Configurer une évaluation dans le playground
- Ouvrez le Weave UI, puis ouvrez le projet dans lequel vous souhaitez effectuer l’évaluation. La page Traces s’ouvre.
- Depuis la page Traces, cliquez sur l’icône Playground dans le menu de gauche, puis sélectionnez l’onglet Evaluate sur la page Playground. Sur la page Evaluate, vous pouvez soit :
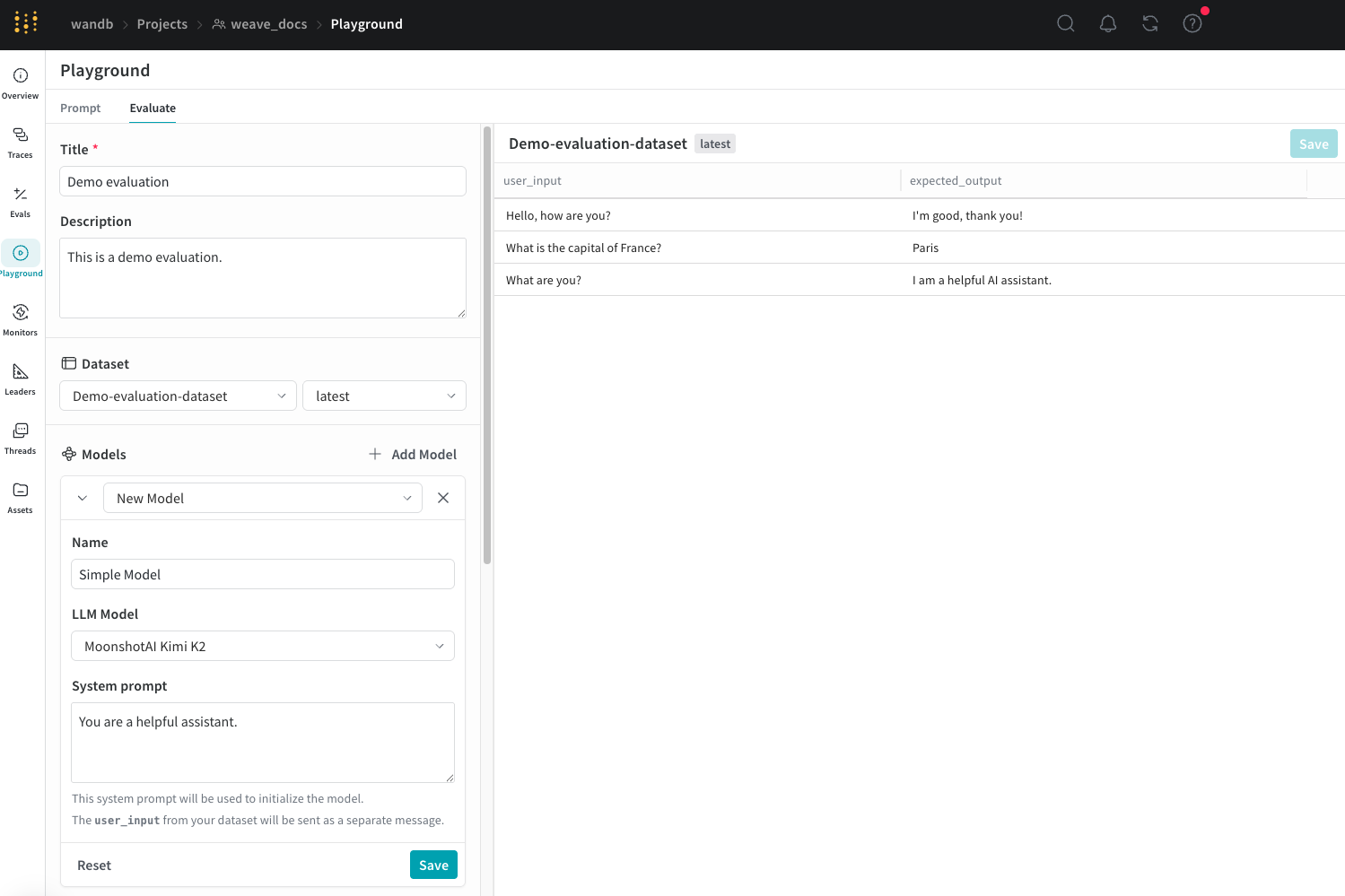
- Load a demo example : cette option charge une configuration prédéfinie qui évalue le modèle MoonshotAI Kimi K2 par rapport à la sortie attendue et utilise un juge LLM pour en déterminer la justesse. Vous pouvez utiliser cette configuration pour vous familiariser avec l’interface.
- Start from scratch : cette option charge une configuration vierge que vous pouvez ensuite compléter.
- Si vous avez sélectionné Start from scratch, ajoutez un titre et une description explicites pour votre évaluation dans les champs Title et Description.
Ajouter un dataset
.csv.tsv.json.jsonl
- Cliquez sur le menu déroulant, puis sélectionnez l’une des options suivantes :
- Start from scratch pour créer un nouveau dataset dans l’interface utilisateur.
- Upload a file pour importer un dataset depuis votre machine locale.
- Un dataset existant déjà enregistré dans votre projet.
- Facultatif : cliquez sur Save pour enregistrer le dataset dans votre projet afin de le réutiliser plus tard.
Vous pouvez utiliser l’interface utilisateur pour modifier uniquement les nouveaux datasets.Il est également important de nommer correctement les colonnes de votre dataset
user_input et expected_output afin que les évaluateurs puissent accéder aux données.Ajouter un modèle
- Cliquez sur Add Model, puis sélectionnez soit New Model, soit un modèle existant dans le menu déroulant.
-
Si vous avez sélectionné New Model, configurez les champs suivants :
- Name : ajoutez un nom descriptif à votre nouveau modèle.
- LLM Model : sélectionnez un modèle de fondation sur lequel construire votre nouveau modèle, comme GPT-4 d’OpenAI. Vous pouvez sélectionner un modèle de fondation dans une liste de modèles pour lesquels vous avez déjà configuré l’accès, ou ajouter l’accès à un modèle de fondation en sélectionnant Add AI provider, puis en choisissant un modèle. L’ajout d’un fournisseur vous invite à saisir vos identifiants d’accès pour ce fournisseur. Consultez la documentation de votre fournisseur pour savoir comment trouver votre clé API, vos points de terminaison et toute information de configuration supplémentaire nécessaire pour accéder au modèle avec Weave.
- System Prompt : indiquez au modèle comment il doit se comporter, par exemple :
You are a helpful assistant specializing in Python programming.Leuser_inputde votre dataset est envoyé dans un message ultérieur ; vous n’avez donc pas besoin de l’inclure dans le prompt système.
- Facultatif : cliquez sur Save pour enregistrer le modèle dans votre projet afin de l’utiliser plus tard.
- Facultatif : pour évaluer plusieurs modèles simultanément, cliquez de nouveau sur Add Model et ajoutez d’autres modèles si nécessaire.
Ajouter des évaluateurs
-
Cliquez sur Add Scorer, puis configurez les champs suivants :
- Name : Ajoutez un nom descriptif à votre évaluateur.
-
Type : Sélectionnez le format de sortie des scores : booléen ou numérique. Les évaluateurs booléens renvoient une valeur binaire
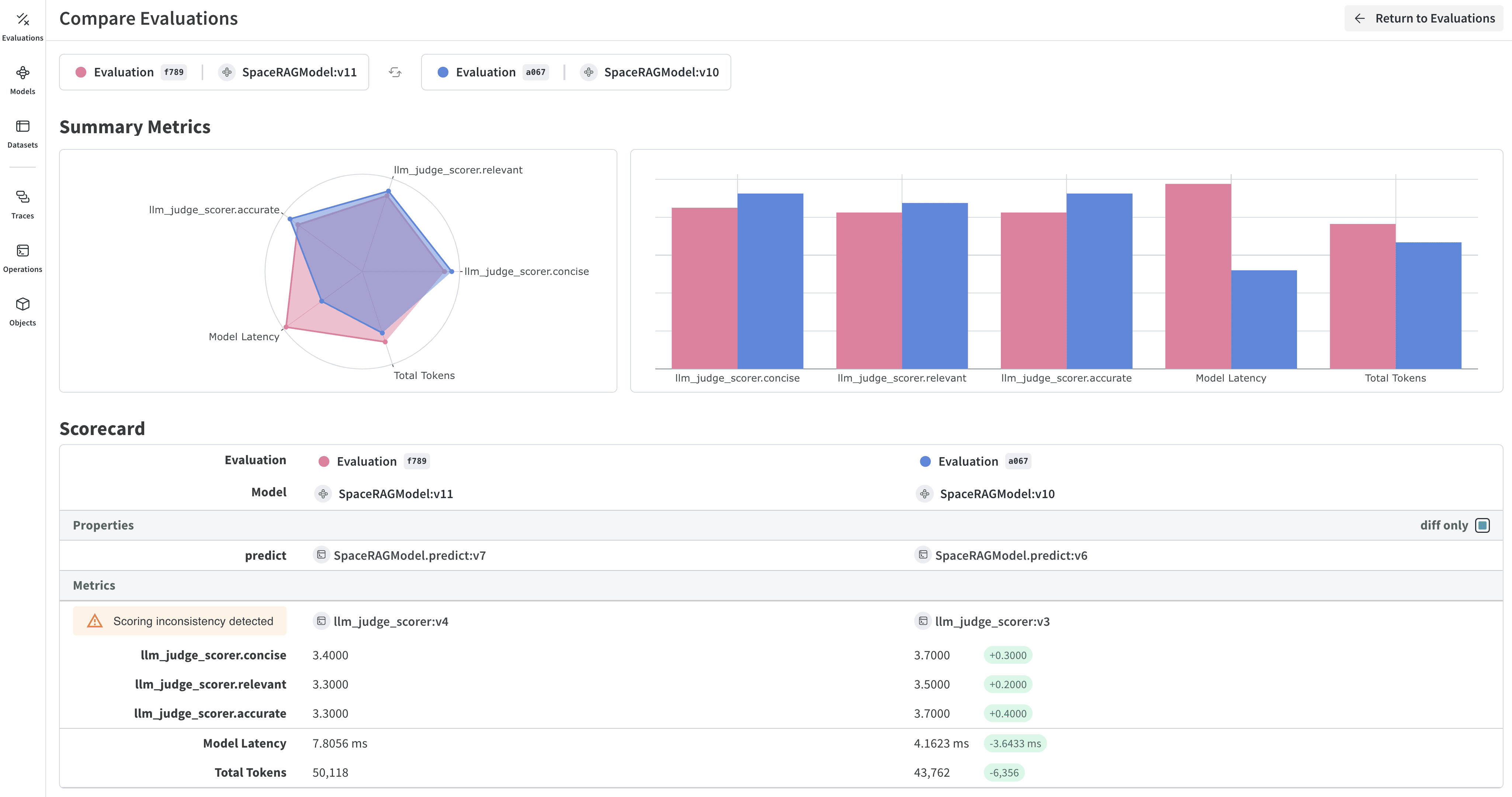
TrueouFalseselon que la sortie du modèle respecte ou non les paramètres d’évaluation que vous avez définis. Les évaluateurs numériques renvoient un score compris entre0et1, qui donne une appréciation générale de la mesure dans laquelle la sortie du modèle respecte vos paramètres d’évaluation. - LLM-as-a-judge-model : Sélectionnez un modèle de fondation à utiliser comme juge pour l’évaluateur. Comme pour le champ LLM Model dans la section Models, vous pouvez choisir parmi les modèles de fondation auxquels vous avez déjà configuré l’accès, ou configurer un nouvel accès à des modèles de fondation.
-
Scoring Prompt : Indiquez les paramètres du juge LLM pour évaluer la sortie. Par exemple, pour vérifier la présence d’hallucinations, saisissez une invite d’évaluation semblable à celle-ci :
Vous pouvez utiliser les champs de vos Datasets et de vos réponses comme variables dans l’invite d’évaluation, par exemple
{user_input},{expected_output}et{output}. Pour voir la liste des variables disponibles, cliquez sur Insert variable dans l’interface utilisateur.
- Facultatif : cliquez sur Save pour enregistrer l’évaluateur dans votre projet afin de l’utiliser plus tard.
Lancer l’évaluation
- Pour lancer l’évaluation dans l’Evaluation Playground, cliquez sur Run eval.
Consulter les résultats de l’évaluation