- モデル性能のリグレッションをトラッキングする。
- 共有の評価ワークフローを調整する。
リーダーボード を作成できるのは、Weave UI と Weave Python SDK のみです。TypeScript ユーザーは、Weave UI を使用して リーダーボード を作成および管理できます。
リーダーボードを作成する
UI を使う
- Weave UI で、Leaders セクションにアクセスします。表示されていない場合は、More → Leaders をクリックします。
- + New Leaderboard をクリックします。
- Leaderboard Title フィールドに、わかりやすい名 (例:
summarization-benchmark-v1) を入力します。 - 必要に応じて、このリーダーボードで何を比較するのかがわかる説明を追加します。
- 表示する評価とメトリクスを定義するために、列を追加します。
- レイアウトの準備ができたら、リーダーボードを保存して公開し、他のユーザーと共有します。
列を追加
- 評価: ドロップダウンから評価 run を選択します (事前に作成されている必要があります) 。
- Scorer: その評価で使用するスコアリング関数 (たとえば
jaccard_similarityまたはsimple_accuracy) を選択します。 - メトリクス: 表示するサマリー メトリクス (たとえば
meanまたはtrue_fraction) を選択します。
- 前または後に移動. 列の順序を変更します。
- 複製. 列の定義をコピーします。
- 削除. 列を削除します。
- 昇順で並べ替え. リーダーボードのデフォルトの並べ替え順を設定します (もう一度クリックすると降順に切り替わります) 。
Python SDK を使用する
-
テスト用データセットを定義します。組み込みの
Datasetを使用することも、input と target のリストを手動で定義することもできます。 -
1 つ以上のScorerを定義します。
-
評価を作成します。 -
評価するモデルを定義します。
-
評価を実行します。
-
リーダーボードを作成します。
-
リーダーボードを公開します。
-
結果を取得します。
エンドツーエンドの Python の例
リーダーボード を表示して読み解く
- Weave UI で Leaders タブに移動します。表示されていない場合は、More をクリックして Leaders を選択します。
- リーダーボード の名をクリックします。たとえば
Summarization Model Comparison。
model_humanlike、model_vanilla、model_messy) を表します。mean 列には、モデルの出力と参照サマリーの間のジャッカード類似度の平均が表示されます。
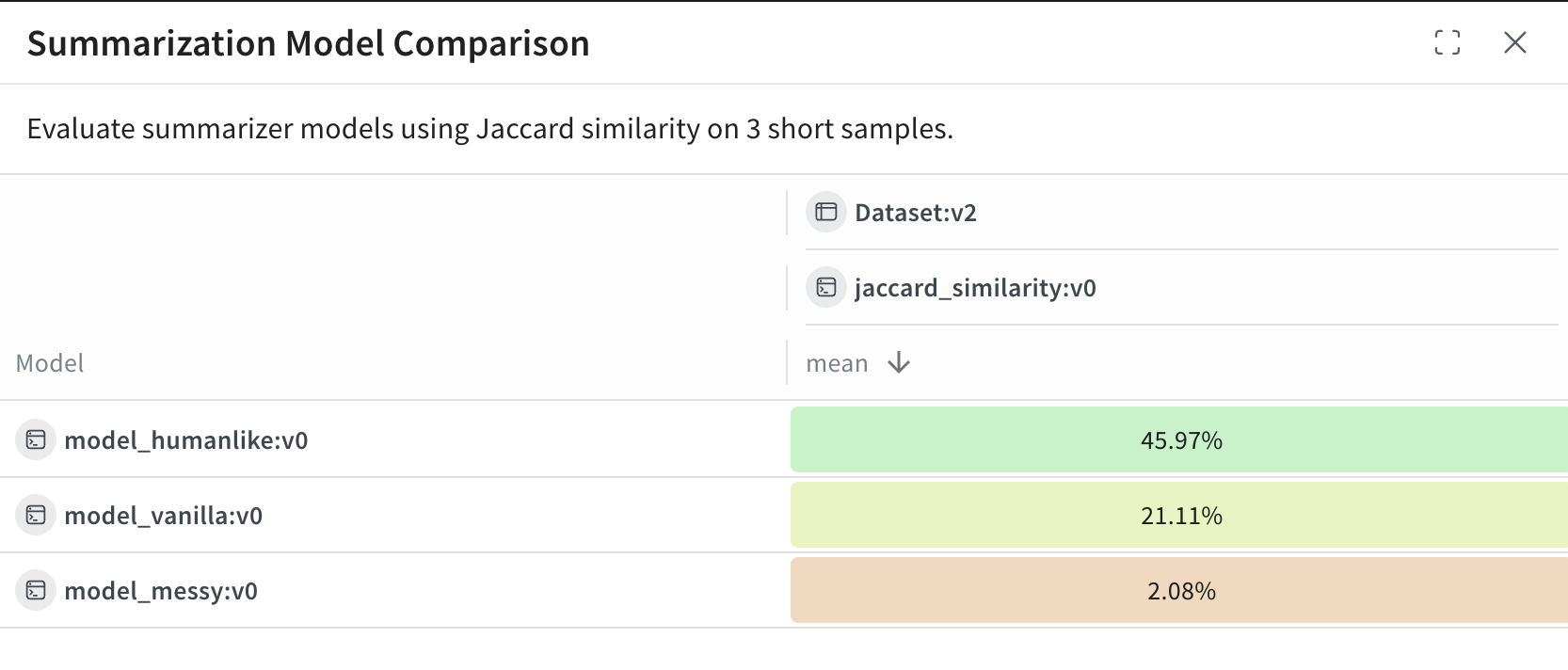
model_humanlikeが最も良い結果で、重複率は約 46 パーセントです。model_vanilla(単純な切り詰め) は約 21 パーセントです。model_messyは意図的に性能を悪くしたモデルで、スコアは約 2 パーセントです。