Dataset et interagir avec eux par programmation ou via l’interface utilisateur.
Cette page s’adresse aux ingénieurs et aux membres de l’équipe qui souhaitent gérer les données d’évaluation dans le code ou via l’interface Weave. Elle décrit :
- Les opérations de base sur les
Dataseten Python et TypeScript, ainsi que la marche à suivre pour bien démarrer. - Comment créer un
Dataseten Python et TypeScript à partir d’objets tels que les appels Weave. - Les opérations disponibles sur un
Datasetdans l’interface utilisateur.
Démarrage rapide de Dataset
Dataset avec Python et TypeScript. Avec les SDK, vous pouvez :
- Créer un
Dataset - Publier le
Dataset - Récupérer le
Dataset - Accéder à un exemple spécifique du
Dataset
- Python
- TypeScript
Créer un dataset à partir d’autres objets
Dataset à partir de données que vous possédez déjà, comme des appels Weave enregistrés ou des données tabulaires existantes, afin que vous n’ayez pas à ressaisir manuellement les exemples.
- Python
- TypeScript
En Python, les Ensuite, utilisez la méthode
Dataset peuvent également être créés à partir d’objets Weave courants comme les appels, ainsi que d’objets Python comme les pandas.DataFrame. Cette fonctionnalité est utile si vous souhaitez créer un Dataset d’exemple à partir d’exemples précis.Call Weave
Pour créer unDataset à partir d’un ou de plusieurs appels Weave, récupérez le ou les objets call, puis ajoutez-les à une liste dans la méthode from_calls.DataFrame Pandas
Pour créer unDataset à partir d’un objet Pandas DataFrame, utilisez la méthode from_pandas. Pour reconvertir le Dataset, utilisez to_pandas.Hugging Face Datasets
Pour créer unDataset à partir d’un objet Hugging Face datasets.Dataset ou datasets.DatasetDict, assurez-vous d’abord que les dépendances nécessaires sont installées :from_hf. Si vous fournissez un DatasetDict avec plusieurs splits (comme train, test, validation), Weave utilise automatiquement le split train et émet un avertissement. Si le split train n’est pas présent, Weave lève une erreur. Vous pouvez aussi fournir directement un split spécifique (par exemple, hf_dataset_dict['test']).Pour reconvertir un weave.Dataset en Dataset Hugging Face, utilisez la méthode to_hf.Créer, modifier et supprimer un dataset dans l’interface utilisateur
Dataset dans l’interface utilisateur. La création de datasets dans l’interface utilisateur Weave vous permet, ainsi qu’aux membres non techniques de votre équipe, de créer et de gérer des datasets partageables contenant des exemples, des questions et d’autres données de test pour les agents, sans modifier le code.
Les procédures suivantes vous guident dans chacune de ces tâches dans l’interface utilisateur. Utilisez-les lorsque vous souhaitez gérer les données d’évaluation avec les traces dont elles sont issues, plutôt qu’à partir d’un notebook ou d’un script.
Créer un nouveau dataset
Dataset à partir d’un ou de plusieurs appels existants dans votre projet Weave. Une fois l’opération terminée, vous disposez d’un Dataset publié que vous pouvez référencer dans des évaluations et partager avec votre équipe.
- Accédez au projet Weave que vous souhaitez modifier.
- Dans la barre latérale, sélectionnez Traces.
-
Sélectionnez un ou plusieurs appel pour lesquels vous souhaitez créer un nouveau
Dataset. - Dans le menu en haut à droite, cliquez sur l’icône Ajouter les lignes sélectionnées à un dataset (située à côté de l’icône de corbeille).
- Dans la liste déroulante Choisir un dataset, sélectionnez Créer nouveau. Le champ Nom du dataset s’affiche.
-
Dans le champ Nom du dataset, saisissez un nom pour votre jeu de données. Les options Configurer les champs du dataset s’affichent.
Les noms de dataset doivent commencer par une lettre ou un chiffre et ne peuvent contenir que des lettres, des chiffres, des traits d’union et des traits de soulignement.
-
(Facultatif) Dans Configurer les champs du dataset, sélectionnez les champs de vos appel à inclure dans le dataset.
- Vous pouvez personnaliser les noms de colonnes pour chaque champ sélectionné.
- Vous pouvez sélectionner un sous-ensemble de champs à inclure dans le nouveau
Dataset, ou désélectionner tous les champs.
-
Une fois les champs du dataset configurés, cliquez sur Suivant. Un aperçu de votre nouveau
Datasets’affiche. - (Facultatif) Cliquez sur l’un des champs modifiables de votre Dataset pour modifier l’entrée.
- Cliquez sur Créer le dataset. Weave crée votre nouveau jeu de données.
-
Dans la fenêtre contextuelle de confirmation, cliquez sur Voir le dataset pour afficher le nouveau
Dataset. Vous pouvez aussi accéder à l’onglet Datasets.
Modifier un dataset
Dataset existant et publier une nouvelle version. La modification dans l’interface utilisateur est utile lorsque vous souhaitez étendre ou corriger des données d’évaluation sans modifier le code.
-
Accédez au projet Weave contenant le
Datasetque vous souhaitez modifier. -
Dans la barre latérale, sélectionnez Datasets. Les
Datasets disponibles s’affichent.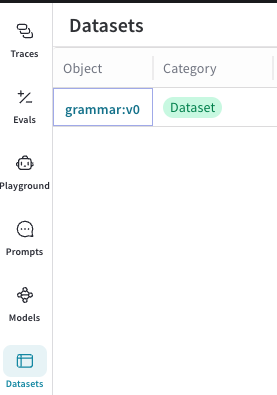
-
Dans la colonne Object, cliquez sur le nom et la version du
Datasetque vous souhaitez modifier. Une fenêtre modale détachable s’ouvre et affiche des informations sur leDataset, notamment son nom, sa version, son auteur et ses lignes.
-
Dans l’angle supérieur droit de la fenêtre modale, cliquez sur le bouton Edit dataset (l’icône en forme de crayon). Un bouton + Add row s’affiche en bas de la fenêtre modale.

-
Cliquez sur + Add row. Une nouvelle ligne s’affiche au-dessus des lignes existantes de votre
Dataset, indiquant que vous pouvez y ajouter une nouvelle ligne.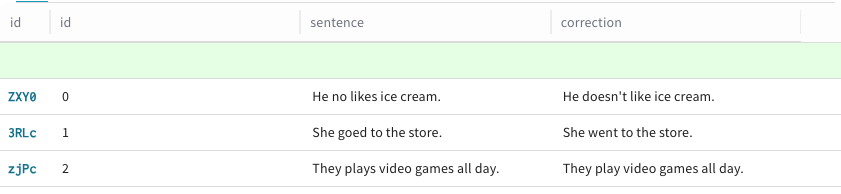
-
Pour ajouter des données à une nouvelle ligne, cliquez sur la colonne souhaitée dans cette ligne. Vous ne pouvez pas modifier la colonne id par défaut d’une ligne de
Dataset, car Weave l’attribue automatiquement lors de la création. Une fenêtre modale d’édition s’affiche avec les options Text, Code et Diff pour la mise en forme.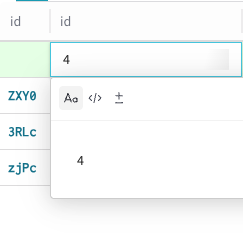
-
Répétez l’étape 6 pour chaque colonne de la nouvelle ligne à laquelle vous souhaitez ajouter des données.
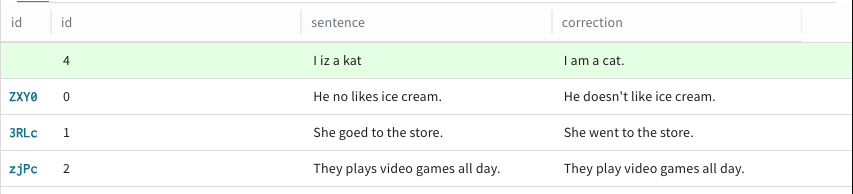
-
Répétez l’étape 5 pour chaque ligne que vous souhaitez ajouter au
Dataset. -
Une fois vos modifications terminées, publiez votre
Dataseten cliquant sur Publish dans l’angle supérieur droit de la fenêtre modale. Si vous ne souhaitez pas publier vos modifications, cliquez sur Cancel.
Dataset, avec les lignes mises à jour, est disponible dans l’UI.

Supprimer un dataset
Dataset dont vous n’avez plus besoin.
-
Accédez au projet Weave contenant le
Datasetque vous souhaitez modifier. -
Dans la barre latérale, sélectionnez Datasets. Les
Datasets disponibles s’affichent. -
Dans la colonne Object, cliquez sur le nom et la version du
Datasetque vous souhaitez supprimer. Une fenêtre modale détachable s’ouvre et affiche des informations sur leDataset, comme son nom, sa version, son auteur et ses lignes. -
Dans l’angle supérieur droit de la fenêtre modale, cliquez sur l’icône de corbeille.
Une fenêtre modale s’affiche pour vous demander de confirmer la suppression du
Dataset.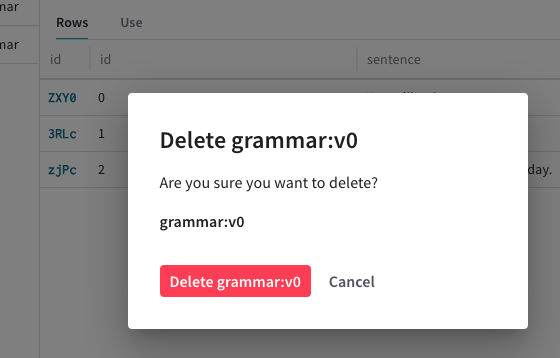
-
Dans la fenêtre modale, cliquez sur Supprimer pour supprimer le
Dataset. Vous pouvez également cliquer sur Annuler si vous ne souhaitez pas supprimer leDataset. LeDatasetest supprimé et n’est plus visible dans l’onglet Datasets de votre tableau de bord Weave.
Ajouter une nouvelle trace d’agent à un dataset
Dataset, voir Ajouter des messages d’agent à un dataset.
Ajouter une nouvelle trace à un dataset
Dataset des traces générées à partir d’opérations et d’Appels (à l’aide du décorateur @weave.op) :
- Accédez au projet Weave que vous souhaitez modifier.
- Dans la barre latérale, sélectionnez Traces.
-
Sélectionnez un ou plusieurs Appels avec
Datasetspour lesquels vous souhaitez créer de nouveaux exemples. - Dans le menu en haut à droite, cliquez sur l’icône Ajouter les lignes sélectionnées à un dataset (située à côté de l’icône de corbeille). Si vous le souhaitez, désactivez Show latest versions pour afficher toutes les versions de tous les jeux de données disponibles.
-
Dans le menu déroulant Choisir un dataset, sélectionnez le
Datasetauquel vous souhaitez ajouter des exemples. Les options Configure field mapping s’affichent. - Facultatif : dans Configure field mapping, vous pouvez ajuster le mappage des champs de vos Appels vers les colonnes correspondantes du jeu de données.
-
Une fois le mappage des champs configuré, cliquez sur Next. Un aperçu de votre nouveau
Datasets’affiche. - Dans la ligne vide (verte), ajoutez les valeurs de votre nouvel exemple. Le champ id n’est pas modifiable et Weave le crée automatiquement.
- Cliquez sur Add to dataset. Pour revenir à l’écran Configure field mapping, cliquez sur Back.
-
Dans la fenêtre contextuelle de confirmation, cliquez sur Voir le dataset pour voir les modifications. Vous pouvez aussi accéder à l’onglet Datasets pour voir les mises à jour apportées à votre
Dataset.
Autres opérations sur les datasets
Dataset.
- Python
- TypeScript
Sélection de lignes
Vous pouvez sélectionner des lignes spécifiques d’unDataset par leur index à l’aide de la méthode select. C’est utile pour créer des sous-ensembles de vos données, par exemple lorsque vous souhaitez évaluer sur un sous-ensemble plus restreint d’exemples.