- 모델 팀(Model Team): 모델 구축 팀이 새로운 Chat Model(Llama 3.2)을 파인튜닝하고 W&B Models를 사용하여 레지스트리에 저장합니다.
- 앱 팀(App Team): 앱 개발 팀이 해당 Chat Model을 가져와 W&B Weave를 사용하여 새로운 RAG 챗봇을 생성하고 평가합니다.
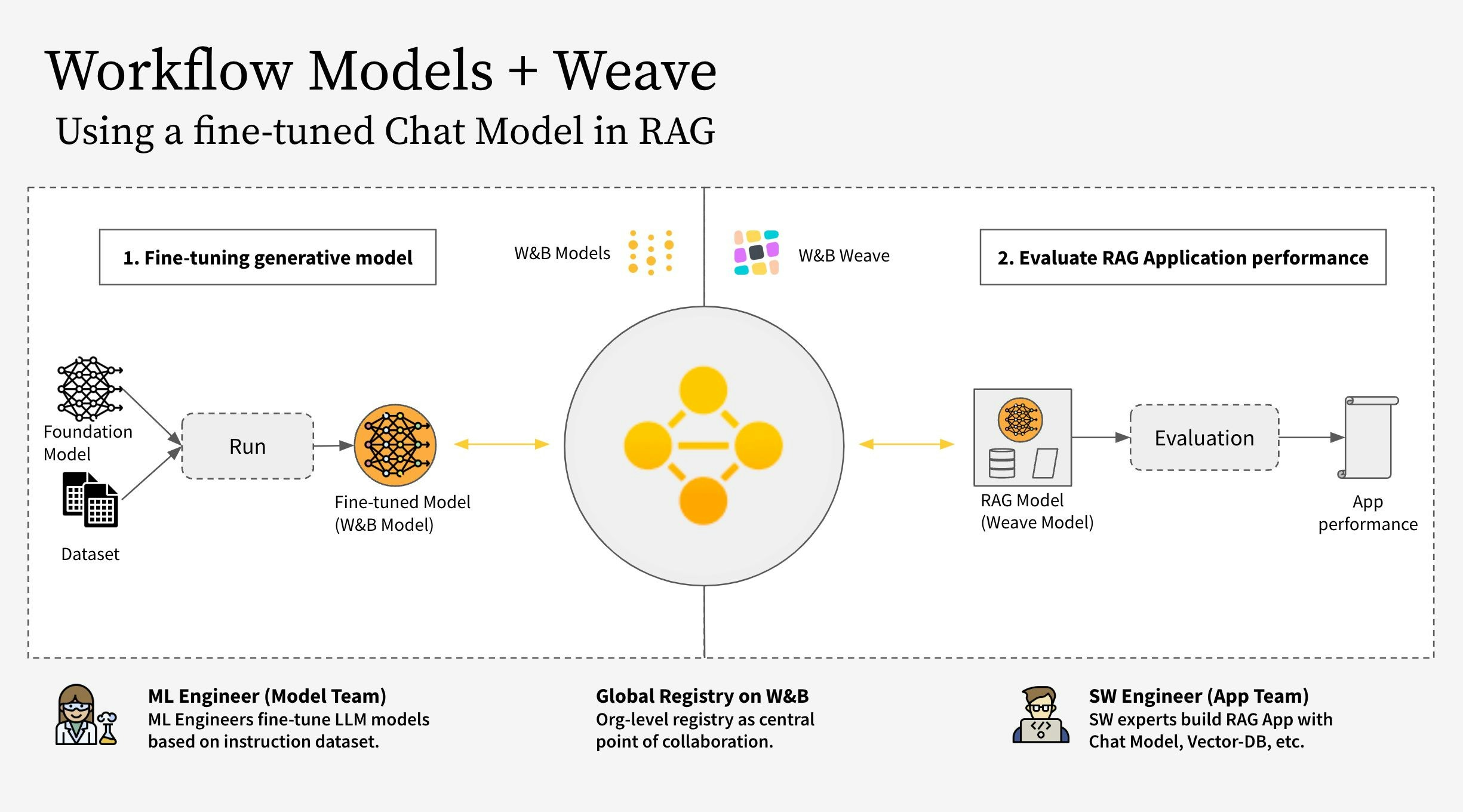
- W&B Weave로 RAG 앱 코드를 계측(Instrument)합니다.
- LLM(Llama 3.2 등, 다른 LLM으로 교체 가능)을 파인튜닝하고 W&B Models로 추적합니다.
- 파인튜닝된 모델을 W&B Registry에 로그합니다.
- 새로운 파인튜닝 모델로 RAG 앱을 구현하고 W&B Weave로 앱을 평가합니다.
- 결과가 만족스러우면 업데이트된 Rag 앱의 레퍼런스를 W&B Registry에 저장합니다.
RagModel은 전체 RAG 앱으로 간주할 수 있는 최상위 weave.Model입니다. 여기에는 ChatModel, 벡터 데이터베이스 및 프롬프트가 포함됩니다. ChatModel 또한 W&B Registry에서 아티팩트를 다운로드하는 코드가 포함된 또 다른 weave.Model이며, RagModel의 일부로서 다른 채팅 모델을 지원하도록 변경할 수 있습니다. 자세한 내용은 Weave의 전체 모델에서 확인하세요.
1. 설정
먼저weave와 wandb를 설치한 다음 API 키로 로그인합니다. API 키는 User Settings에서 생성하고 확인할 수 있습니다.
2. Artifact 기반의 ChatModel 만들기
레지스트리에서 파인튜닝된 채팅 모델을 가져와 weave.Model을 생성합니다. 이는 다음 단계의 RagModel에 직접 연결할 수 있습니다. 기존 ChatModel과 동일한 파라미터를 사용하며, init과 predict만 변경됩니다.
unsloth 라이브러리를 사용하여 다양한 Llama-3.2 모델을 파인튜닝했습니다. 따라서 레지스트리에서 다운로드한 모델을 로드할 때 어댑터가 포함된 특수 unsloth.FastLanguageModel 또는 peft.AutoPeftModelForCausalLM 모델을 사용하세요. 레지스트리의 “Use” 탭에서 로딩 코드를 복사하여 model_post_init에 붙여넣습니다.
3. 새로운 ChatModel 버전을 RagModel에 통합
파인튜닝된 채팅 모델로 RAG 앱을 구축하면 대화형 AI 시스템의 성능과 범용성을 향상시키는 데 여러 가지 이점이 있습니다.
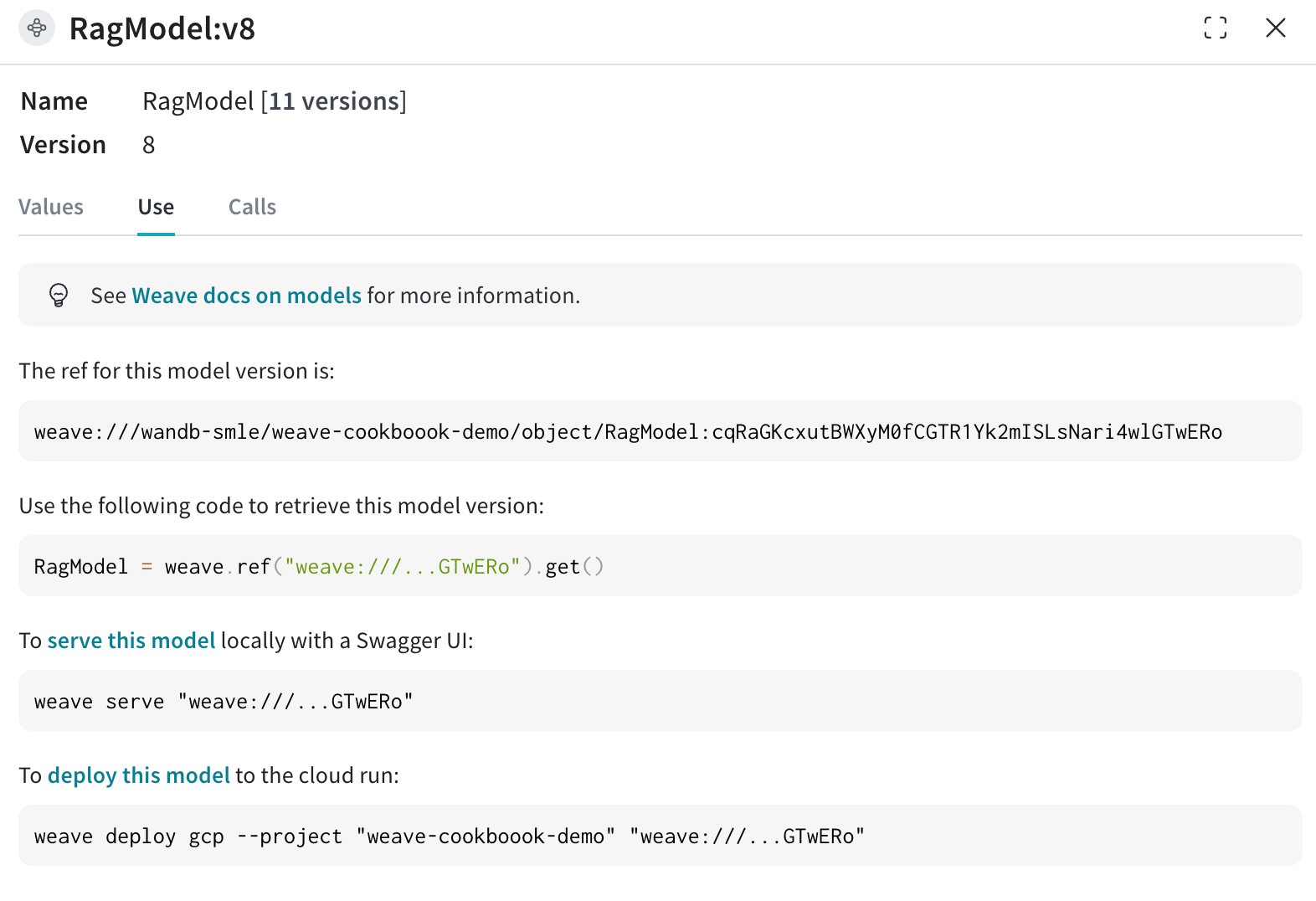
이제 기존 Weave 프로젝트에서 RagModel을 가져와서(아래 이미지처럼 use 탭에서 현재 RagModel의 weave ref를 가져올 수 있습니다) ChatModel을 새 모델로 교체합니다. 다른 컴포넌트(VDB, 프롬프트 등)를 변경하거나 다시 만들 필요가 없습니다!
4. 기존 모델 Run에 연결된 새로운 weave.Evaluation 실행
마지막으로, 기존의 weave.Evaluation에서 새로운 RagModel을 평가합니다. 통합을 최대한 쉽게 하기 위해 다음 변경 사항을 포함합니다.
Models 관점:
- 레지스트리에서 모델을 가져오면 채팅 모델의 E2E 계보(Lineage)의 일부인 새로운
run오브젝트가 생성됩니다. - 모델 팀이 링크를 클릭하여 해당 Weave 페이지로 이동할 수 있도록 Run 설정에 Trace ID(현재 평가 ID 포함)를 추가합니다.
- 아티팩트 / 레지스트리 링크를
ChatModel(RagModel내의)의 입력으로 저장합니다. weave.attributes를 사용하여 run.id를 trace의 추가 컬럼으로 저장합니다.