from ignite.contrib.handlers.wandb_logger import *
def run(train_batch_size, val_batch_size, epochs, lr, momentum, log_interval):
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
model = Net()
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
optimizer = SGD(model.parameters(), lr=lr, momentum=momentum)
trainer = create_supervised_trainer(model, optimizer, F.nll_loss, device=device)
evaluator = create_supervised_evaluator(model,
metrics={'accuracy': Accuracy(),
'nll': Loss(F.nll_loss)},
device=device)
desc = "ITERATION - loss: {:.2f}"
pbar = tqdm(
initial=0, leave=False, total=len(train_loader),
desc=desc.format(0)
)
#WandBlogger 객체 생성
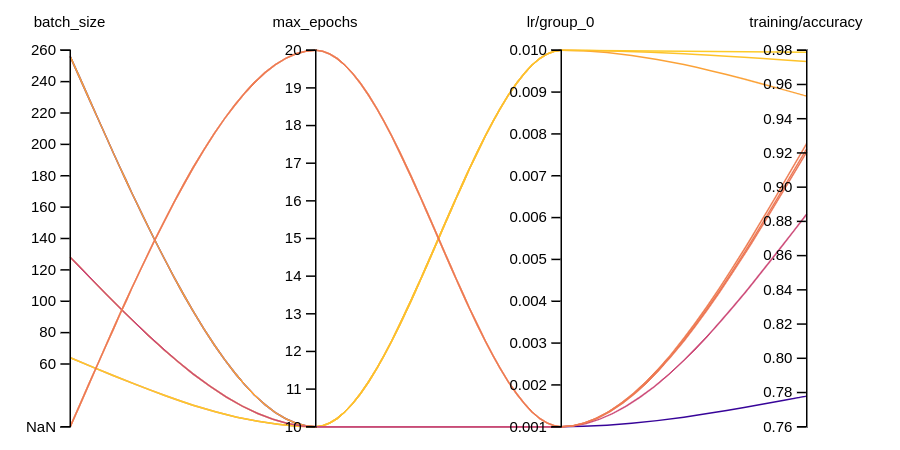
wandb_logger = WandBLogger(
project="pytorch-ignite-integration",
name="cnn-mnist",
config={"max_epochs": epochs,"batch_size":train_batch_size},
tags=["pytorch-ignite", "mninst"]
)
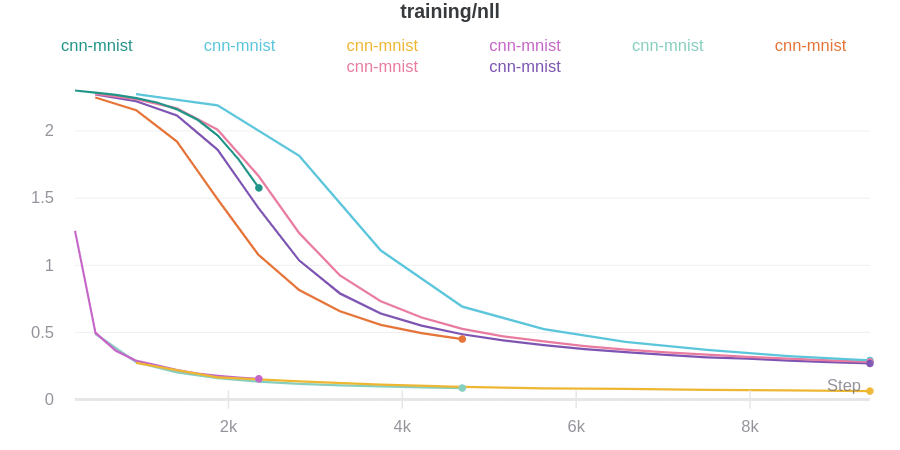
wandb_logger.attach_output_handler(
trainer,
event_name=Events.ITERATION_COMPLETED,
tag="training",
output_transform=lambda loss: {"loss": loss}
)
wandb_logger.attach_output_handler(
evaluator,
event_name=Events.EPOCH_COMPLETED,
tag="training",
metric_names=["nll", "accuracy"],
global_step_transform=lambda *_: trainer.state.iteration,
)
wandb_logger.attach_opt_params_handler(
trainer,
event_name=Events.ITERATION_STARTED,
optimizer=optimizer,
param_name='lr' # 선택
)
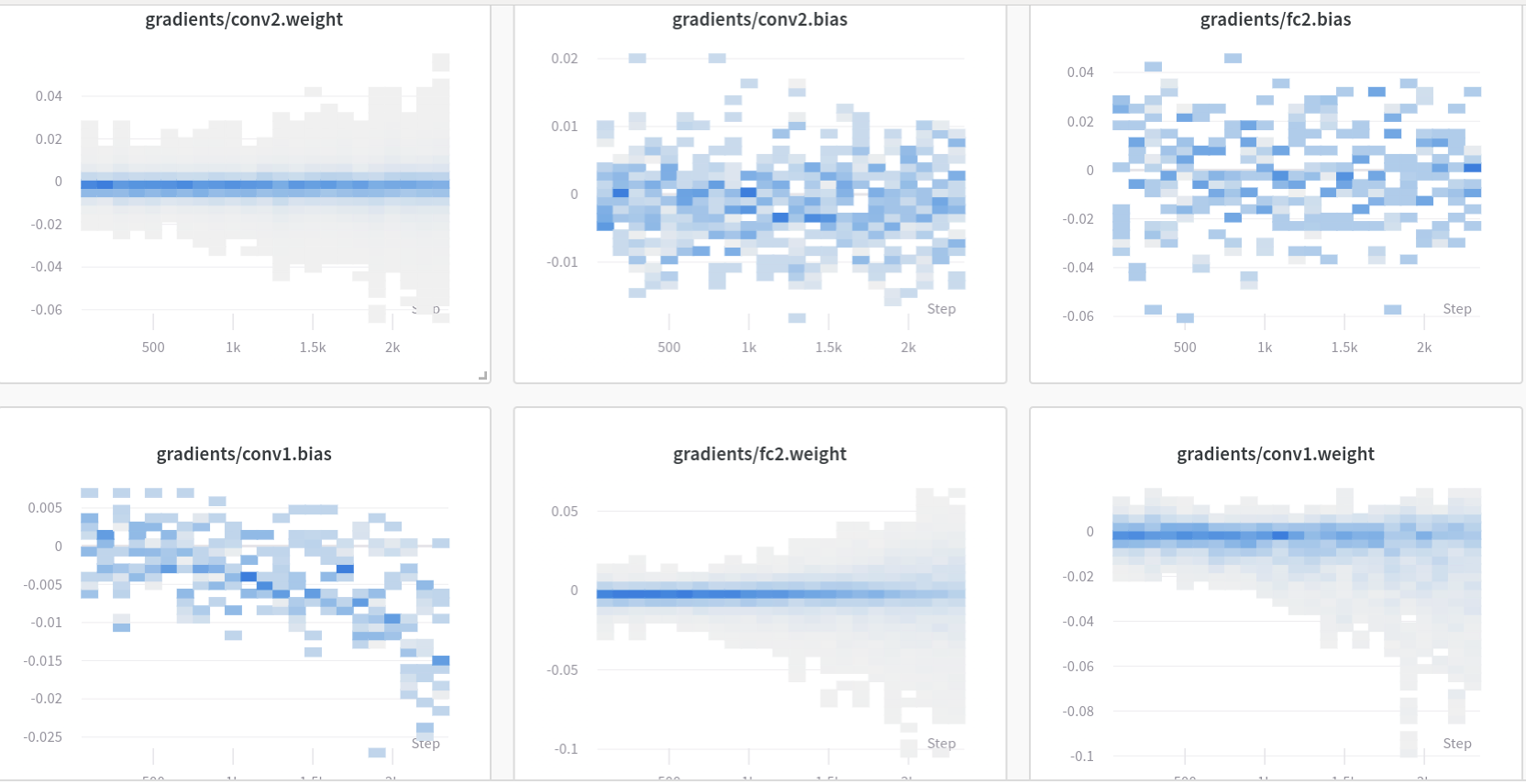
wandb_logger.watch(model)