early_stopping_rounds는 몇 회로 설정해야 할까요? 트리의 max_depth는 얼마가 적당할까요?
가장 성능이 좋은 모델을 찾기 위해 고차원 하이퍼파라미터 공간을 탐색하는 과정은 매우 빠르게 복잡해질 수 있습니다.
하이퍼파라미터 Sweeps는 여러 모델의 대결을 통해 승자를 가려내는 체계적이고 효율적인 방법을 제공합니다.
Sweeps는 하이퍼파라미터 값의 조합을 자동으로 탐색하여 최적의 값을 찾아줍니다.
이 튜토리얼에서는 W&B를 사용하여 단 3단계 만에 XGBoost 모델에 대한 정교한 하이퍼파라미터 Sweeps를 실행하는 방법을 알아보겠습니다.
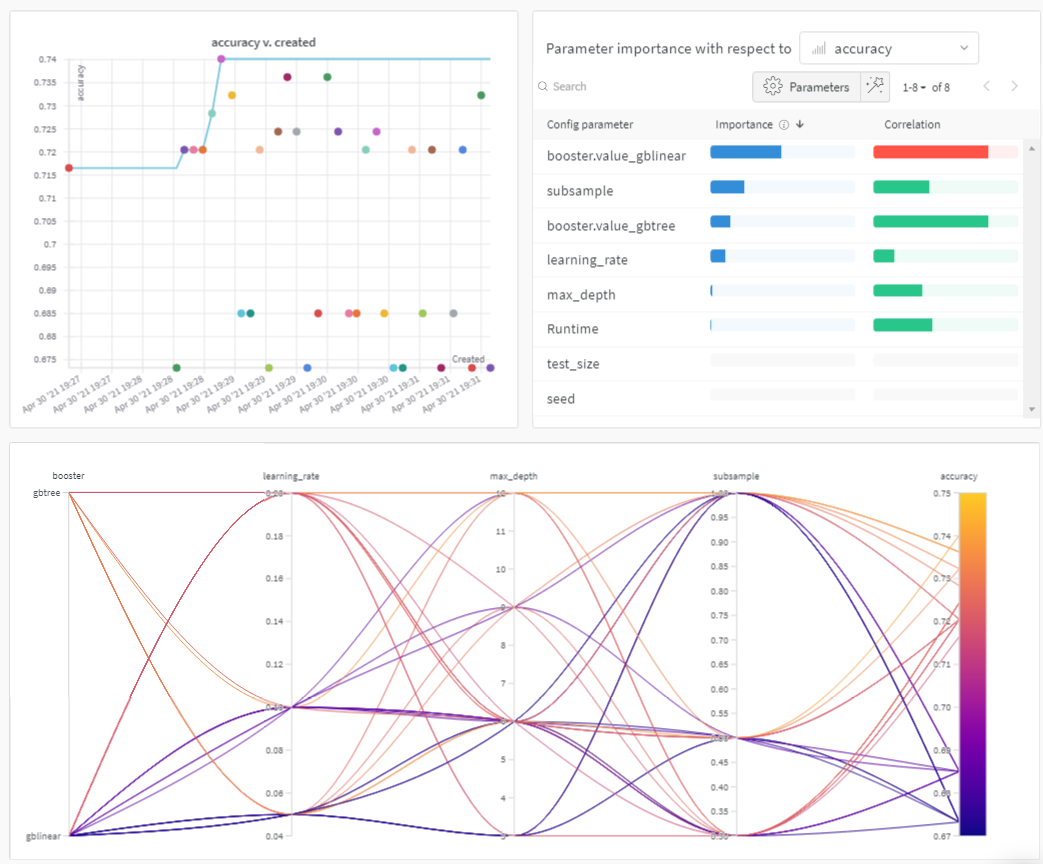
아래 플롯에서 결과의 예시를 미리 확인해 보세요:
Sweeps 개요
W&B에서 하이퍼파라미터 스윕을 실행하는 방법은 매우 간단합니다. 다음 3단계만 거치면 됩니다:- 스윕 정의: 스윕을 명세하는 사전(dictionary) 형태의 오브젝트를 생성합니다. 여기에는 탐색할 파라미터, 탐색 전략, 최적화할 메트릭을 지정합니다.
-
스윕 초기화: 코드 한 행으로 스윕을 초기화하고 스윕 구성(sweep configuration) 사전을 전달합니다:
sweep_id = wandb.sweep(sweep_config) -
스윕 에이전트 실행: 역시 코드 한 행으로
wandb.agent()를 호출합니다. 이때sweep_id와 모델 아키텍처를 정의하고 트레이닝하는 함수를 함께 전달합니다:wandb.agent(sweep_id, function=train)
참고 자료
1. 스윕 정의 (Define the Sweep)
W&B Sweeps는 단 몇 줄의 코드로 스윕을 원하는 대로 정확하게 설정할 수 있는 강력한 제어 기능을 제공합니다. 스윕 구성은 사전(dictionary) 또는 YAML 파일로 정의할 수 있습니다. 주요 설정 항목들을 함께 살펴보겠습니다:- Metric: 스윕이 최적화하고자 하는 메트릭입니다. 메트릭은
name(트레이닝 스크립트에서 로그로 기록되어야 함)과goal(maximize또는minimize) 설정을 가집니다. - Search Strategy:
"method"키를 사용하여 지정합니다. Sweeps는 여러 탐색 전략을 지원합니다.- Grid Search: 하이퍼파라미터 값의 모든 가능한 조합을 순회합니다.
- Random Search: 하이퍼파라미터 값의 조합을 무작위로 선택하여 순회합니다.
- Bayesian Search: 하이퍼파라미터와 메트릭 점수 사이의 관계를 나타내는 확률 모델을 생성하고, 메트릭을 개선할 확률이 높은 파라미터를 선택합니다. 베이지안 최적화의 목적은 하이퍼파라미터 값을 선택하는 데 더 많은 시간을 할애하는 대신, 시도하는 조합의 수를 줄이는 것입니다.
- Parameters: 하이퍼파라미터 이름과 각 반복에서 사용할 이산적인 값, 범위 또는 분포를 포함하는 사전입니다.
2. 스윕 초기화 (Initialize the Sweep)
wandb.sweep을 호출하면 스윕 컨트롤러(Sweep Controller)가 시작됩니다.
이는 parameters 설정을 요청하는 곳에 해당 값을 제공하고, wandb 로그를 통해 metrics 성능 결과를 돌려받는 중앙 집중식 프로세스입니다.
트레이닝 프로세스 정의
스윕을 실행하기 전에 모델을 생성하고 트레이닝하는 함수를 정의해야 합니다. 이 함수는 하이퍼파라미터 값을 입력받아 메트릭을 출력합니다. 또한 스크립트에wandb를 통합해야 합니다. 주요 구성 요소는 세 가지입니다:
wandb.init(): 새로운 W&B Run을 초기화합니다. 각 run은 트레이닝 스크립트의 단일 실행 단위입니다.run.config: 모든 하이퍼파라미터를 설정 오브젝트에 저장합니다. 이를 통해 W&B 앱에서 하이퍼파라미터 값에 따라 run을 정렬하고 비교할 수 있습니다.run.log(): 메트릭과 이미지, 비디오, 오디오, HTML, 플롯, 포인트 클라우드와 같은 커스텀 오브젝트를 기록합니다.
3. 에이전트로 스윕 실행 (Run the Sweep with an agent)
이제wandb.agent를 호출하여 스윕을 시작합니다.
W&B에 로그인되어 있고 다음 항목이 준비된 모든 머신에서 wandb.agent를 호출할 수 있습니다:
sweep_id- 데이터셋 및
train함수
참고:random스윕은 기본적으로 사용자가 앱 UI에서 스윕을 종료할 때까지 새로운 파라미터 조합을 시도하며 무한히 실행됩니다. 에이전트가 완료하길 원하는 총 run 횟수(count)를 지정하여 이를 제한할 수 있습니다.
결과 시각화
스윕이 완료되었으므로 결과를 확인할 차례입니다. W&B는 유용한 플롯들을 자동으로 생성합니다.평행 좌표 플롯 (Parallel coordinates plot)
이 플롯은 하이퍼파라미터 값과 모델 메트릭을 매핑합니다. 최상의 모델 성능을 이끌어낸 하이퍼파라미터 조합을 좁혀나가는 데 유용합니다. 이 플롯을 보면 학습기로 트리를 사용하는 것이 단순 선형 모델을 사용하는 것보다 성능이 약간 더 좋다는 것을 알 수 있습니다.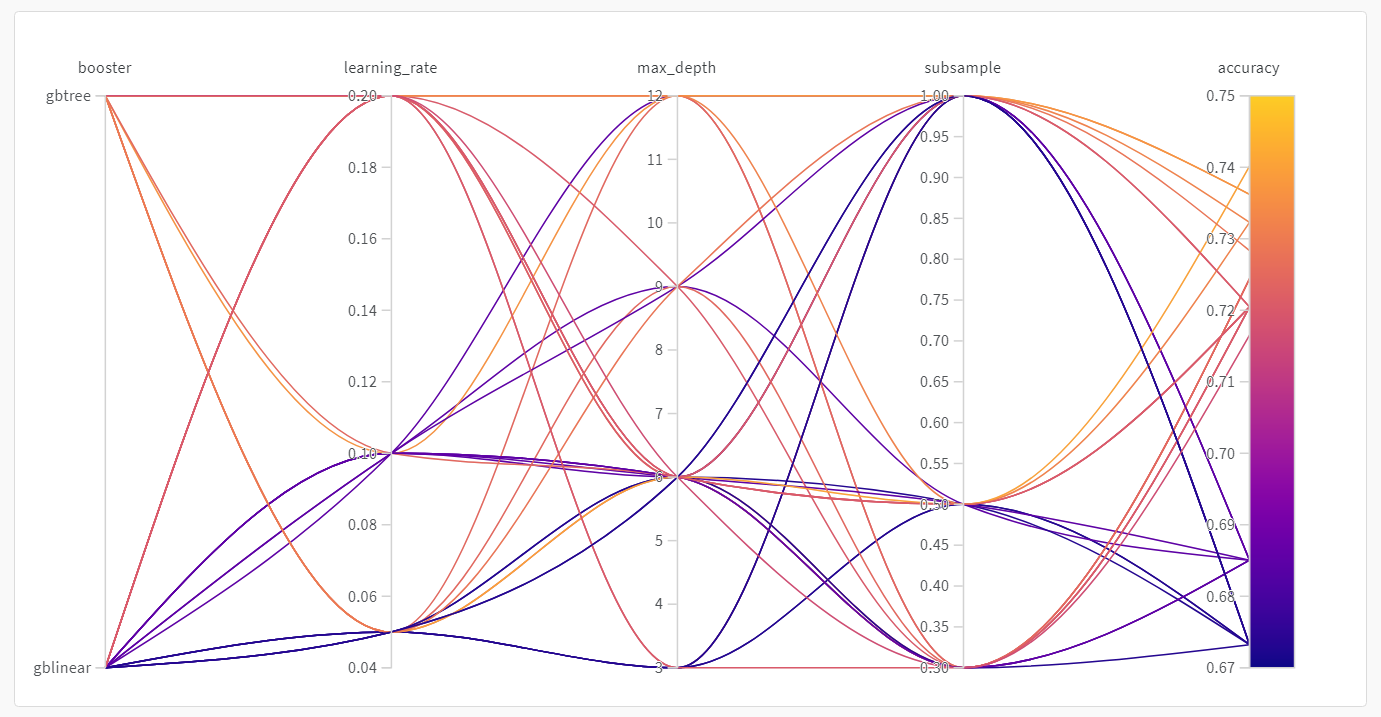
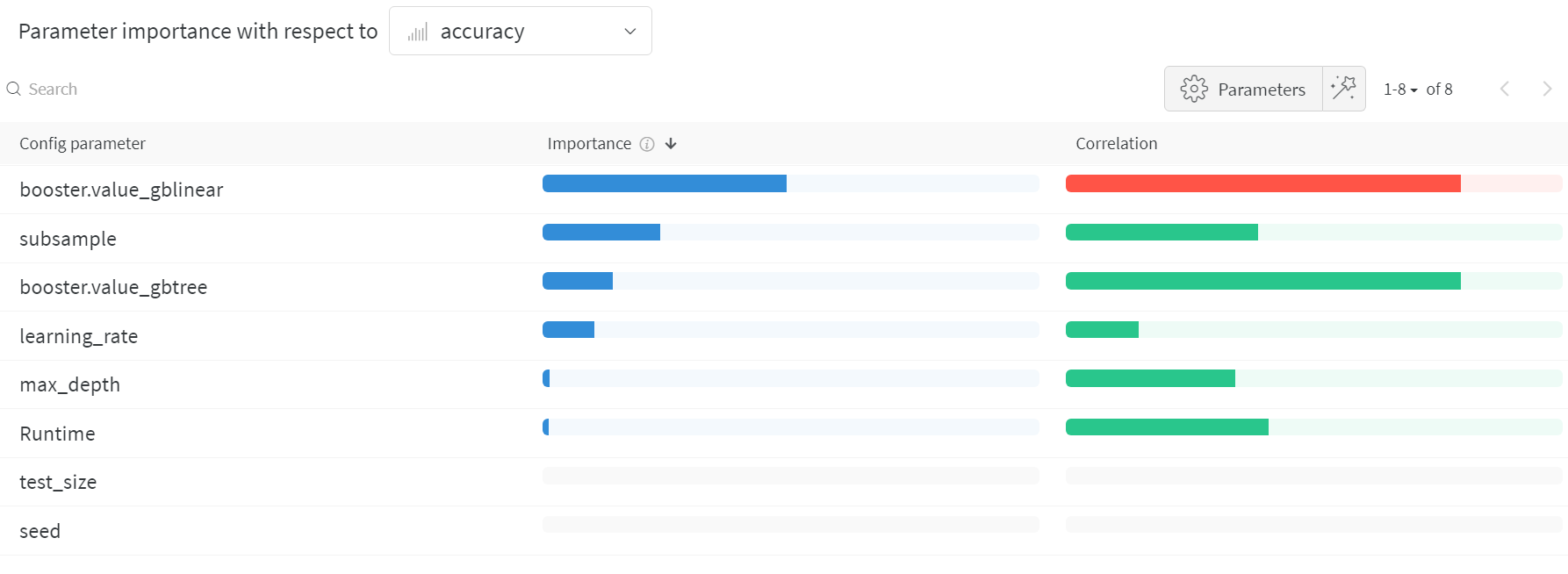
하이퍼파라미터 중요도 플롯 (Hyperparameter importance plot)
파라미터 중요도 플롯은 어떤 하이퍼파라미터 값이 메트릭에 가장 큰 영향을 미쳤는지 보여줍니다. 상관관계(선형 예측 변수로 취급)와 특성 중요도(결과에 대해 랜덤 포레스트를 학습시킨 후 산출)를 모두 보고하므로, 어떤 파라미터가 가장 큰 영향을 주었는지, 그리고 그 영향이 긍정적인지 부정적인지 확인할 수 있습니다. 이 차트를 읽어보면 위 평행 좌표 차트에서 발견한 경향을 정량적으로 확인할 수 있습니다. 검증 정확도에 가장 큰 영향을 준 것은 학습기의 선택이었으며, 일반적으로gblinear 학습기가 gbtree 학습기보다 성능이 낮았습니다.