フルフィデリティ
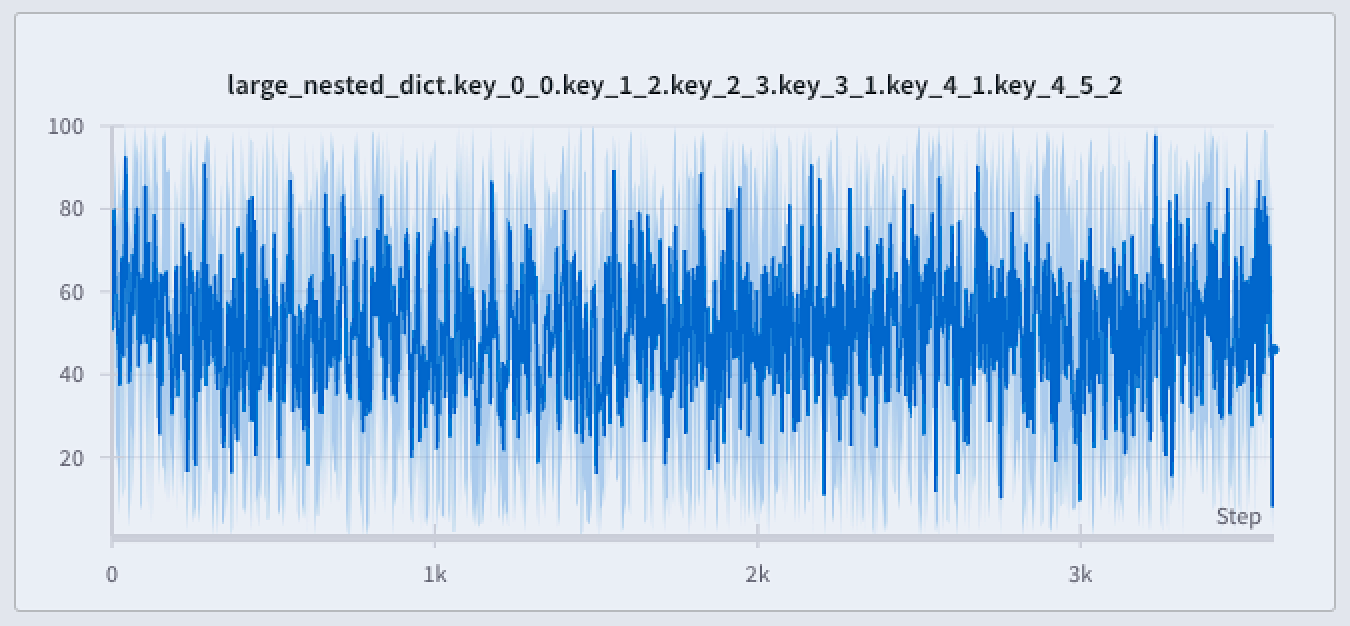
- 極端な値やスパイクを保持できる: データ内の極端な値やスパイクを保持します。
- 最小値と最大値の表示方法を設定できる: W&B App を使用して、極端な値 (最小値/最大値) を陰影付きの領域として表示するかどうかをインタラクティブに決定できます。
- データの忠実性を損なわずに探索できる: 特定のデータポイントにズームインすると、W&B は X 軸 のバケットサイズを再計算します。これにより、精度を損なうことなくデータを探索しやすくなります。W&B は以前に計算した集約結果をキャッシュして、読み込み時間の短縮に役立てます。これは、大規模なデータセット内を移動する場合に有用です。
フルフィデリティを有効にする
- Workspace 内のすべてのチャート
- Workspace 内の個別のチャート
- Workspace にアクセスします。
- 画面右上の Add panels ボタンの左にある歯車アイコンを選択します。
- 表示される UI のスライダーから 折れ線グラフ を選択します。
- ポイント集約 セクションで Full fidelity を選択します。
- Smoothing のアルゴリズムと設定を指定します。
- Aggregation を Mean、Min、または Max に設定します。
- Apply をクリックします。
陰影表示を設定する
- Min/Max: 各 X 軸ポイントについて、最小値と最大値の間の領域を陰影表示します。陰影表示領域には、各 バケット における最小値から最大値までのすべての点が表示されます。 ここで、x_1, x_2, \ldots, x_n は特定の バケット 内の値です。
- Standard deviation: 各 X 軸ポイントについて、標準偏差を使って値のばらつきを計算し、その範囲を陰影表示します。
- Standard error: 各 X 軸ポイントについて、値をサンプルサイズの平方根で割って標準誤差を計算し、その範囲を陰影表示します。
- None: 陰影表示なし (デフォルト) 。
- Workspace にアクセスします。
- 折れ線グラフにカーソルを合わせ、歯車アイコンをクリックします。
- Data タブで、必要に応じて ポイント集約 を Full fidelity に設定し、スムージングアルゴリズムを設定します。
- Grouping タブで、Group runs をオンにします。必要に応じて、Group by を run の属性に設定します。
- Agg を Mean (デフォルト) 、Min、または Max に設定します。
- Range を Min/Max、Std Dev、Std Err、または None に設定します。
- Apply をクリックします。
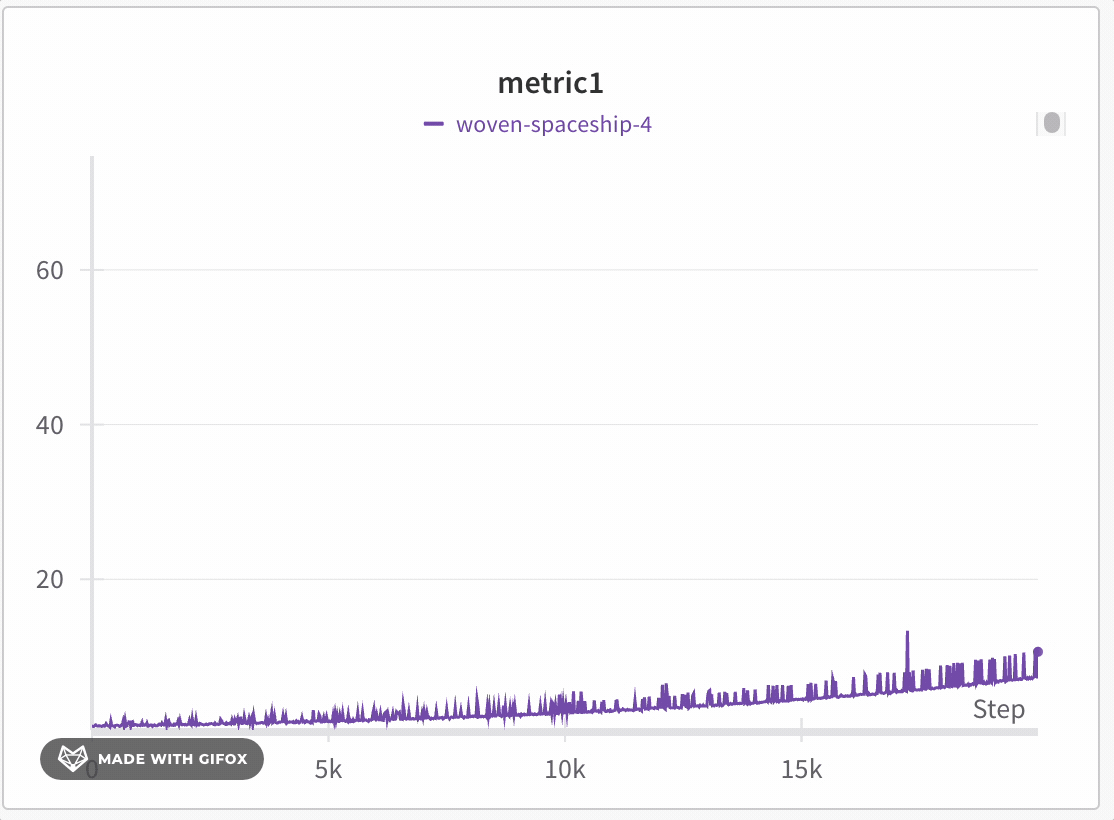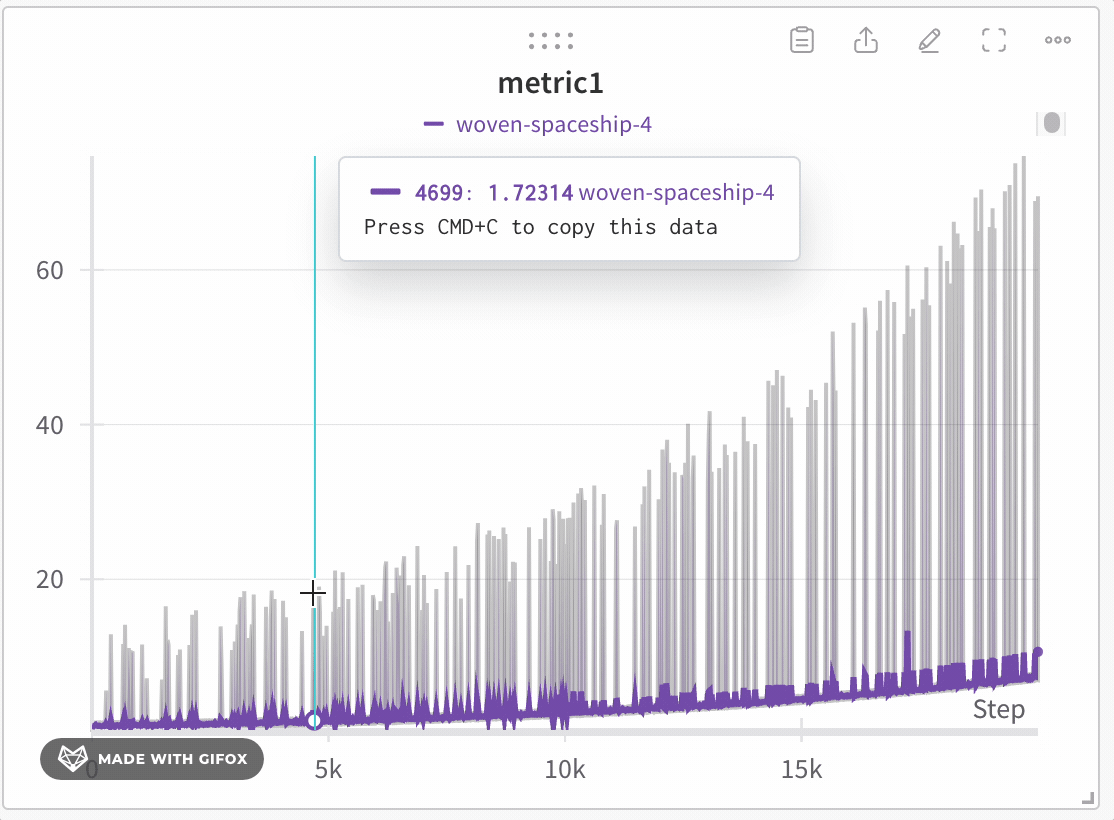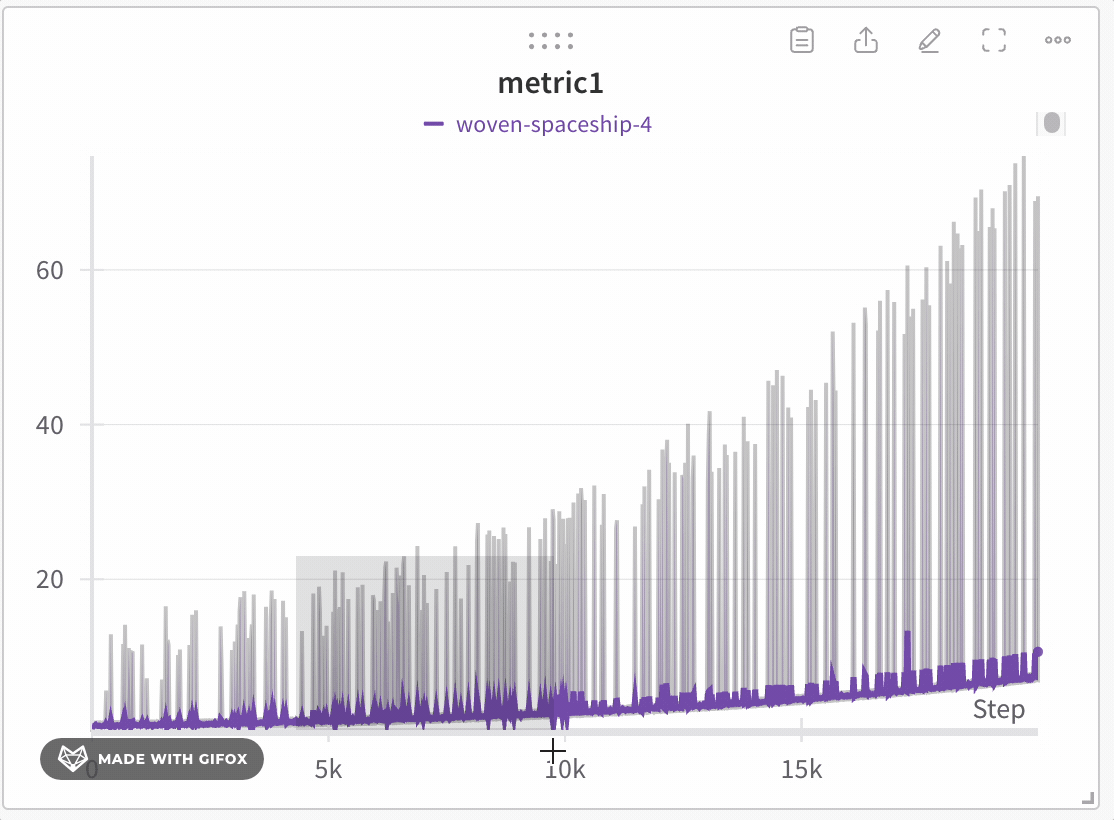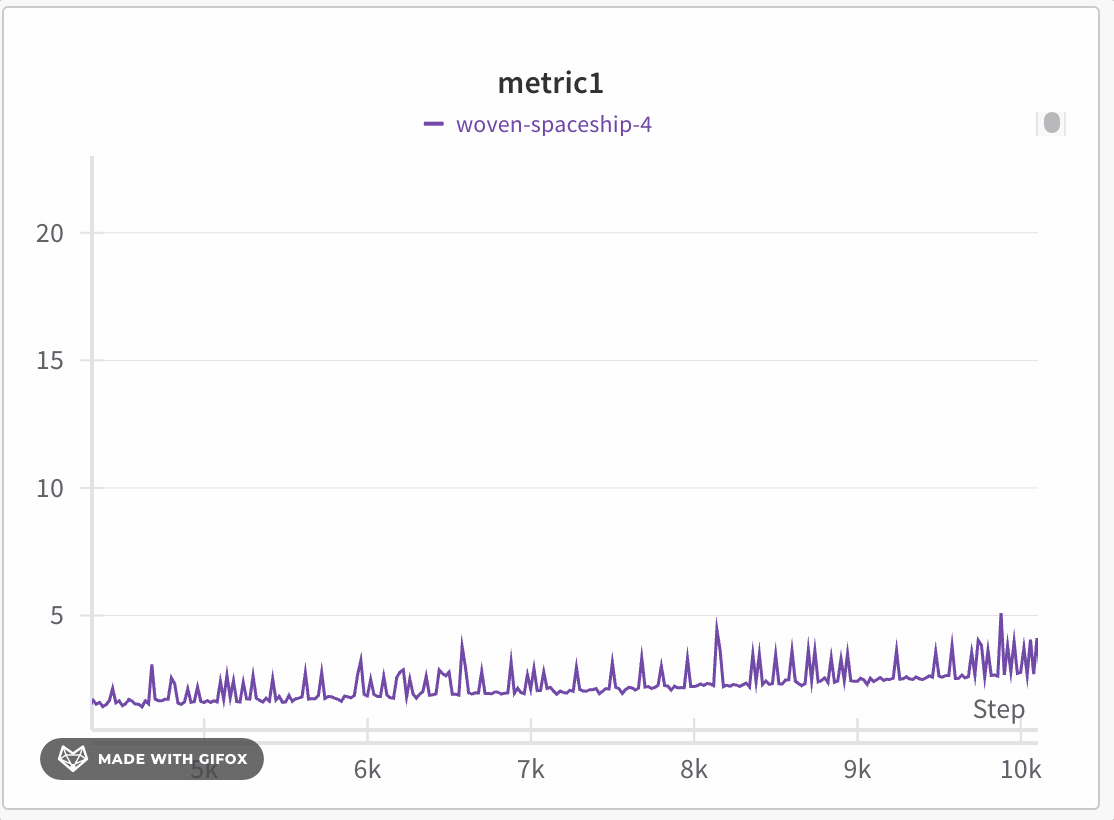
データの忠実性を保ったままデータを探索する
- 最小値: そのバケット内の最も低い値です (陰影表示に使用) 。
- 最大値: そのバケット内の最も高い値です (陰影表示に使用) 。
- 線の値: そのバケット内の最後の値で、線を描画するために使用されます。
- W&B のプロジェクトにアクセスする。
- 左側のタブにある Workspace アイコンを選択します。
- 必要に応じて Workspace にラインプロットパネルを追加するか、既存のラインプロットパネルにアクセスします。
- クリックしてドラッグし、ズームインしたい特定の領域を選択します。
Line Plot Grouping と式Line Plot Grouping を使用すると、W&B は選択したモードに応じて次を適用します。
- 非ウィンドウ サンプリング (grouping) : x軸 上で run 間の点を揃えます。複数の点が同じ x 値を共有する場合は平均が取られ、そうでない場合は個別の点として表示されます。
- ウィンドウ サンプリング (grouping と式) : x軸 を 250 個のバケット、または最も長い線の点数のいずれか小さい方に分割します。W&B は各バケット内の点の平均を取ります。
- フルフィデリティ (grouping と式) : 非ウィンドウ サンプリングと似ていますが、パフォーマンスと詳細度のバランスを取るため、run ごとに最大 500 点まで取得します。
ランダムサンプリング
ランダムサンプリングを有効にする
- Workspace 内のすべてのチャート
- Workspace 内の個別のチャート
- W&B のプロジェクトにアクセスする。
- 左側のタブで Workspace アイコンを選択します。
- 画面右上で、Add panels ボタンの左隣にある歯車アイコンを選択します。
- 表示される UI スライダーで 折れ線グラフ を選択します。
- ポイント集約 セクションで ランダムサンプリング を選択します。