Deployment time varies by model and machine type. The base
Llama2-7b config takes about 1 minute on Google Cloud’s a2-ultragpu-1g.퀵스타트
-
아직 없다면 launch queue를 만드세요. 큐는 작업이 GPU 머신에서 실행되는 방식을 정의합니다. 다음 예시 큐 설정을 참조하세요.
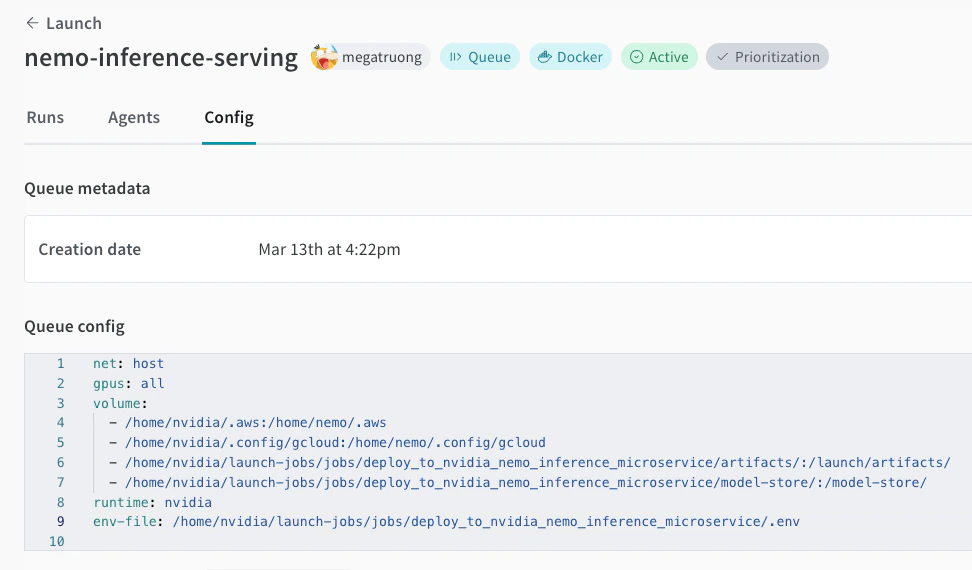
-
프로젝트에서 이 작업을 만드세요. 이렇게 하면 배포 작업 코드가 W&B 프로젝트에 등록되어 Launch에서 이를 실행할 수 있습니다.
-
GPU 머신에서 에이전트를 시작하세요. 에이전트는 큐를 폴링하고, 제출되면 배포 작업을 실행합니다.
-
원하는 설정으로 Launch UI에서 배포 launch 작업을 제출하세요. CLI를 통해서도 제출할 수 있습니다.
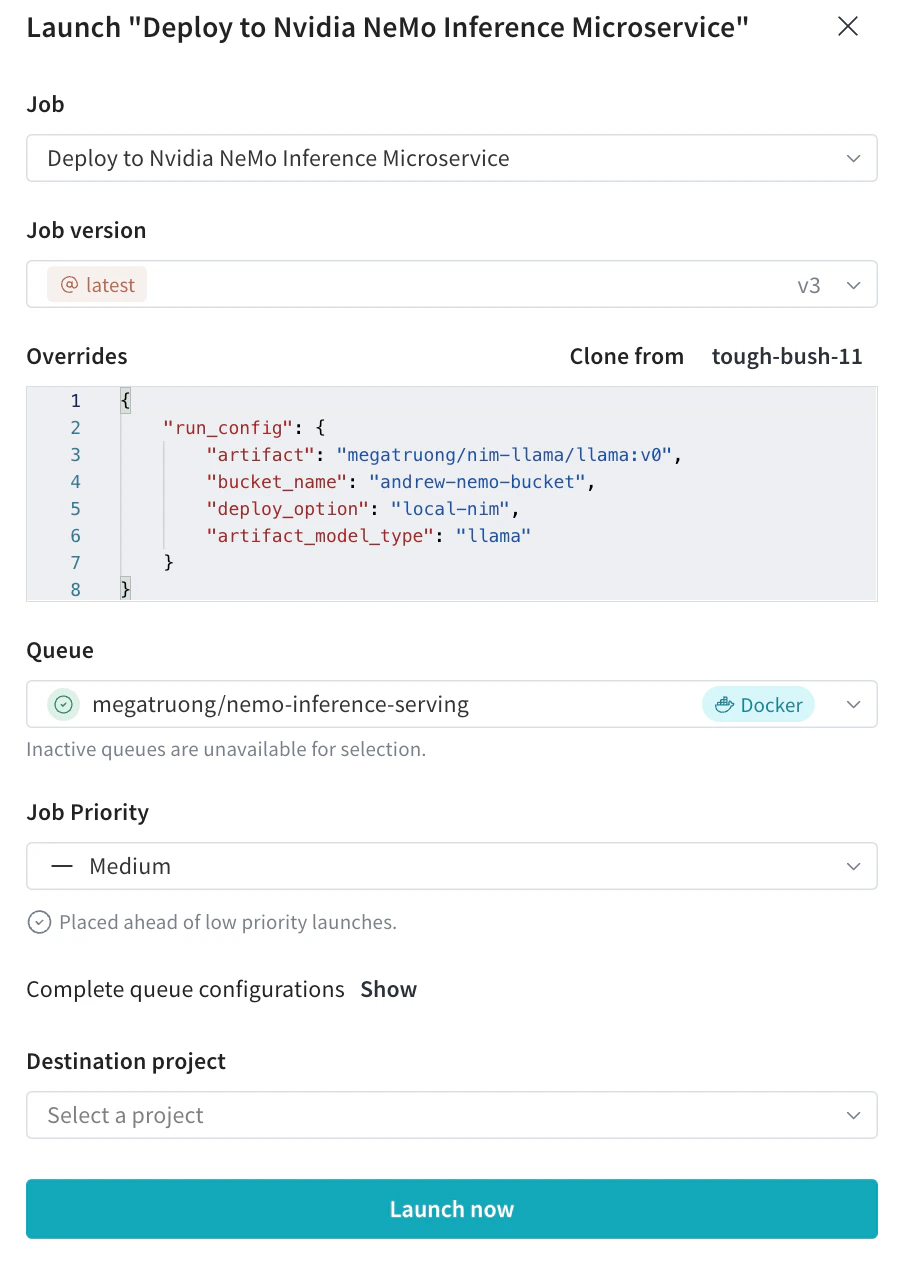
-
Launch UI에서 배포 진행 상황을 추적할 수 있습니다.
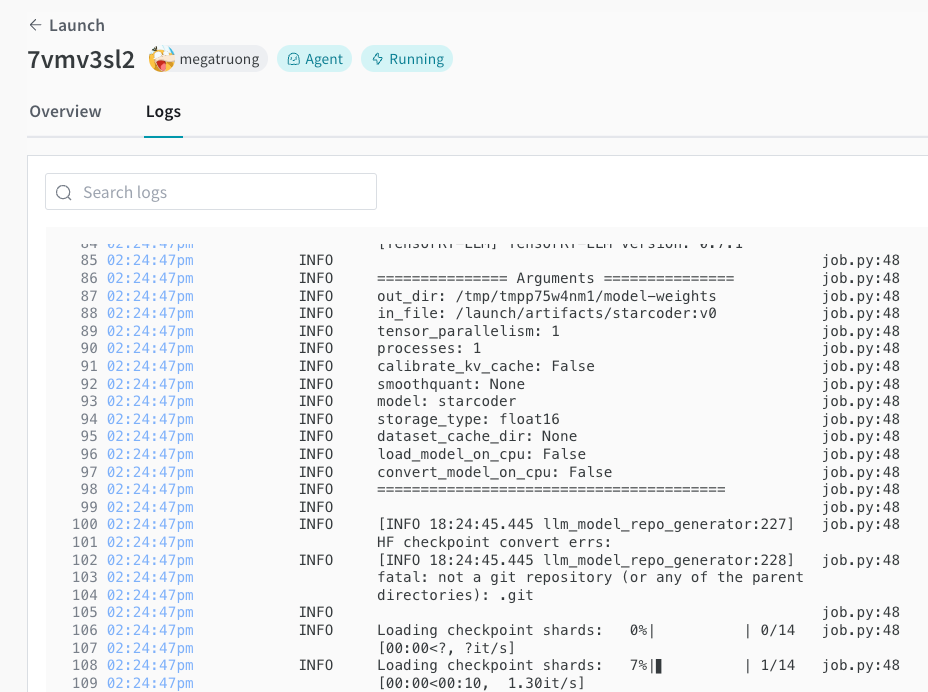
-
배포가 완료되면 NIM/Triton 엔드포인트가 모델을 서빙하며, 추론 요청을 받을 준비가 됩니다. 모델을 테스트하려면 엔드포인트에
curl요청을 보내세요. 모델 이름은 항상ensemble입니다.