import os
import asyncio
import openai
import weave
from weave.flow import leaderboard
from weave.trace.ref_util import get_ref
# Définir l'équipe et le projet Weave pour le suivi
weave.init("[YOUR-TEAM]/[YOUR-PROJECT]")
dataset = [
{"input": "What is 2 + 2?", "target": "4"},
{"input": "Name a primary color.", "target": "red"},
]
@weave.op
def exact_match(target: str, output: str) -> float:
return float(target.strip().lower() == output.strip().lower())
class WBInferenceModel(weave.Model):
model: str
@weave.op
def predict(self, prompt: str) -> str:
client = openai.OpenAI(
base_url="https://api.inference.wandb.ai/v1",
# Créez une clé API sur https://wandb.ai/settings
api_key="[YOUR-API-KEY]",
# Facultatif : équipe et projet pour le suivi de l'utilisation
project="[YOUR-TEAM]/[YOUR-PROJECT]",
)
resp = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
llama = WBInferenceModel(model="meta-llama/Llama-3.1-8B-Instruct")
deepseek = WBInferenceModel(model="deepseek-ai/DeepSeek-V3-0324")
def preprocess_model_input(example):
return {"prompt": example["input"]}
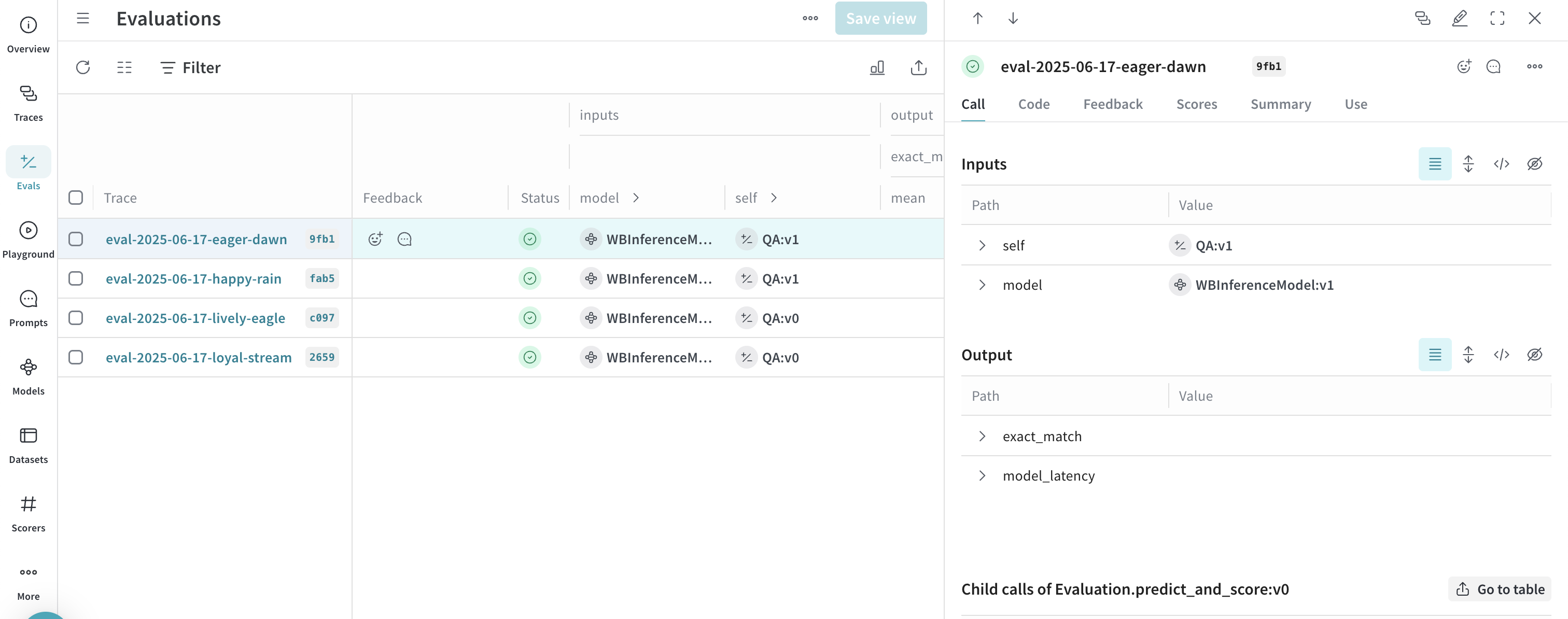
evaluation = weave.Evaluation(
name="QA",
dataset=dataset,
scorers=[exact_match],
preprocess_model_input=preprocess_model_input,
)
async def run_eval():
await evaluation.evaluate(llama)
await evaluation.evaluate(deepseek)
asyncio.run(run_eval())
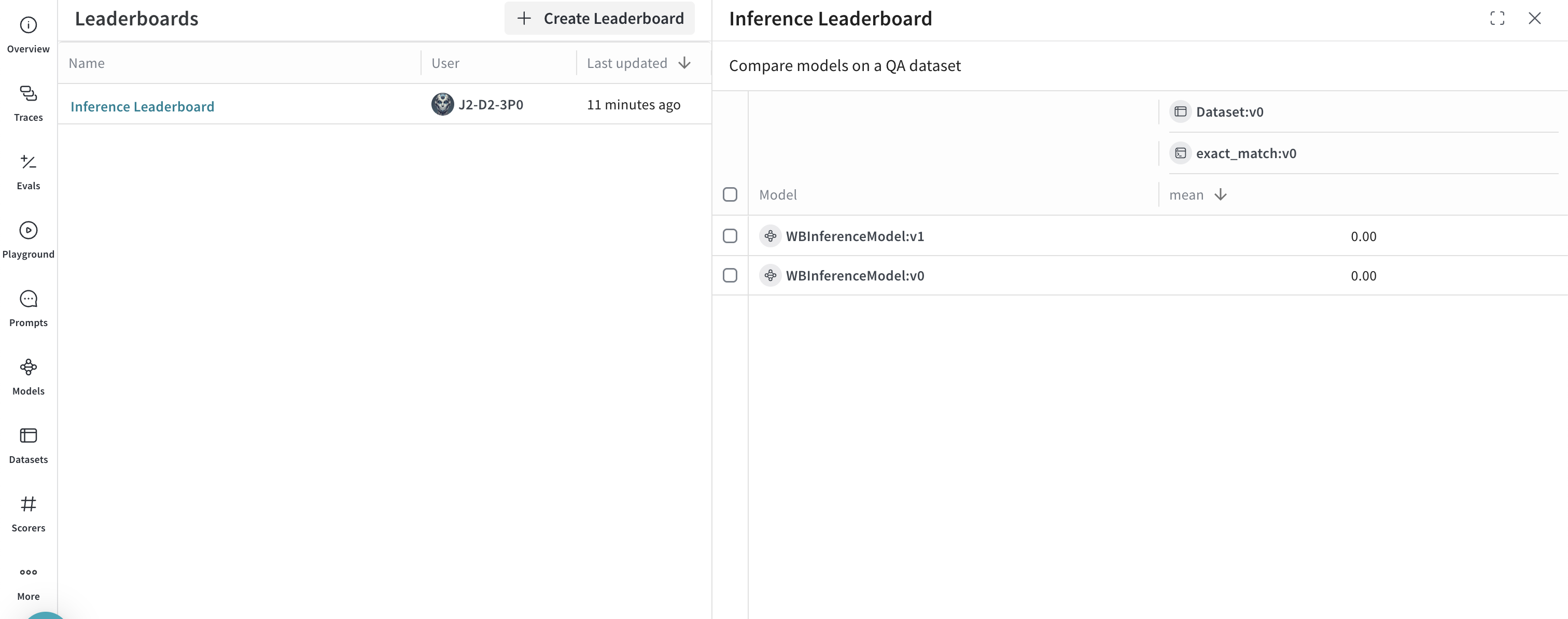
spec = leaderboard.Leaderboard(
name="Inference Leaderboard",
description="Compare models on a QA dataset",
columns=[
leaderboard.LeaderboardColumn(
evaluation_object_ref=get_ref(evaluation).uri(),
scorer_name="exact_match",
summary_metric_path="mean",
)
],
)
weave.publish(spec)