사용자의 W&B 설치 방식을 결정합니다
wandb)를 임포트하는 방식, 설치 관련 문서를 작성하는 방식, 그리고 wandb가 없는 환경을 처리하는 방식에 영향을 줍니다.
W&B를 필수 의존성으로 지정하기
wandb가 자동으로 설치되도록 의존성에 추가하세요:
설치 시 W&B를 선택 사항으로 설정하기
wandb를 조건부로 임포트하거나 pyproject.toml에서 선택적 의존성으로 선언할 수 있습니다.
- Python
- pyproject.toml
wandb를 사용할 수 있는지 확인하고, 사용자가 W&B 기능을 활성화했지만 이를 설치하지 않은 경우 명확한 오류를 발생시키세요:사용자 인증
wandb 클라이언트에서 이를 사용할 수 있게 해야 합니다.
API 키 생성
더 간편하게 하려면 User Settings로 이동해 API 키를 생성하세요. API 키는 즉시 복사해 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단의 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
W&B 설치 및 로그인
wandb 라이브러리를 설치하고 로그인하여 이후 run이 W&B에 인증할 수 있도록 하세요. 사용 중인 환경에 맞는 탭을 선택하세요.
- 명령줄
- Python
- Python 노트북
-
WANDB_API_KEY환경 변수를 API 키로 설정합니다.<>로 묶인 값은 자신의 값으로 바꾸세요. -
wandb라이브러리를 설치하고 로그인합니다.
run 시작하기
wandb.init()으로 run을 초기화하고 프로젝트 이름과 team entity(팀 이름)를 지정하세요. 프로젝트를 지정하지 않으면 W&B는 run을 “uncategorized”라는 기본 프로젝트에 저장합니다. <>로 묶인 값을 사용자 환경에 맞는 값으로 바꾸세요:
run.finish()를 호출해야 합니다. run을 종료하면 process가 종료되기 전에 모든 메트릭, 설정, 아티팩트가 업로드되도록 보장됩니다.
wandb를 선택적 의존성으로 설정하기
wandb를 선택 사항으로 만들어 사용자가 W&B run을 생성하지 않고도 라이브러리를 실행할 수 있게 하려면, 다음 접근 방식 중 하나를 사용하세요.
wandb플래그를 정의합니다.wandb.init()에서wandb를disabled로 설정합니다.wandb를 오프라인으로 설정합니다. 이 경우에도wandb는 계속 실행되지만, 인터넷을 통해 W&B와 통신을 시도하지 않을 뿐입니다.
wandb 플래그를 정의합니다.
- Python
- Bash
wandb.init()에서 wandb를 disabled로 설정합니다.
- Python
- Bash
wandb를 오프라인으로 설정합니다.
- Environment Variable
- Bash
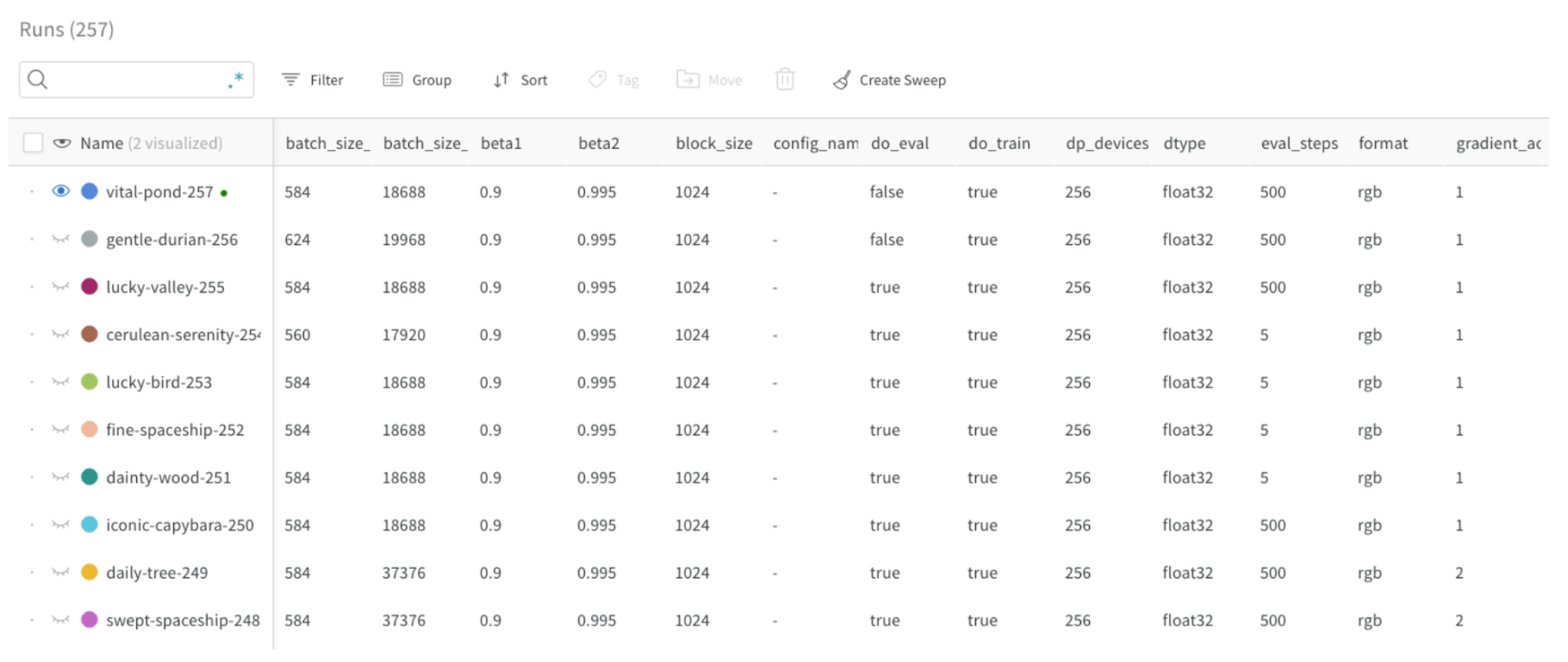
run config 정의하기
batch_size)가 config 파라미터로 정의되어 있으며 Runs table에 표시됩니다(첫 번째 column 참조). 이를 통해 사용자는 batch size를 기준으로 runs를 필터링하고 비교할 수 있습니다:
- 모델 이름, 버전, 아키텍처 파라미터, 하이퍼파라미터
- 데이터셋 이름, 버전, 트레이닝 또는 검증 예제 수
- 학습률, batch size, optimizer와 같은 트레이닝 파라미터
run config 업데이트
wandb.init()를 호출할 때는 아직 알 수 없을 수 있습니다. 초기화 시점에 값을 사용할 수 없는 경우, 나중에 wandb.Run.config.update로 config를 업데이트하세요. 예를 들어, 모델을 인스턴스화한 후 모델의 파라미터를 추가할 수 있습니다:
메트릭 및 데이터 로깅
메트릭 로깅
loss나 accuracy와 같은 스칼라 메트릭을 로깅하려면, 키가 메트릭 이름인 딕셔너리를 만드세요. 이 딕셔너리 객체를 wandb.Run.log()에 전달해 W&B에 로깅하세요:
train/과 val/를 사용하지만, 사용 사례에 맞는 접두사라면 무엇이든 사용할 수 있습니다.
이렇게 하면 프로젝트의 Workspace에서 트레이닝 및 검증 메트릭이나, 따로 구분하려는 다른 메트릭 유형별로 별도의 섹션이 생성됩니다:
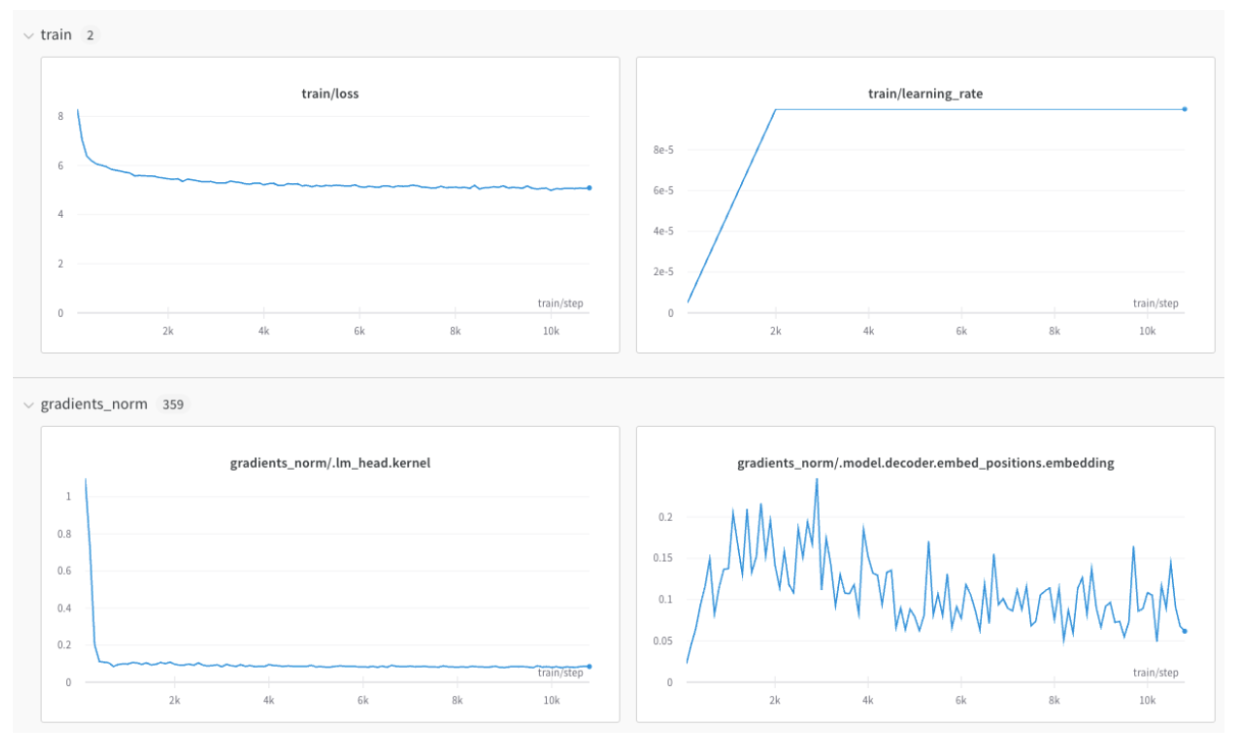
wandb.Run.log()를 참조하세요.
x-axis 제어
wandb.Run.log()를 여러 번 호출하면 wandb SDK는 wandb.Run.log()를 호출할 때마다 내부 step 카운터를 증가시킵니다. 이 카운터는 트레이닝 루프의 트레이닝 step과 맞지 않을 수 있습니다.
이 문제를 방지하려면 wandb.init()를 호출한 직후 wandb.Run.define_metric()를 사용해 x-axis step을 한 번만 명시적으로 정의하세요:
*은 모든 메트릭이 차트에서 x축으로 global_step을 사용한다는 뜻입니다. 특정 메트릭만 global_step을 기준으로 로깅하려면, 대신 해당 메트릭을 지정할 수 있습니다:
wandb.Run.log()를 호출할 때마다 메트릭과 step 메트릭, global_step를 로깅하세요:
global_step을 사용할 수 없는 경우), W&B는 이전에 로깅된 global_step 값을 자동으로 사용합니다. 이 경우 필요할 때 해당 메트릭이 정의되어 있도록 메트릭의 초기값을 로깅해야 합니다.
미디어 및 구조화 데이터 로깅
- 메트릭을 얼마나 자주 로깅해야 하나요? 선택 사항으로 둘 수 있나요?
- 시각화하는 데 어떤 유형의 데이터가 도움이 될 수 있나요?
- 이미지의 경우 시간에 따른 변화를 확인할 수 있도록 샘플 예측 결과와 세그멘테이션 마스크를 로깅할 수 있습니다.
- 텍스트의 경우 나중에 탐색할 수 있도록 샘플 예측 결과를 담은 테이블을 로깅할 수 있습니다.
분산 트레이닝 지원
- 메인 프로세스에서만 로깅합니다(권장).
- 모든 프로세스에서 로깅하고, 공유
group이름을 사용해 run을 그룹화합니다.
아티팩트를 사용해 모델과 데이터셋 추적하기

- 모델 체크포인트 또는 데이터셋을 아티팩트로 로깅할지 여부(선택 사항으로 제공하려는 경우).
- 아티팩트 입력 레퍼런스(예:
entity/project/artifact). - 모델 체크포인트 또는 데이터셋의 로깅 빈도. 예를 들어 매 에포크마다 또는 500 step마다입니다.
모델 체크포인트 로깅
입력 아티팩트 로깅하기
wandb.Run.use_artifact() 호출은 이 아티팩트를 현재 run에 연결하므로 W&B는 run에서 사용된 데이터셋의 리니지를 추적할 수 있습니다.
아티팩트 다운로드
wandb.Run.use_artifact()를 사용해 W&B의 아티팩트를 참조한 다음, wandb.Artifact.download()를 호출해 로컬 디렉터리로 다운로드합니다. wandb.Run.use_artifact()를 사용하면 아티팩트가 현재 run의 입력으로도 기록되어 리니지가 유지됩니다.