EvaluationLogger pour enregistrer des prédictions et des scores depuis votre code Python ou TypeScript existant, afin d’évaluer les performances du modèle dans Weave sans devoir d’abord définir un Dataset complet et une suite d’évaluateurs.
Cette approche est utile dans les flux de travail complexes où l’ensemble du jeu de données ou tous les évaluateurs ne sont pas forcément définis à l’avance.
Contrairement à l’objet Evaluation standard, qui nécessite un Dataset prédéfini et une liste d’objets Scorer, EvaluationLogger vous permet de journaliser des prédictions individuelles et les scores associés de façon incrémentielle, à mesure qu’ils deviennent disponibles.
Vous préférez une évaluation plus structurée ?Si vous préférez un framework d’évaluation plus prescriptif avec des jeux de données et des évaluateurs prédéfinis, Voir le framework
Evaluation standard de Weave.EvaluationLogger offre de la flexibilité, tandis que le framework standard apporte structure et orientation.Flux de travail de base
- Initialisez le logger : Créez une instance de
EvaluationLogger, en fournissant éventuellement des métadonnées sur lemodèleet lejeu de données. Weave utilise les valeurs par défaut si vous les omettez.Pour capturer l’utilisation des jetons et le coût des appels LLM (par exemple, OpenAI), initialisezEvaluationLoggeravant toute invocation de LLM. Si vous appelez d’abord votre LLM, puis journalisez les prédictions ensuite, Weave ne capture pas les données de jeton et de coût. - Journalisez les prédictions : Appelez
log_prediction()pour chaque paire d’entrée et de sortie de votre système. - Journalisez les scores : Utilisez le
ScoreLoggerrenvoyé pour appelerlog_score()pour la prédiction. Plusieurs scores par prédiction sont pris en charge. - Terminez la prédiction : Appelez toujours
finish()après avoir journalisé les scores d’une prédiction afin de la finaliser. - Journalisez la synthèse : Une fois toutes les prédictions traitées, appelez
log_summary()pour agréger les scores et ajouter des métriques personnalisées facultatives.
log_example().
Exemple de base
EvaluationLogger pour journaliser les prédictions et les scores directement dans votre code existant.
- Python
- TypeScript
La fonction de modèle
user_model est définie puis appliquée à une liste d’entrées. Pour chaque exemple :- L’entrée et la sortie sont enregistrées à l’aide de
log_prediction. - Un score de correction (
correctness_score) est enregistré vialog_score. finish()finalise l’enregistrement pour cette prédiction.
log_summary enregistre les métriques agrégées et déclenche la synthèse automatique des scores dans Weave.Journalisation simplifiée avec log_example()
log_example() pour journaliser des entrées, une sortie et des scores en un seul appel. Cette méthode pratique combine log_prediction(), log_score() et finish() en une seule étape. Elle est utile lorsque vous disposez déjà des entrées, des sorties du modèle et des scores à journaliser, par exemple lors d’évaluations par lot ou hors ligne.
log_example() équivaut à :
log_example() n’est pas disponible pour le SDK TypeScript de Weave. Les utilisateurs de TypeScript doivent utiliser l’approche logPrediction() et logScore() présentée dans l’exemple de base.Utilisation avancée
EvaluationLogger offre des modes d’utilisation flexibles au-delà du flux de travail de base pour répondre à des scénarios d’évaluation plus complexes. Les sections suivantes décrivent des techniques avancées, notamment comment utiliser des gestionnaires de contexte pour la gestion automatique des ressources, séparer l’exécution du modèle de la journalisation, utiliser des données de médias enrichis et comparer côte à côte plusieurs évaluations de modèles.
Utiliser des gestionnaires de contexte
EvaluationLogger prend en charge les gestionnaires de contexte (instructions with) pour les prédictions comme pour les scores. Cela permet d’obtenir un code plus propre, un nettoyage automatique des ressources et un meilleur suivi des opérations imbriquées, comme les appels à un juge LLM.
L’utilisation des instructions with dans ce contexte offre les avantages suivants :
- Appels automatiques à
finish()à la sortie du contexte. - Meilleur suivi des jetons et des coûts pour les appels LLM imbriqués.
- Définition de la sortie après l’exécution du modèle dans le contexte de prédiction.
- Python
- TypeScript
Lier à un jeu de données existant
inputs à log_prediction, Weave réimporte les données à chaque run d’évaluation. Cela stocke des données en double, ce qui peut gaspiller de l’espace si le jeu de données est volumineux ou si de nombreuses évaluations le réutilisent.
Pour éviter cette duplication, publiez votre jeu de données vers Weave avant d’exécuter des évaluations, puis passez les lignes du jeu de données publié comme inputs. Weave résout les références aux lignes publiées à l’aide de références internes au lieu de réimporter les données. Cette technique vous offre la même expérience de liaison que le framework Evaluation standard, où chaque prédiction renvoie à une ligne précise du jeu de données dans l’interface Weave.
L’exemple suivant publie un jeu de données et y crée un lien dans EvaluationLogger, avant de le récupérer et de le parcourir comme n’importe quel autre jeu de données.
- Python
- TypeScript
Obtenir les sorties avant la journalisation
- Python
- TypeScript
Journaliser des médias enrichis
log_prediction ou log_score.
- Python
- TypeScript
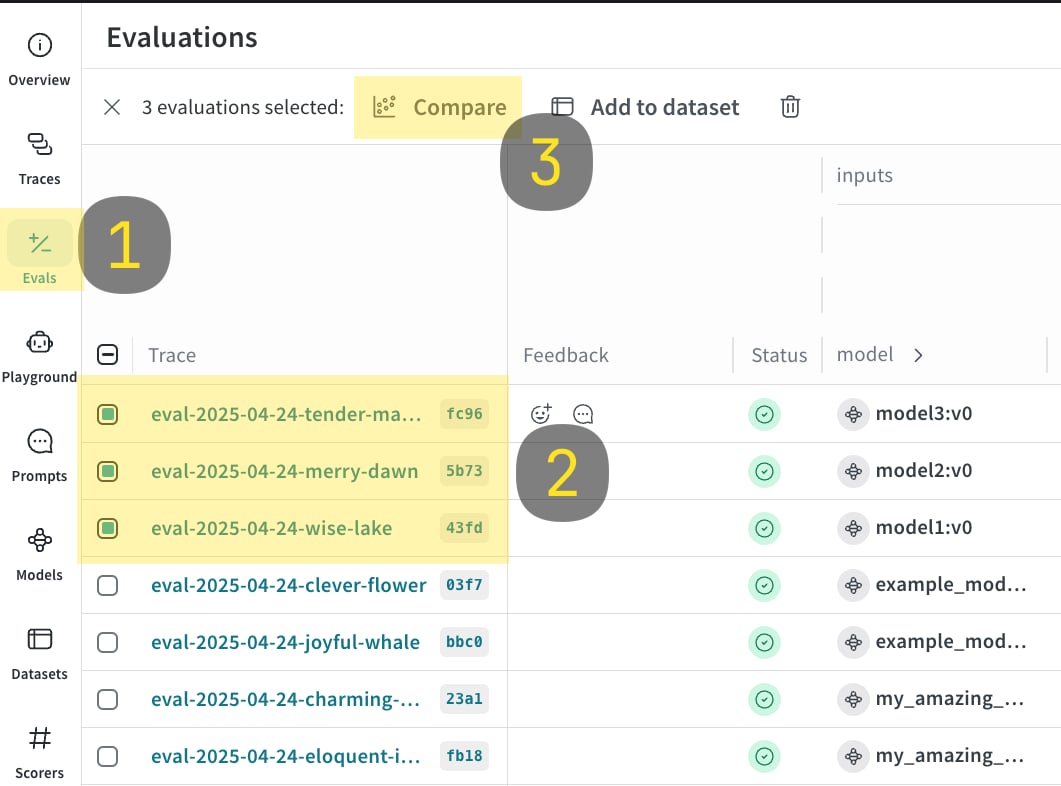
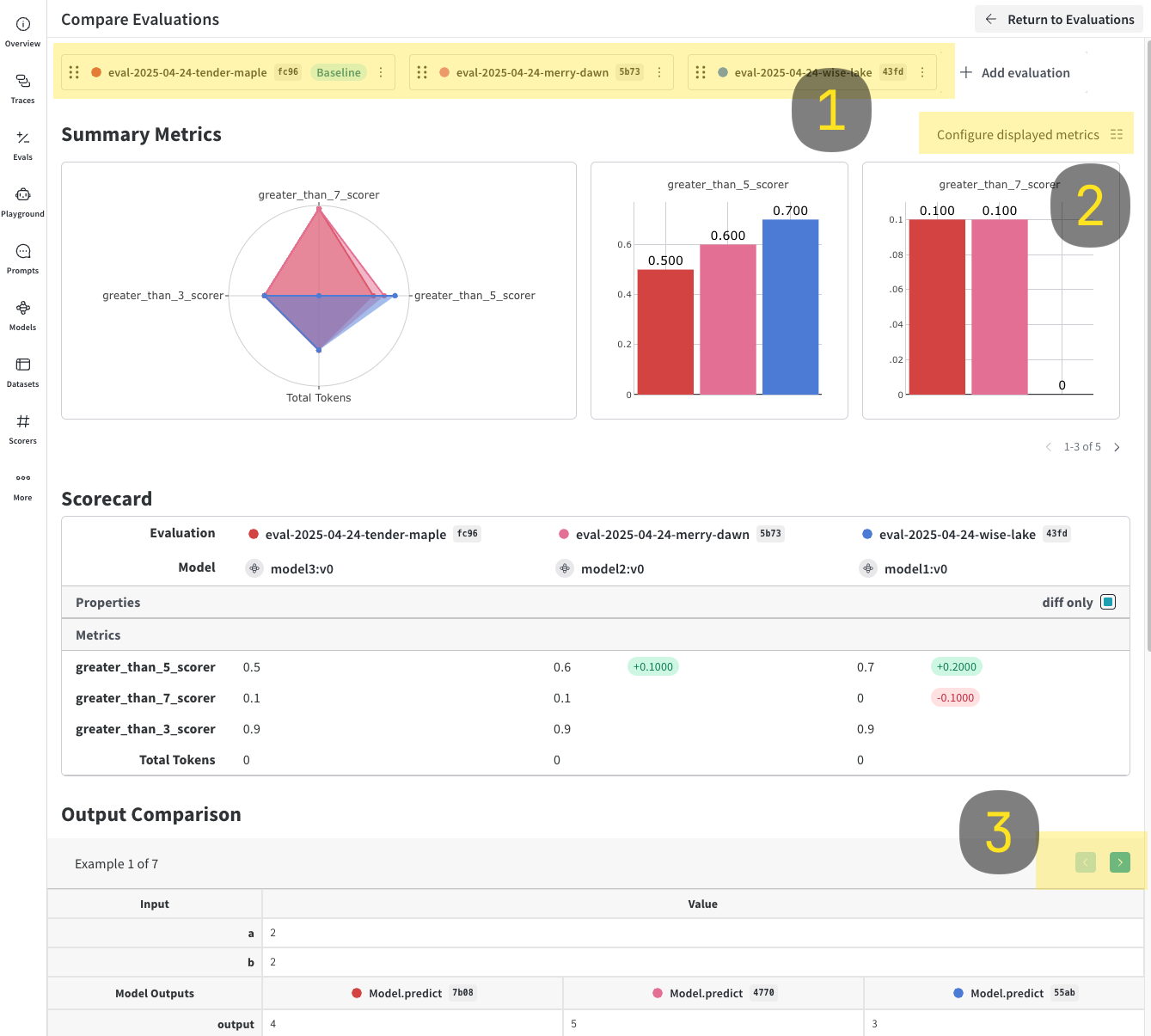
Journaliser et comparer plusieurs évaluations
EvaluationLogger, vous pouvez journaliser et comparer plusieurs évaluations côte à côte dans l’interface Weave. Cela est utile pour évaluer les performances de différents modèles sur le même jeu de données.
- Exécutez l’exemple de code suivant.
- Dans l’interface Weave, accédez à l’onglet
Evals. - Sélectionnez les evals que vous souhaitez comparer.
- Cliquez sur le bouton Compare. Dans la vue de comparaison, vous pouvez :
- Choisir quelles evals ajouter ou supprimer.
- Choisir quelles métriques afficher ou masquer.
- Parcourir des exemples précis pour voir comment différents modèles se sont comportés pour la même entrée dans un jeu de données donné.
- Python
- TypeScript
Conseils d’utilisation
EvaluationLogger :
- Python
- TypeScript
- Appelez
finish()rapidement après chaque prédiction. - Utilisez
log_summarypour enregistrer des métriques qui ne sont pas liées à une prédiction individuelle (par exemple, la latence globale). - La journalisation des médias enrichis est utile pour l’analyse qualitative.