- Suivre les régressions des performances du modèle.
- Coordonner des flux de travail d’évaluation partagés.
La création de leaderboards n’est possible que dans l’interface Weave et le SDK Python de Weave. Les utilisateurs de TypeScript peuvent créer et gérer des leaderboards à l’aide de l’interface Weave.
Créer un leaderboard
Utiliser l’UI
- Dans l’interface Weave, accédez à la section Leaders. Si elle n’est pas visible, cliquez sur More → Leaders.
- Cliquez sur + New Leaderboard.
- Dans le champ Leaderboard Title, saisissez un nom explicite (par exemple,
summarization-benchmark-v1). - Vous pouvez également ajouter une description pour préciser ce que ce leaderboard compare.
- Ajoutez des colonnes pour définir quelles évaluations et métriques afficher.
- Lorsque la mise en page est prête, enregistrez et publiez votre leaderboard pour le partager avec d’autres.
Ajouter des colonnes
- Évaluation: Sélectionnez un run d’évaluation dans la liste déroulante (il doit avoir été créé au préalable).
- Évaluateur: Choisissez une fonction de score (par exemple,
jaccard_similarityousimple_accuracy) utilisée dans cette évaluation. - Métrique: Choisissez une métrique de synthèse à afficher (par exemple,
meanoutrue_fraction).
- Déplacer avant ou après. Réordonner les colonnes.
- Dupliquer. Copier la définition de la colonne.
- Supprimer. Supprimer la colonne.
- Trier par ordre croissant. Définir l’ordre de tri par défaut du leaderboard (cliquez à nouveau pour basculer en ordre décroissant).
Utilisez le SDK Python
-
Définissez un jeu de données de test. Vous pouvez utiliser le
Datasetintégré ou définir manuellement une liste d’entrées et de cibles : -
Définissez un ou plusieurs évaluateurs :
-
Créez une
Evaluation: -
Définissez les modèles à évaluer :
-
Lancez l’évaluation :
-
Créez le leaderboard :
-
Publiez le leaderboard.
-
Récupérez les résultats :
Exemple Python de bout en bout
Consulter et interpréter le leaderboard
- Dans l’interface Weave, accédez à l’onglet Leaders. S’il n’est pas visible, cliquez sur More, puis sélectionnez Leaders.
- Cliquez sur le nom de votre leaderboard, par exemple
Summarization Model Comparison.
model_humanlike, model_vanilla, model_messy). La colonne mean indique la similarité de Jaccard moyenne entre la sortie du modèle et les résumés de référence.
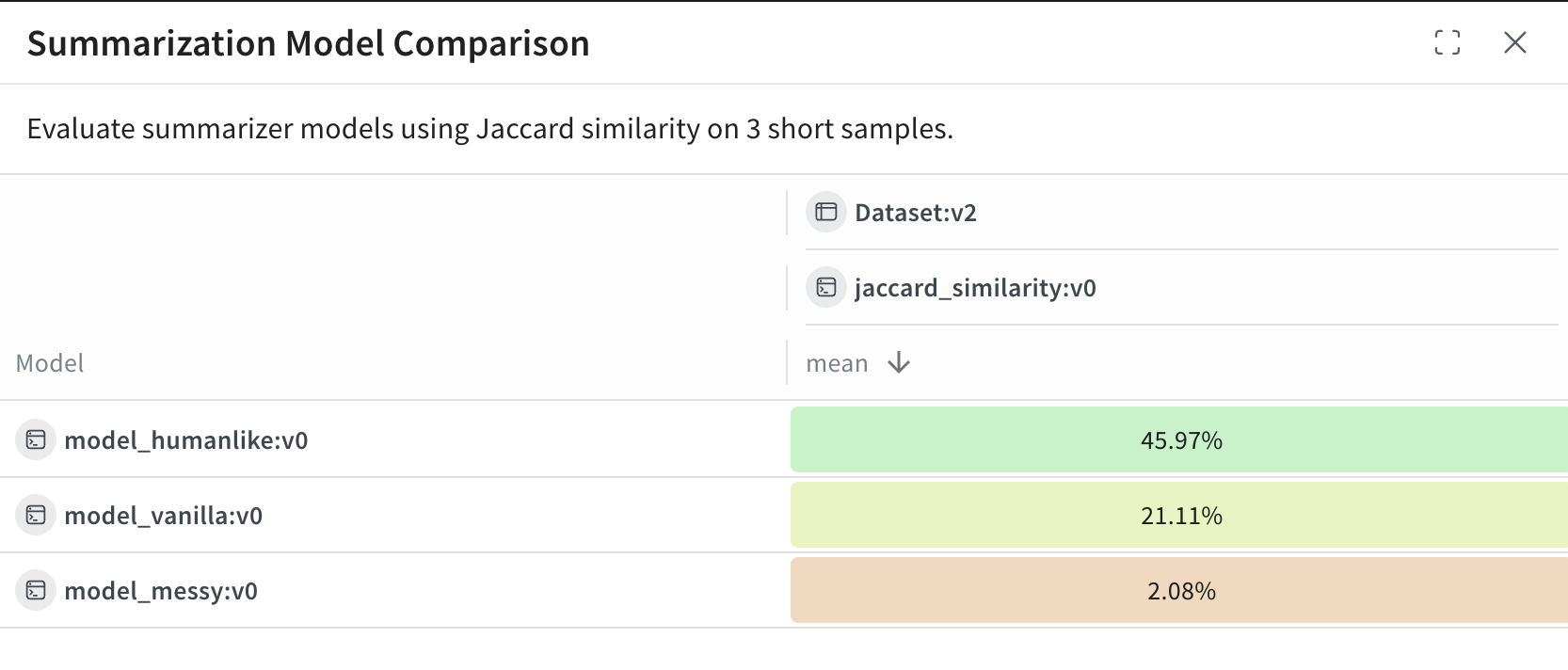
model_humanlikedonne les meilleurs résultats, avec environ 46 % de chevauchement.model_vanilla(une troncature naïve) atteint environ 21 %.model_messy, un modèle délibérément mauvais, obtient un score d’environ 2 %.