Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens suivants :
Importer des traces depuis des systèmes tiers
conversation_id comme identifiant du parent, et turn_index comme identifiant de l’enfant afin de disposer d’une journalisation complète des conversations.
Vous devez modifier les variables dans les sections suivantes pour qu’elles correspondent à votre propre jeu de données, à vos chemins de fichiers et à votre projet W&B.
Configurer l’environnement
WANDB_API_KEY dans votre environnement afin de pouvoir vous connecter avec wandb.login() (fournissez-la à Colab comme secret).
Définissez le nom du fichier que vous téléversez dans Colab dans name_of_file, et le projet W&B dans lequel vous souhaitez enregistrer dans name_of_wandb_project.
name_of_wandb_project peut aussi être au format [TEAM_NAME]/[PROJECT_NAME] pour indiquer l’équipe dans laquelle enregistrer les traces.weave.init().
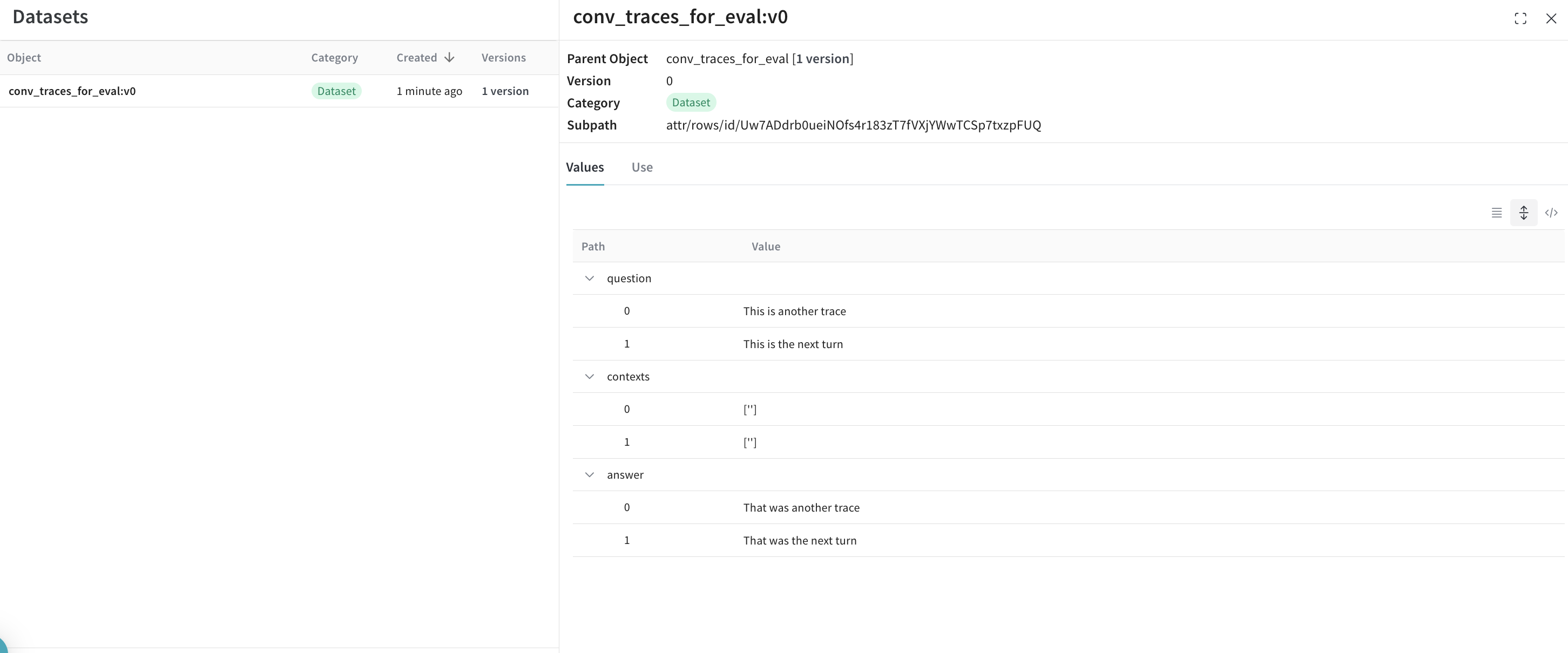
Charger les données
conversation_id et turn_index pour garantir que les éléments parents et enfants sont correctement ordonnés.
Vous obtenez ainsi un DataFrame pandas à deux colonnes, avec les tours de conversation regroupés dans un tableau sous conversation_data.
Enregistrer les traces dans Weave
- Créez un appel parent pour chaque
conversation_id. - Parcourez le tableau des tours de conversation pour créer des appels enfants triés selon leur
turn_index.
- Un appel Weave est équivalent à une trace Weave. Cet appel peut avoir un parent ou des enfants associés.
- Un appel Weave peut aussi avoir d’autres éléments associés, comme le feedback et les métadonnées. Cet exemple associe uniquement les
inputset l’output, mais vous pouvez ajouter ces autres éléments lors de l’importation si les données les fournissent. - Un appel Weave passe par les états
createdetfinished, car il est conçu pour être suivi en temps réel. Comme il s’agit ici d’une importation a posteriori, vous créez et terminez l’appel une fois que les objets sont définis et liés entre eux. - La valeur
opd’un appel indique comment Weave catégorise les appels de même type. Dans cet exemple, tous les appels parents sont de typeConversationet tous les appels enfants sont de typeTurn. Vous pouvez modifier cela comme bon vous semble. - Un appel peut avoir des
inputset unoutput. Lesinputssont définis lors de la création, et l’outputest défini lorsque l’appel est terminé.
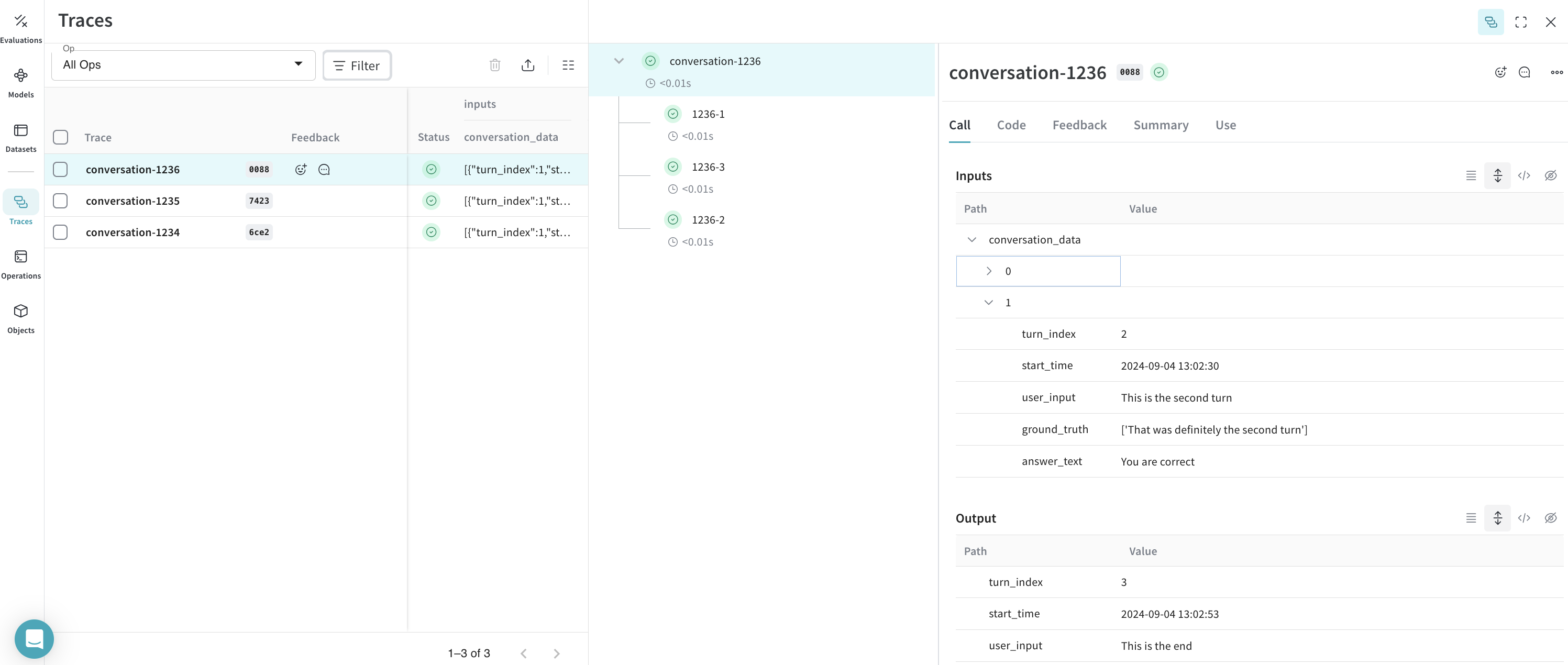
Résultat : traces enregistrées dans Weave
Conversation et Turn que vous avez définies.
Traces :
Facultatif : exportez vos traces pour lancer des évaluations
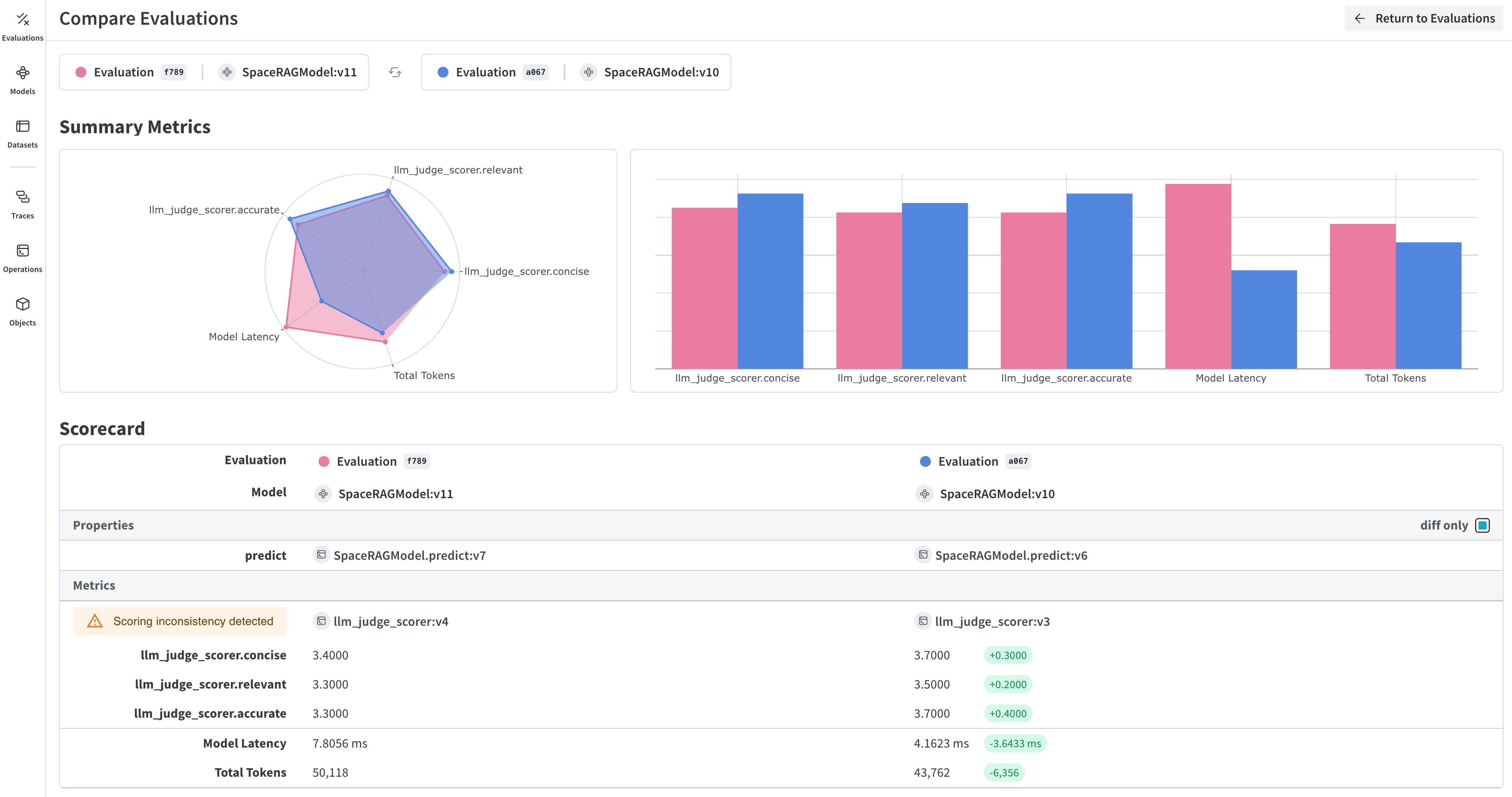
Résultat