これはインタラクティブなノートブックです。ローカルで実行することも、以下のリンクを使用することもできます。
サードパーティシステムからトレースをインポート
conversation_id を、子の識別子として turn_index を使用します。
ご自身のデータセット、ファイルパス、および W&B project に合わせて、以下のセクションの変数を変更する必要があります。
環境を設定する
import します。
wandb.login() でログインできるように、WANDB_API_KEY を環境に設定します (Colab にはシークレットとして指定します) 。
Colab にアップロードする file の名を name_of_file に設定し、ログ先の W&B project を name_of_wandb_project に設定します。
トレースのログ先チームを指定するには、
name_of_wandb_project に [TEAM_NAME]/[PROJECT_NAME] 形式を指定することもできます。weave.init() を呼び出して Weave クライアントを取得します。
データを読み込む
conversation_id と turn_index でソートして、親子関係が正しい順序になるようにします。
その結果、会話のターンが conversation_data に配列として格納された、2 列の pandas DataFrame になります。
トレースを Weave にログする
conversation_idごとに親 Call を作成します。- ターン配列を反復処理して、
turn_index順に並べた子 Call を作成します。
- Weave Call は Weave トレースに相当します。この Call には、親や子を関連付けることができます。
- Weave Call には、feedback やメタデータなど、ほかの項目を関連付けることもできます。この例では inputs と output のみを関連付けていますが、データにそれらが含まれている場合は、import に追加できます。
- Weave Call には
createdとfinishedがあります。これは、これらがリアルタイムでトラッキングされることを前提としているためです。今回は事後の import であるため、オブジェクトを定義して相互に関連付けたあとで、作成と完了を一度に行います。 - Call の
op値は、同じ構成の Call を Weave がどのように分類するかを示します。この例では、すべての親 Call はConversationタイプで、すべての子 Call はTurnタイプです。必要に応じて変更できます。 - Call は
inputsとoutputを持つことができます。inputsは作成時に定義し、outputは Call の完了時に定義します。
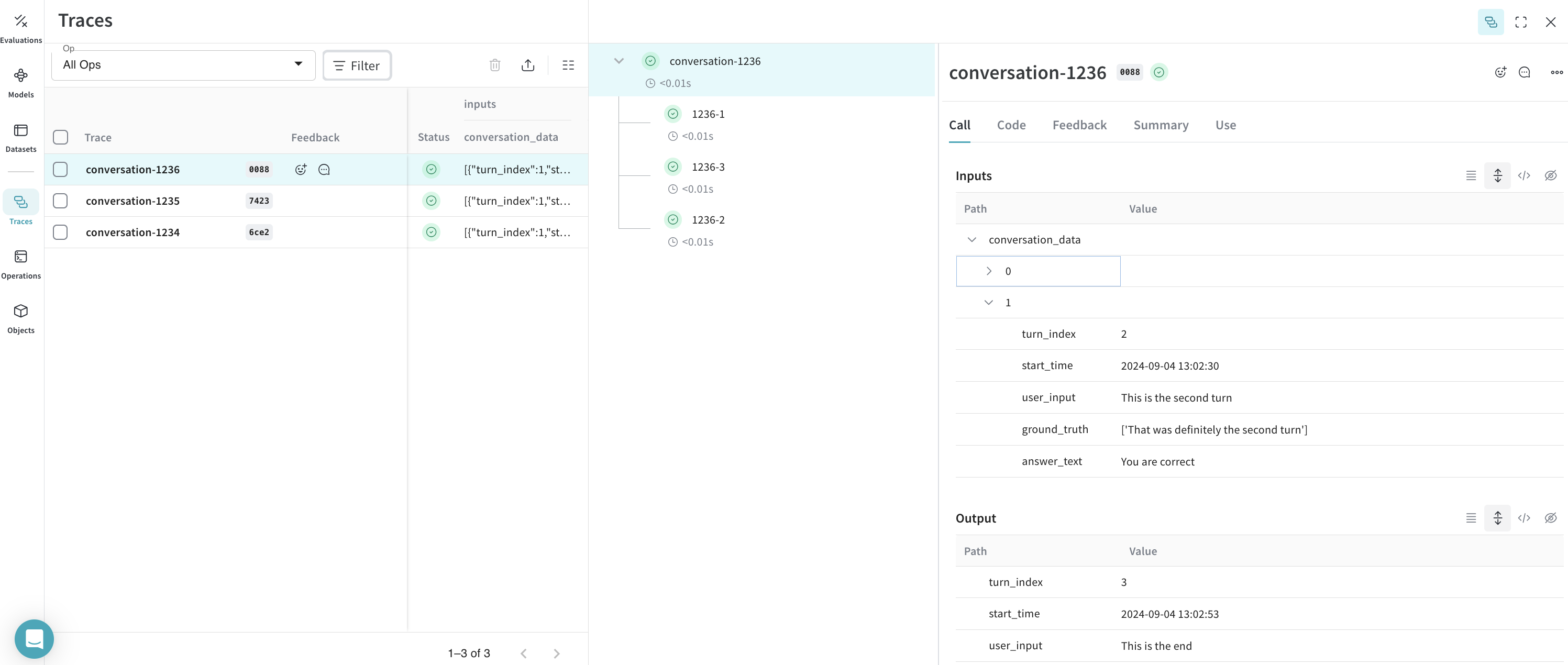
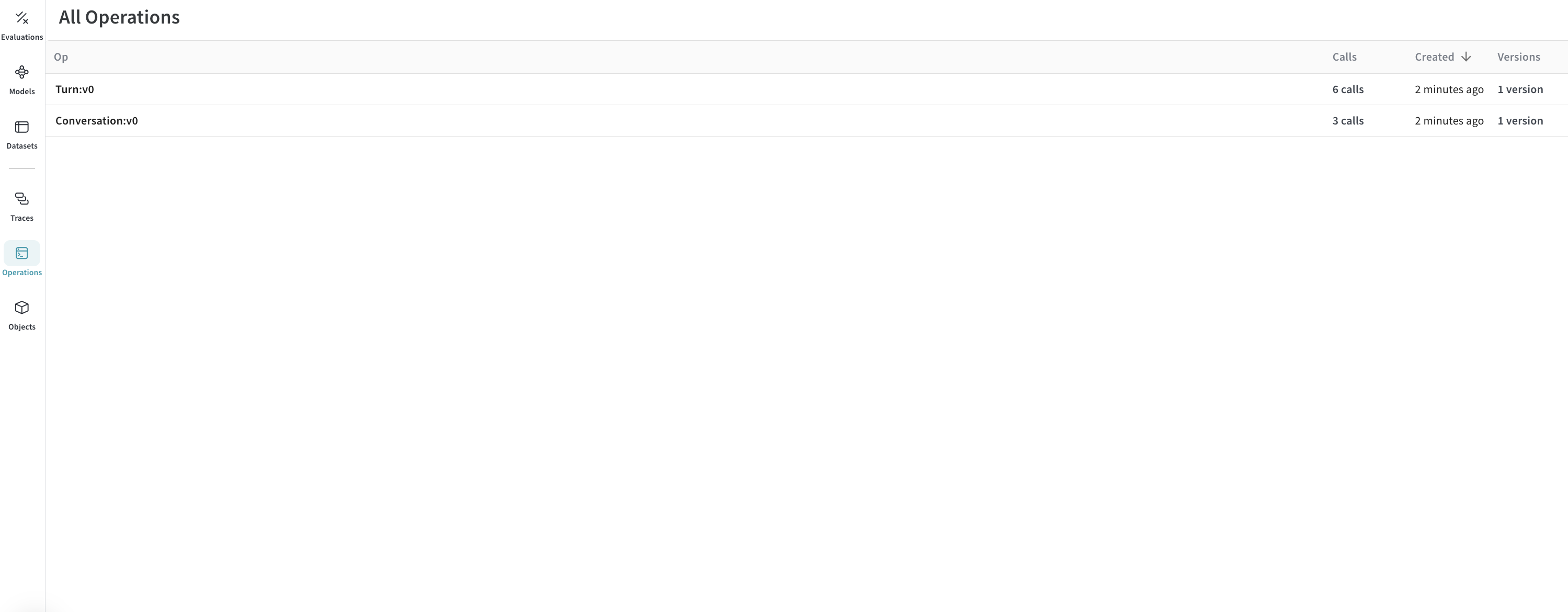
結果: Weave にログされたトレース
Conversation および Turn オペレーションの下にグループ化された会話とそのターンを Weave UI で確認できます。
トレース:
オプション: トレースをエクスポートして評価を実行する
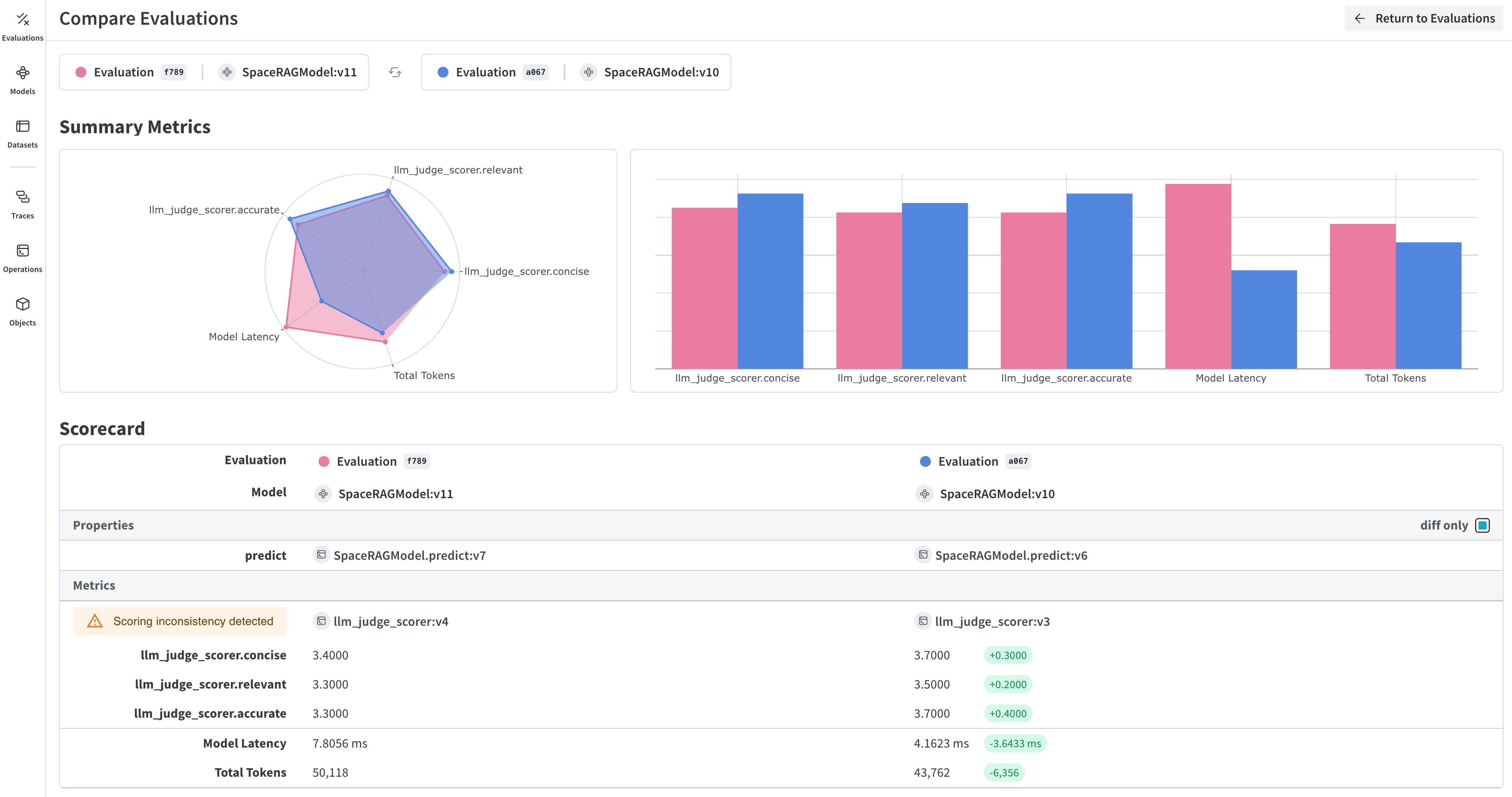
結果