이것은 대화형 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다:
- PII 데이터를 식별하고 마스킹하기 위한 정규 표현식
- Python 기반 데이터 보호 SDK인 Microsoft의 Presidio. 이 도구는 마스킹 및 대체 기능을 제공합니다.
- 가짜 데이터를 생성하는 Python 라이브러리인 **Faker**와 Presidio를 함께 사용해 PII 데이터를 익명화하는 방법
weave.op 입력/출력 로깅 사용자 지정 및 _autopatch_settings_를 사용해 워크플로에 PII 마스킹과 익명화를 통합하는 방법도 알아봅니다. 자세한 내용은 Customize logged inputs and outputs를 참조하세요.
시작하려면 다음을 수행하세요:
- Overview 섹션을 검토합니다.
- 사전 요구 사항을 완료합니다.
- PII 데이터를 식별하고, 마스킹하고, 익명화하는 사용 가능한 방법을 검토합니다.
- 이 방법을 Weave Call에 적용합니다.
Overview
weave.op을 사용한 입력 및 출력 로깅의 개요와 Weave에서 PII 데이터를 다룰 때의 모범 사례를 설명합니다.
weave.op을 사용하여 입력 및 출력 로깅 사용자 지정하기
weave.op()에 인수로 전달합니다.
PII 데이터와 함께 Weave를 사용할 때의 모범 사례
테스트 중에는
- PII 감지를 확인하기 위해 익명화된 데이터를 로깅합니다.
- Weave 트레이스로 PII 처리 과정을 추적합니다.
- 실제 PII를 노출하지 않고도 익명화 성능을 측정합니다.
프로덕션 환경에서
- 원본 PII는 절대 로깅하지 마세요.
- 로깅하기 전에 민감한 필드는 암호화하세요.
암호화 팁
- 나중에 복호화해야 하는 데이터에는 가역 암호화를 사용하세요.
- 되돌릴 필요가 없는 고유 ID에는 단방향 해시를 적용하세요.
- 암호화된 상태에서 분석해야 하는 데이터에는 특수한 암호화 방식을 고려하세요.
사전 요구 사항
- 먼저 필요한 패키지를 설치하세요.
- 다음 위치에서 API 키를 생성하세요:
- Weave 프로젝트를 초기화하세요.
- 텍스트 블록 10개가 포함된 데모 PII 데이터셋을 로드하세요.
마스킹 방법 Overview
- PII 데이터를 파악하고 마스킹하는 정규 표현식.
- 마스킹 및 대체 기능을 제공하는 Python 기반 데이터 보호 SDK인 Microsoft Presidio.
- 가짜 데이터를 생성하는 Python 라이브러리인 Faker.
방법 1: 정규 표현식을 사용한 필터링
방법 2: Microsoft Presidio를 사용해 PII 마스킹하기
"My name is Alex"에서 Alex를 <PERSON>으로 바꿉니다.
Presidio는 일반적인 entity를 기본적으로 지원합니다. 다음 예시에서는 PHONE_NUMBER, PERSON, LOCATION, EMAIL_ADDRESS, US_SSN인 모든 entity를 마스킹합니다. Presidio 처리 과정은 함수로 캡슐화되어 있습니다.
방법 3: Faker와 Presidio를 사용해 대체값으로 익명화하기
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
Presidio와 Faker가 데이터를 처리한 후에는 다음과 같이 보일 수 있습니다.
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio와 Faker를 함께 사용하려면 맞춤형 operator에 대한 참조를 제공해야 합니다. 이 operator는 PII를 가짜 데이터로 바꾸는 역할을 하는 Faker 함수로 Presidio를 연결해 줍니다.
방법 4: autopatch_settings 사용
autopatch_settings를 사용할 수 있습니다. W&B는 특정 인테그레이션의 모든 Call 전반에서 PII 처리를 중앙 집중식으로 관리하려는 경우 이 접근 방식을 권장합니다. 이 방법의 장점은 다음과 같습니다.
- PII 처리 로직을 초기화 시점에 중앙에서 관리하고 범위를 지정할 수 있어, 여기저기 흩어진 맞춤형 로직의 필요성이 줄어듭니다.
- 특정 인테그레이션에 대해 PII 처리 워크플로를 사용자 지정하거나 완전히 비활성화할 수 있습니다.
autopatch_settings를 사용해 PII 처리를 구성하려면, 지원되는 LLM 인테그레이션 중 하나의 op_settings에서 postprocess_inputs 또는 postprocess_output을 정의하세요.
메서드를 Weave Call에 적용하기
Regex 방법
Presidio 마스킹 방법
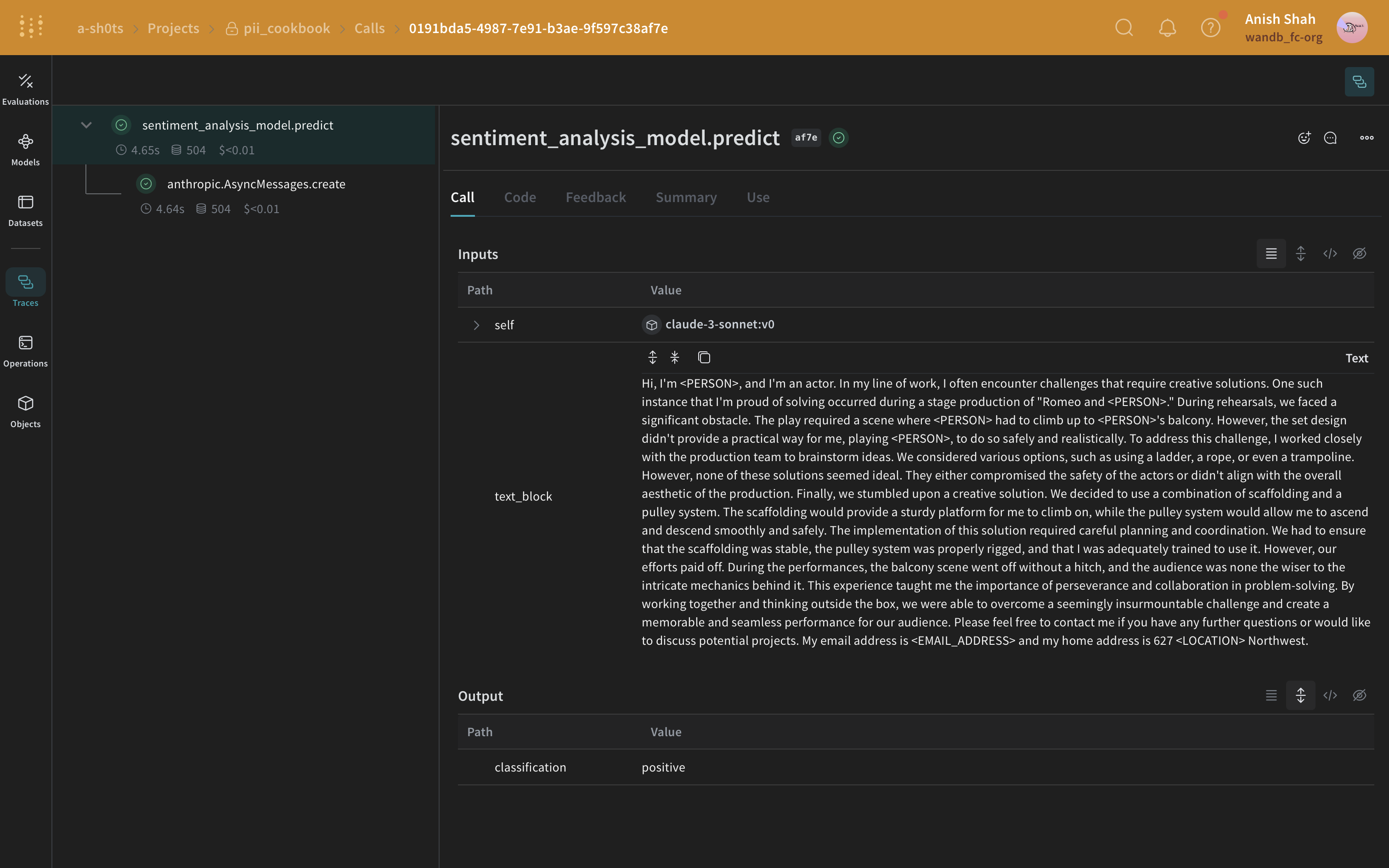
Faker 및 Presidio 대체 방법
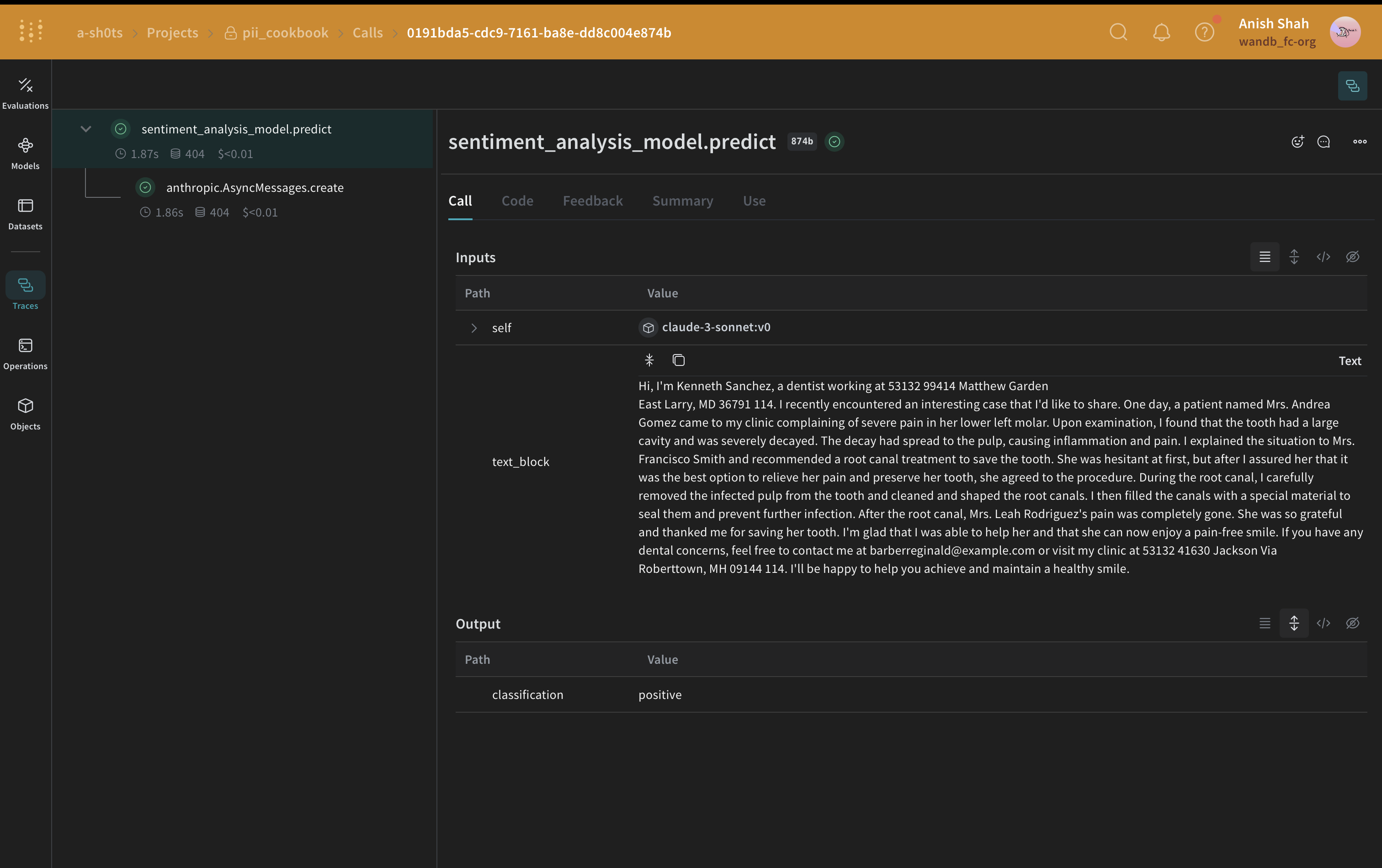
autopatch_settings 방법
anthropic의 postprocess_inputs를 postprocess_inputs_regex() 함수로 설정합니다. postprocess_inputs_regex 함수는 방법 1: 정규 표현식을 사용한 필터링에 정의된 redact_with_regex 방법을 적용합니다. 그 결과, 모든 anthropic 모델에 대한 모든 입력에 redact_with_regex가 적용됩니다.
선택 사항: 데이터를 암호화하세요
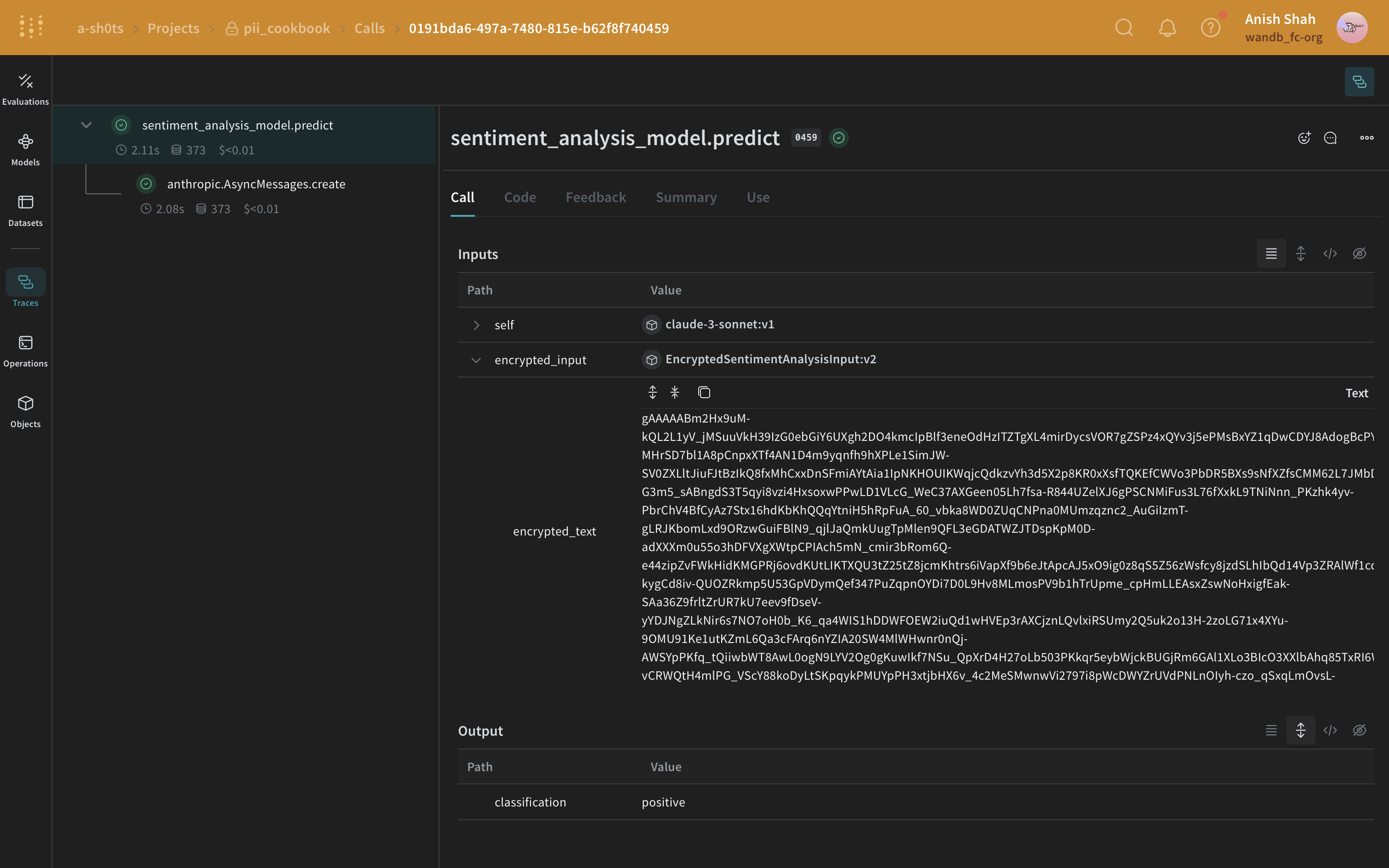
predict 메서드 내부에서 이를 복호화하는 방법을 보여줍니다.