Il s’agit d’un notebook interactif. Vous pouvez l’exécuter en local ou utiliser les liens suivants : Installer les dépendances
- DSPy pour construire et optimiser le flux de travail LLM.
- Weave pour suivre le flux de travail LLM et évaluer les stratégies de prompting.
- datasets pour accéder au jeu de données BIG-Bench Hard depuis le Hub Hugging Face.
Puisque ce tutoriel utilise l’API OpenAI comme fournisseur de LLM, vous aurez également besoin d’une clé API OpenAI. Vous pouvez vous inscrire sur la plateforme OpenAI pour obtenir votre propre clé API.
Activer le suivi avec Weave
weave.init au début de votre code permet de tracer automatiquement vos fonctions DSPy, que vous pouvez ensuite explorer dans l’interface Weave. Pour plus d’informations, voir la documentation de l’intégration Weave pour DSPy.
Ce tutoriel utilise une classe de métadonnées qui hérite de weave.Object pour gérer les métadonnées.
Gestion des versions des objets : les objets Metadata font automatiquement l’objet d’une gestion des versions et sont tracés lorsque les fonctions qui les utilisent sont elles-mêmes tracées.
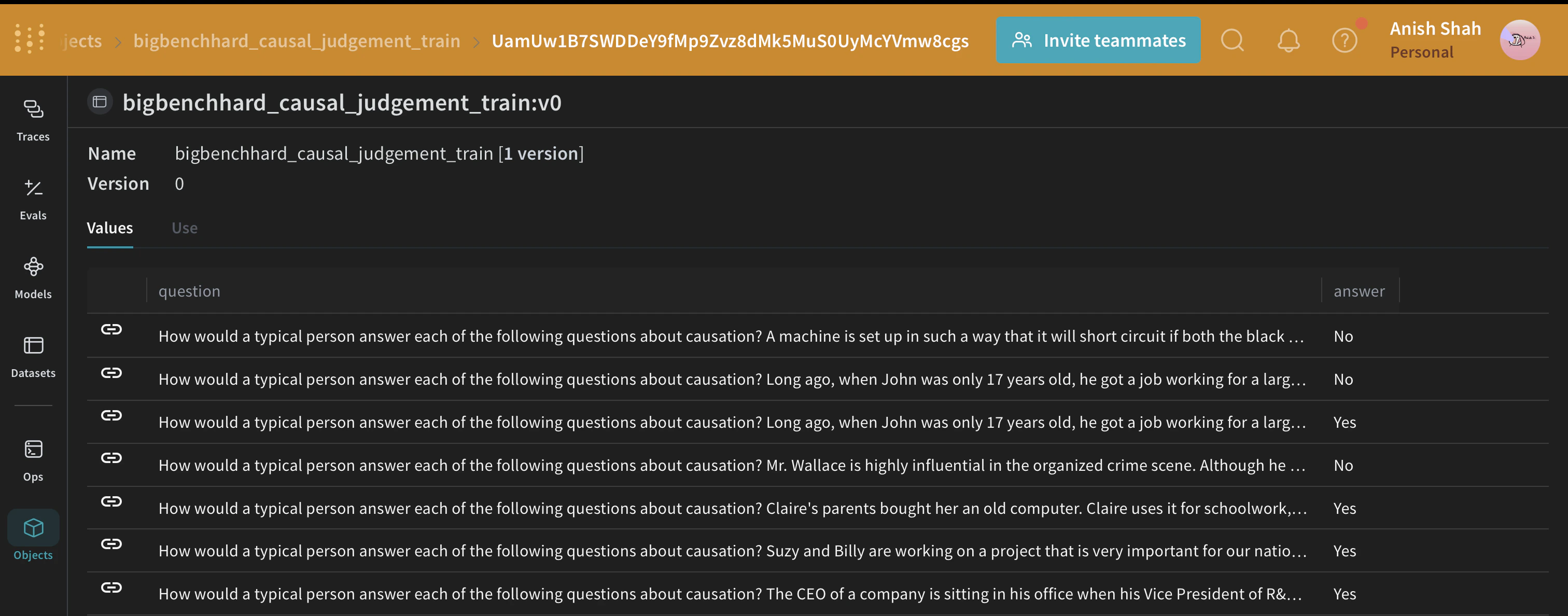
Charger le jeu de données BIG-Bench Hard
weave.Evaluation pour évaluer votre stratégie de prompting.
Une fois le jeu de données publié vers Weave, vous pouvez désormais définir le programme DSPy de référence que vous évaluerez et optimiserez par la suite.
DSPy est un framework qui déplace la création de nouveaux pipelines de LM de la manipulation de chaînes de texte libres vers la programmation (en composant des opérateurs modulaires pour construire des graphes de transformation de texte), où un compilateur génère automatiquement, à partir d’un programme, des stratégies d’invocation de LM et des prompts optimisés.
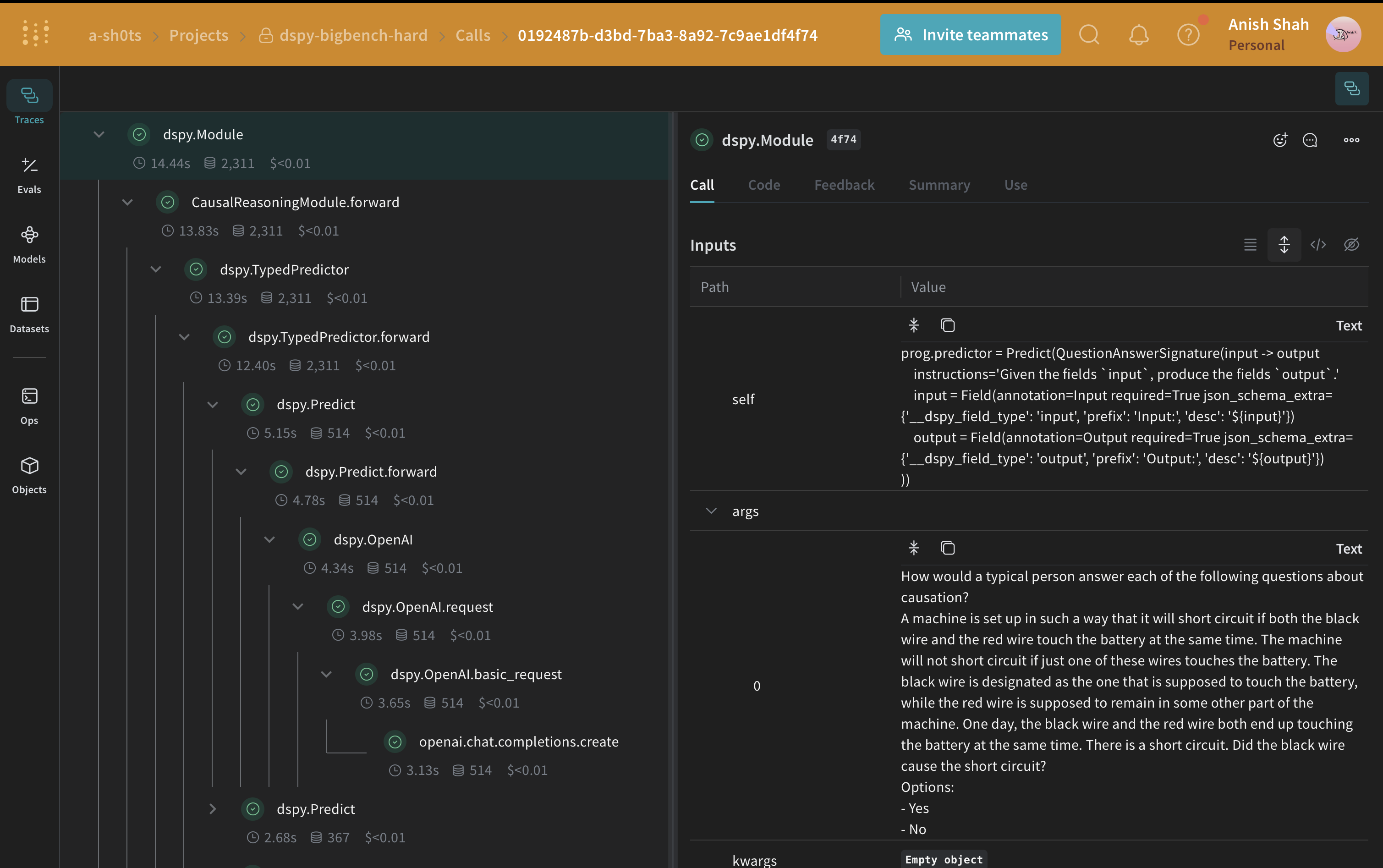
Utilisez dspy.LM pour configurer le modèle de langage et dspy.configure pour le définir comme valeur par défaut.
Écrire la signature du raisonnement causal
CausalReasoningModule, sur un exemple tiré du sous-ensemble de raisonnement causal de BIG-Bench Hard.
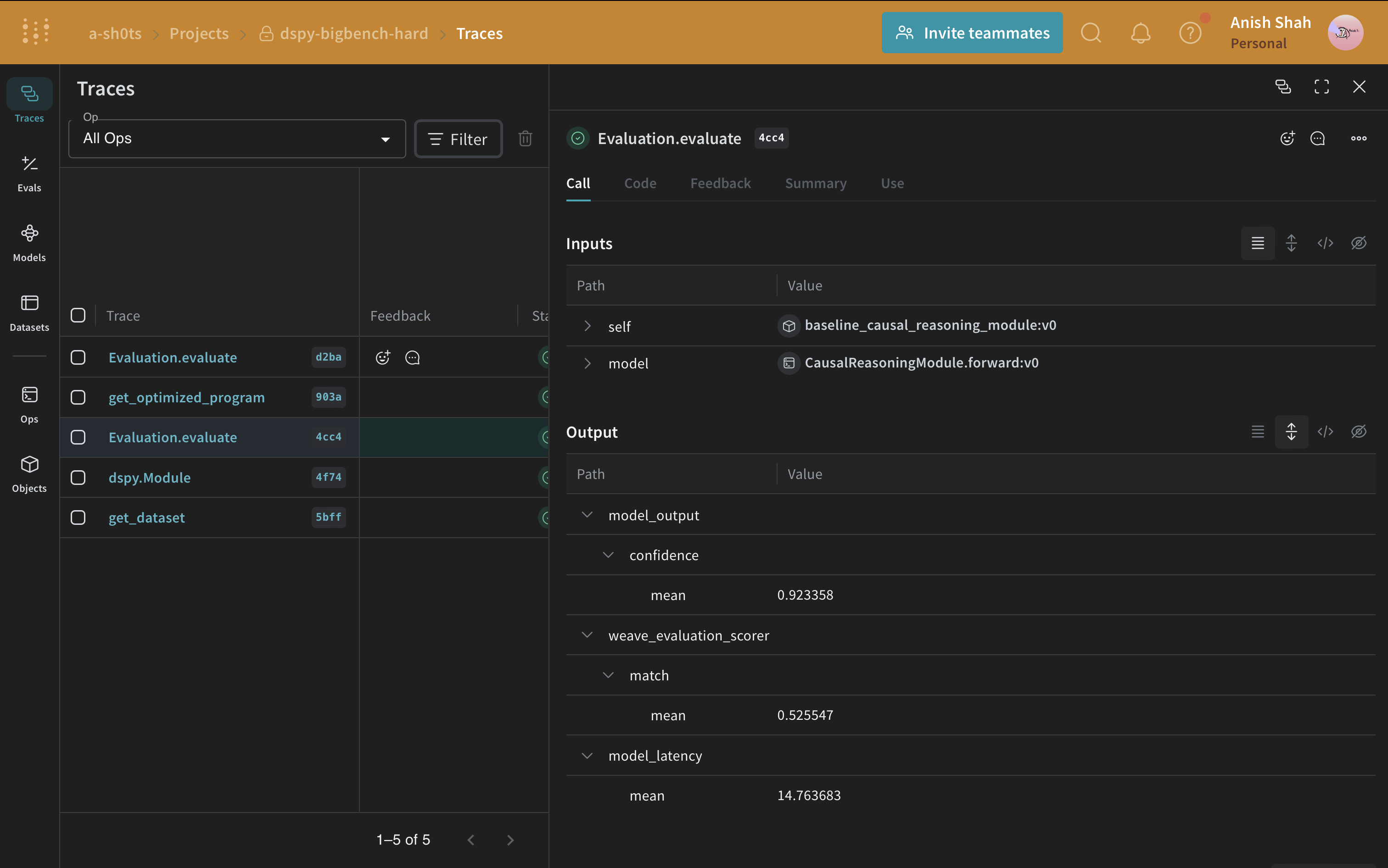
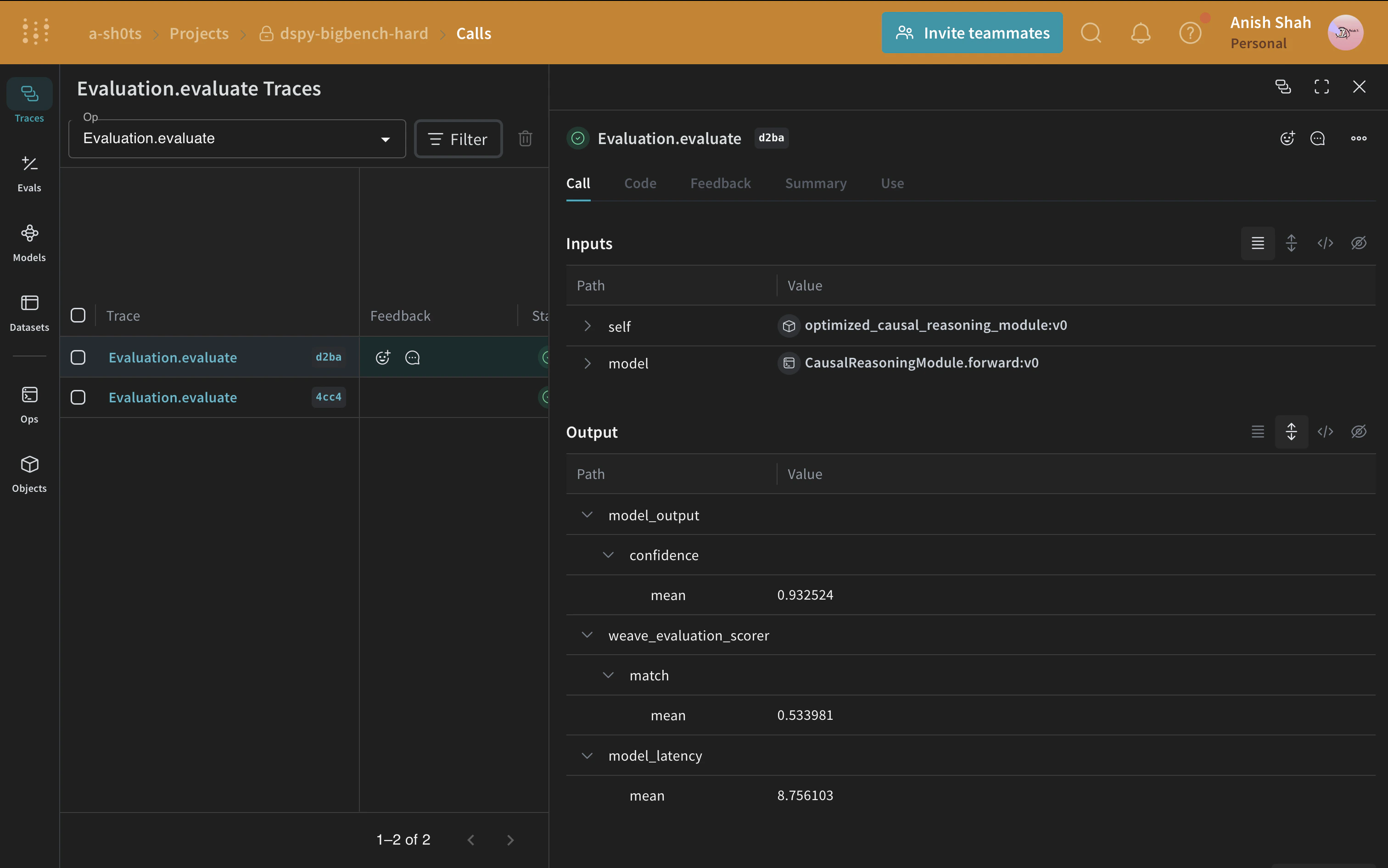
Évaluez le programme DSPy
weave.Evaluation, avec une métrique qui compare la réponse prédite à la réponse de référence. Weave prend chaque exemple, le fait passer dans votre application et attribue un score à la sortie à l’aide de plusieurs fonctions de score personnalisées. Cela vous donne une vue des performances de votre application, ainsi qu’une UI riche pour examiner en détail chaque sortie et son score.
Créez d’abord une fonction de score qui détermine si la réponse prédite correspond à la réponse de référence. Les fonctions de score Weave reçoivent la valeur de retour du modèle sous la forme de output, ainsi que toutes les clés correspondantes de l’exemple du jeu de données en arguments supplémentaires. Ici, answer provient du jeu de données et output est le dictionnaire renvoyé par CausalReasoningModule.forward.
Ensuite, encapsulez le module dans une fonction tracée que weave.Evaluation peut appeler. Les noms des arguments de cette fonction d’encapsulation doivent correspondre aux noms des colonnes du jeu de données utilisées en entrée par le modèle.
Nous pouvons maintenant définir l’évaluation et l’exécuter.
Si vous exécutez ce code depuis un script Python, vous pouvez utiliser le code suivant pour lancer l’évaluation : Exécuter l’évaluation sur le jeu de données de raisonnement causal coûte environ 0,24 $ en crédits OpenAI.
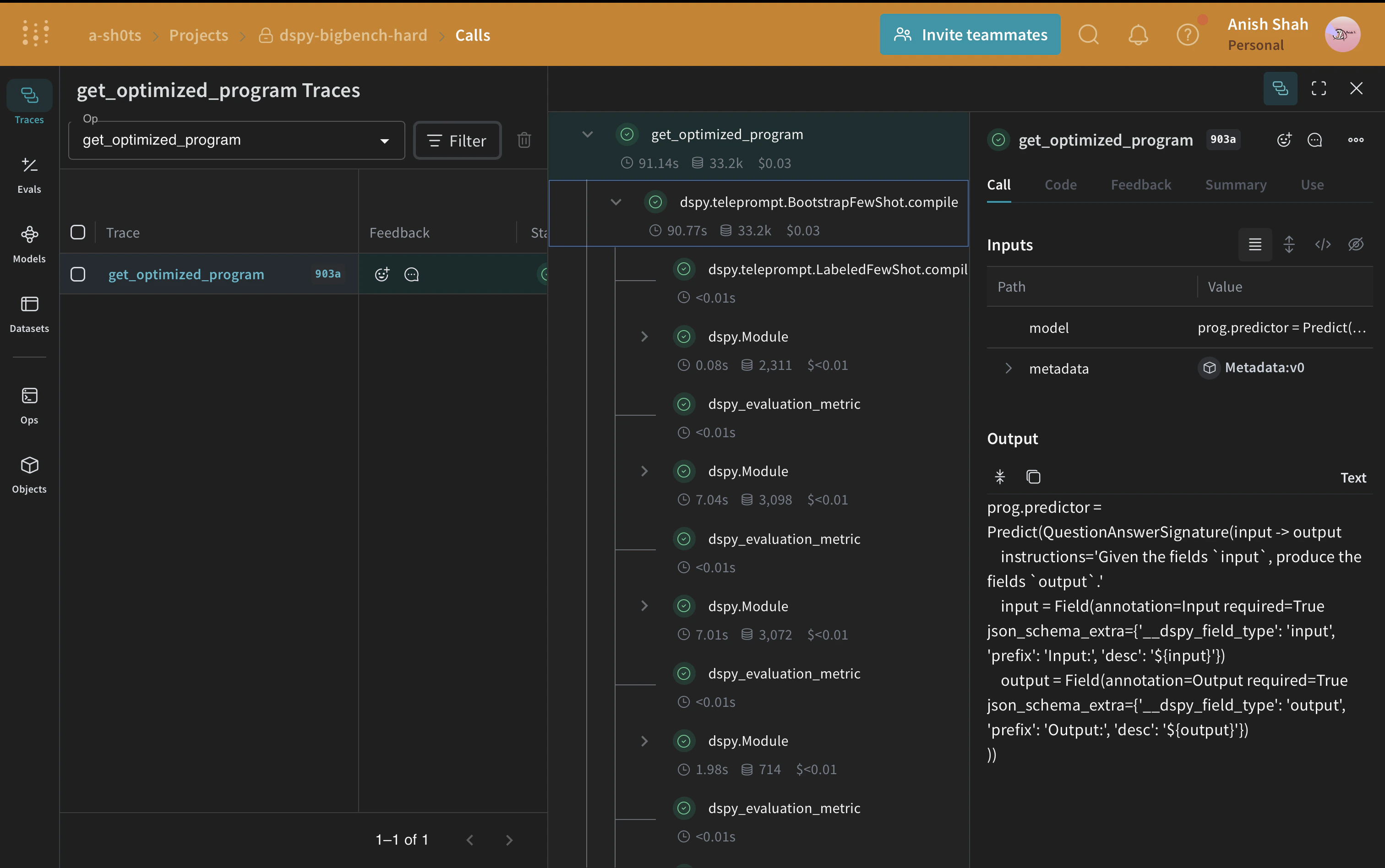
Optimiser le programme DSPy
L’exécution de l’évaluation sur le jeu de données de raisonnement causal coûte environ 0,04 $ en crédits OpenAI.