LLM 評価ジョブは、W&B Multi-tenant Cloud でプレビュー版として提供されています。プレビュー期間中は、コンピュートを無料で利用できます。詳細については、LLM 評価ジョブの pricingを参照してください。
事前準備
- LLM 評価ジョブの要件と制限事項を確認します。
- 特定のベンチマークを実行するには、チーム管理者が必要な APIキー をチームスコープのシークレットとして追加しておく必要があります。評価ジョブの設定時には、どのチームメンバーでもそのシークレットを指定できます。
- OpenAI APIキー: スコアリングに OpenAI モデルを使用するベンチマークで使われます。ベンチマークを選択した後に Scorer APIキー フィールドが表示される場合は必須です。シークレット名は
OPENAI_API_KEYである必要があります。 - Hugging Face ユーザーアクセストークン: 1 つ以上の制限付き Hugging Face データセットへのアクセスが必要な
lingolyやlingoly2など、一部のベンチマークで必須です。ベンチマークを選択した後に Hugging Face Token フィールドが表示される場合は必須です。APIキーには、該当するデータセットへのアクセス権が必要です。ユーザーアクセストークンおよび制限付きデータセットへのアクセスについては、Hugging Face のドキュメントを参照してください。 - Serverless Inference が提供するモデルを評価するには、組織またはチーム管理者が
WANDB_API_KEYを任意の値で作成する必要があります。このシークレットは認証には使用されません。
- OpenAI APIキー: スコアリングに OpenAI モデルを使用するベンチマークで使われます。ベンチマークを選択した後に Scorer APIキー フィールドが表示される場合は必須です。シークレット名は
- 評価対象のモデルは、公開アクセス可能な URL で利用できる必要があります。組織またはチーム管理者は、認証用の APIキー を含むチームスコープのシークレットを作成する必要があります。
- 評価結果用に新しいW&B プロジェクトを作成します。プロジェクトのサイドバーで Create new project をクリックします。
- 各ベンチマークの仕組みを理解し、個別の要件を確認するために、そのベンチマークのドキュメントを確認します。利用可能な評価ベンチマークのリファレンスには関連リンクが含まれています。
モデルを評価する
- W&B にログインし、プロジェクトのサイドバーで Launch をクリックします。LLM 評価ジョブ ページが表示されます。
- Evaluate ホスト型 API モデル をクリックして、評価を設定します。
- 評価結果の保存先となる project を選択します。
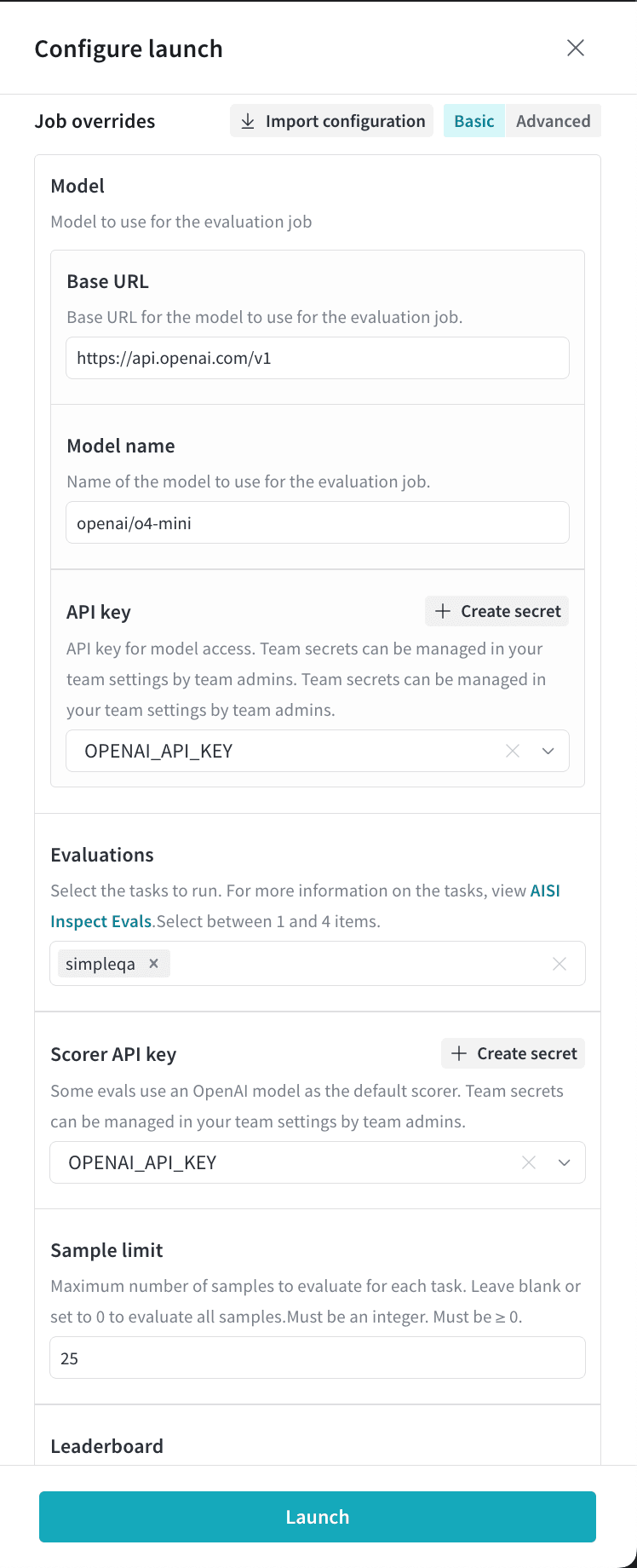
- Model セクションで、評価するベース URL とモデル名を指定し、認証に使用する APIキー を選択します。モデル名は、AI Security Institute で定義されている OpenAI 互換形式で指定してください。たとえば、OpenAI モデルは
[MODEL-NAME]をモデル名として、次の構文で指定します:openai/[MODEL-NAME]。hosted モデルの providers とモデルの一覧については、AI Security Institute’s model provider reference を参照してください。- Serverless Inference が提供するモデルを評価するには、ベース URL を
https://api.inference.wandb.ai/v1に設定し、[MODEL-ID]をモデル ID として、次の構文でモデル名を指定します:openai-api/wandb/[MODEL-ID]。詳細は Inference model catalog を参照してください。 - OpenRouter provider を使用するには、
[MODEL-NAME]をモデル名として、次の構文でモデル名の先頭にopenrouterを付けます:openrouter/[MODEL-NAME]。 - custom な OpenAPI 準拠モデルを評価するには、
[MODEL-NAME]をモデル名として、次の構文でモデル名を指定します:openai-api/wandb/[MODEL-NAME]。
- Serverless Inference が提供するモデルを評価するには、ベース URL を
- Select evaluations をクリックし、実行するベンチマークを最大 4 つ選択します。
- スコアリングに OpenAI モデルを使用するベンチマークを選択すると、Scorer APIキー フィールドが表示されます。これをクリックして、
OPENAI_API_KEYシークレットを選択します。チーム管理者は、Create secret をクリックしてこの drawer から シークレット を作成できます。 - Hugging Face の gated dataset への access が必要なベンチマークを選択すると、Hugging Face token フィールドが表示されます。該当するデータセットへの access をリクエスト してから、Hugging Face ユーザーのアクセストークンを含む シークレット を選択します。
- 任意: Sample limit に正の整数を設定すると、評価するベンチマークサンプルの最大数を制限できます。設定しない場合は、タスク内のすべてのサンプルが対象になります。
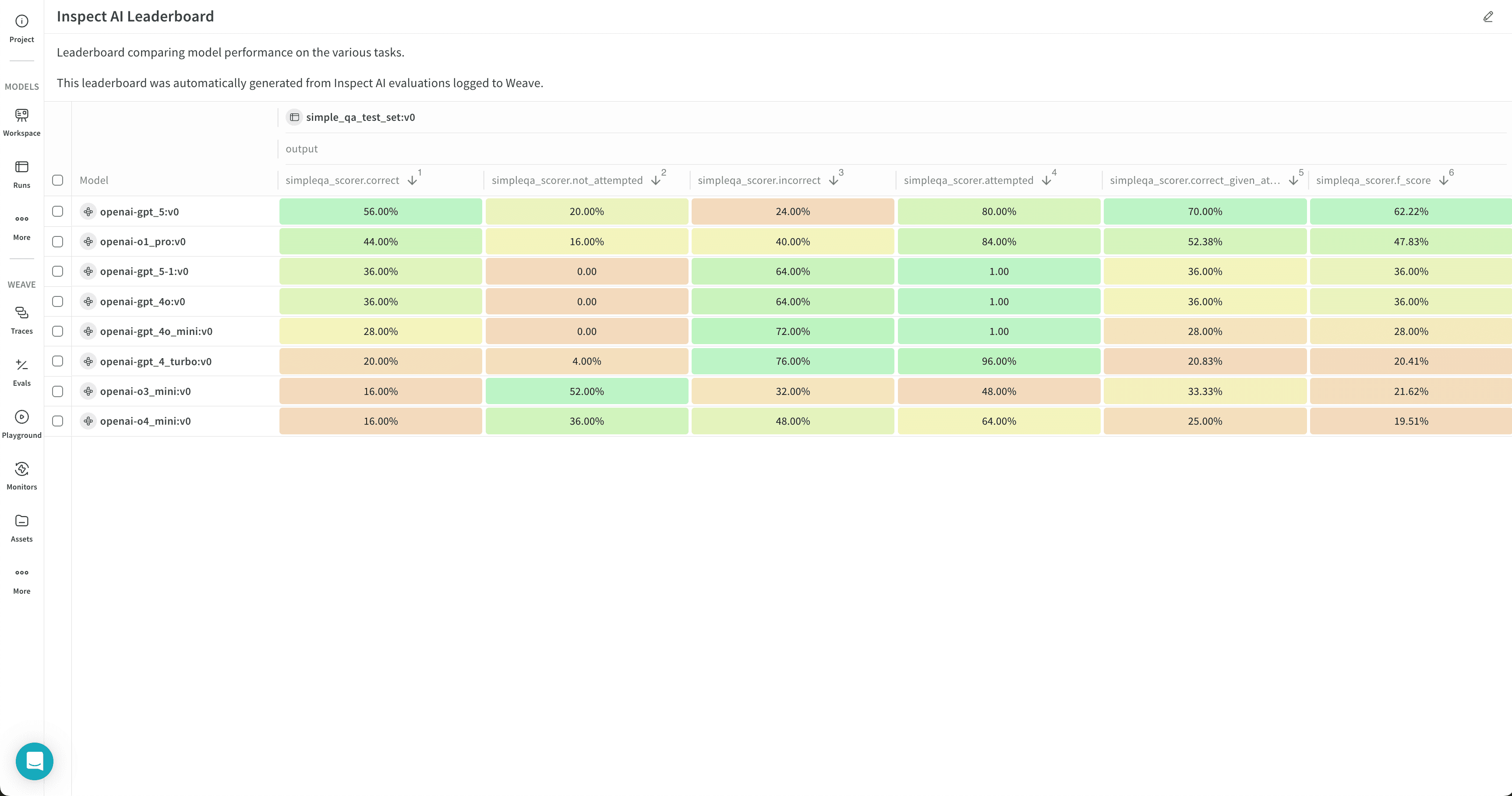
- リーダーボードを自動的に作成するには、Publish results to leaderboard をクリックします。リーダーボードには、すべての評価が Workspace パネルにまとめて表示され、report で共有することもできます。
- Launch をクリックして、評価ジョブを起動します。
- ページ上部の円形矢印アイコンをクリックして、最近の run のモーダルを開きます。評価ジョブは、ほかの最近の Runs と一緒に表示されます。完了した run の名をクリックすると単一 run ビューで開き、Leaderboard リンクをクリックするとリーダーボードを直接開けます。詳細は、結果を表示する を参照してください。
o4-mini に対して simpleqa ベンチマークを実行します:
評価結果を確認する
- ページ上部の円形矢印アイコンをクリックして、最近の run を表示するモーダルを開きます。ここでは、評価ジョブがプロジェクト内の他の run と一緒に表示されます。評価ジョブにリーダーボードがある場合は、Leaderboard をクリックして全画面で開くか、run 名をクリックしてプロジェクト内の単一 run ビューで開きます。
- 評価ジョブのトレースは、ワークスペースの Evaluations セクション、または Weave サイドバーパネルの Traces タブで確認できます。
- Overview タブをクリックすると、設定やサマリー メトリクスを含む評価ジョブの詳細情報を確認できます。
- Logs タブをクリックすると、評価ジョブのデバッグログを表示、検索、またはダウンロードできます。
- Files タブをクリックすると、コード、ログ、設定、その他の出力ファイルを含む評価ジョブのファイルを参照、表示、またはダウンロードできます。
リーダーボードをカスタマイズする
- デフォルトでは、すべての評価ジョブが表示されます。左側の run selector を使用して、評価ジョブをフィルターまたは検索できます。
- デフォルトでは、評価ジョブはグループ化されていません。1 つ以上の列でグループ化するには、Group アイコンをクリックします。グループの表示/非表示を切り替えたり、グループを展開してその Runs を表示したりできます。
- デフォルトでは、すべてのオペレーションが表示されます。1 つのオペレーションだけを表示するには、All ops をクリックしてオペレーションを選択します。
- 列で並べ替えるには、列見出しをクリックします。列の表示をカスタマイズするには、Columns をクリックします。
- デフォルトでは、ヘッダーは 1 階層で構成されています。ヘッダーの深さを増やすと、関連するヘッダーをまとめて整理できます。
- 個々の列を選択または選択解除して表示/非表示を切り替えるか、クリック 1 回ですべての列を表示または非表示にできます。
- 列を固定すると、固定していない列より前に表示できます。
リーダーボードをエクスポートする
- Columns ボタンの近くにあるダウンロードアイコンをクリックします。
- エクスポートサイズを抑えるため、デフォルトでは W&B によりトレースルートのみがエクスポートされます。完全なトレースをエクスポートするには、Trace roots only をオフにします。
- エクスポートサイズを抑えるため、デフォルトでは W&B はフィードバックとコストをエクスポートしません。これらをエクスポートに含めるには、Feedback または Costs をオンにします。
- デフォルトのエクスポート形式は JSONL です。形式を変更するには、Export to file をクリックして形式を選択します。
- ブラウザーでリーダーボードをエクスポートするには、Export をクリックします。
- リーダーボードをプログラムからエクスポートするには、Python または cURL を選択し、Copy をクリックしてからスクリプトまたは command を実行します。
評価ジョブを再実行する
- 直前の評価ジョブを再実行するには、モデルを評価する の手順に従います。保存先のプロジェクトを選択すると、前回選択したモデル artifact の詳細とベンチマークが自動的に入力されます。必要に応じて調整してから、評価ジョブを起動します。
- プロジェクトの Runs タブまたは run selector から評価ジョブを再実行するには、run 名にカーソルを合わせて 再生 アイコンをクリックします。設定が事前入力された状態でジョブ設定ドロワーが表示されます。必要に応じて設定を調整し、Launch をクリックします。
- 別のプロジェクトから評価ジョブを再実行するには、その設定をインポートします:
- モデルを評価する の手順に従います。保存先のプロジェクトを選択したら、Import configuration をクリックします。
- インポートする評価ジョブが含まれるプロジェクトを選択し、次にその評価ジョブの run を選択します。設定が事前入力された状態でジョブ設定ドロワーが表示されます。
- 任意: 設定を調整します。
- Launch をクリックします。
評価ジョブの設定をエクスポートする
config.yaml のローカル コピーを保存するには、run の Files タブから設定をエクスポートします。
- 単一 run ビューで run を開きます。
- run 内で Files を選択します。
config.yamlの横にあるダウンロード ボタンを選択します。