Créer des opérations Weave pour chaque étape du processus de synthèse
- Encapsuler le pipeline dans un modèle Weave pour le suivi et l’évaluation
- Mettre en œuvre des métriques d’évaluation personnalisées à l’aide des opérations Weave
- Créer un dataset et exécuter une évaluation du pipeline