Dataset は、プログラムからも UI からも作成して操作できます。
このページは、コードまたは Weave UI を通じて評価データを管理したいエンジニアやチームメンバーを対象としています。内容は次のとおりです。
- Python と TypeScript での基本的な
Datasetの操作と、使い始める方法。 - Weave の Call などのオブジェクトから、Python と TypeScript で
Datasetを作成する方法。 - UI で
Datasetに対して使用できる操作。
Dataset クイックスタート
Dataset 操作を実行する方法を示します。SDK を使用すると、次のことができます。
Datasetを作成するDatasetを公開するDatasetを取得するDataset内の特定の例にアクセスする
- Python
- TypeScript
他のオブジェクトからデータセットを作成する
Dataset を作成する方法を示します。これにより、例を手動で再入力する必要がなくなります。
- Python
- TypeScript
Python では、次に、
Dataset は Call のような一般的な Weave オブジェクトや、pandas.DataFrame のような Python オブジェクトから作成することもできます。この機能は、特定の例から例示用の Dataset を作成したい場合に便利です。Weave Call
1 つ以上の Weave Call からDataset を作成するには、Call オブジェクトを取得し、from_calls method に list として渡します。Pandas DataFrame
Pandas のDataFrame object から Dataset を作成するには、from_pandas method を使用します。Dataset を Pandas に戻すには、to_pandas を使用します。Hugging Face Datasets
Hugging Face のdatasets.Dataset または datasets.DatasetDict object から Dataset を作成するには、まず必要な dependencies がインストールされていることを確認します。from_hf method を使用します。複数の split (‘train’、‘test’、‘validation’ など) を持つ DatasetDict を指定すると、Weave は自動的に ‘train’ split を使用し、警告を表示します。‘train’ split が存在しない場合はエラーになります。特定の split を直接指定することもできます (例: hf_dataset_dict['test']) 。weave.Dataset を Hugging Face の Dataset に戻すには、to_hf method を使用します。UI でデータセットを作成、編集、削除する
Dataset は UI で作成、編集、削除できます。Weave UI でデータセットを作成すると、コードを編集しなくても、あなたやチームの非エンジニアのメンバーが、例や質問、そのほかのエージェント テスト用データを含む共有可能なデータセットを作成し、キュレーションできます。
以下の手順では、UI でこれらの各タスクを実行する方法を順に説明します。ノートブックやスクリプトではなく、元になったトレースとあわせて評価データを管理したい場合に使用してください。
新しいデータセットを作成する
Dataset を作成します。完了すると、評価で参照したりチームと共有したりできる公開済みの Dataset が作成されます。
- 編集する Weave プロジェクトにアクセスします。
- サイドバーで Traces を選択します。
-
新しい
Datasetを作成する対象の call を1つ以上選択します。 - 右上のメニューで、Add selected rows to a dataset アイコン (ごみ箱アイコンの横にあります) をクリックします。
- Choose a dataset ドロップダウンで、Create new を選択します。Dataset name フィールドが表示されます。
-
Dataset name フィールドにデータセット名を入力します。Configure dataset fields のオプションが表示されます。
Dataset 名は英字または数字で始める必要があり、使用できるのは英字、数字、ハイフン、アンダースコアのみです。
-
任意: Configure dataset fields で、データセットに含める call のフィールドを選択します。
- 選択した各フィールドの列名はカスタマイズできます。
- 新しい
Datasetに含めるフィールドを一部だけ選択することも、すべてのフィールドの選択を解除することもできます。
-
データセットフィールドの設定が完了したら、Next をクリックします。新しい
Datasetのプレビューが表示されます。 - 任意: Dataset 内の編集可能なフィールドをクリックして、エントリを編集します。
- Create dataset をクリックします。Weave により新しいデータセットが作成されます。
-
確認ポップアップで、View the dataset をクリックして新しい
Datasetを表示します。別の方法として、Datasets タブに移動することもできます。
データセットを編集する
Dataset に新しい行を追加し、新しいバージョンを公開するには、次の手順を実行します。UI での編集は、コードを変更せずに評価データを拡張または修正したい場合に役立ちます。
-
編集する
Datasetが含まれている Weave プロジェクトにアクセスします。 -
サイドバーで Datasets を選択します。利用可能な
Datasetが表示されます。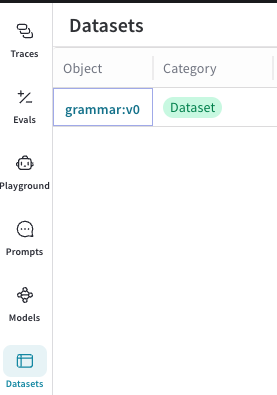
-
Object 列で、編集する
Datasetの名前とバージョンをクリックします。名前、バージョン、作成者、Datasetの行などの情報が表示されたポップアウト モーダルが開きます。
-
モーダルの右上にある Edit dataset ボタン (鉛筆アイコン) をクリックします。モーダルの下部に + Add row ボタンが表示されます。

-
+ Add row をクリックします。既存の
Datasetの行の上に新しい行が表示され、Datasetに新しい行を追加できることを示します。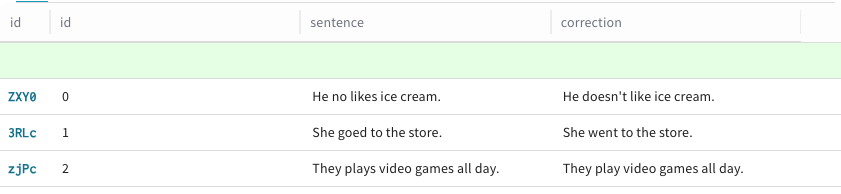
-
新しい行にデータを追加するには、その行の追加先の列をクリックします。
Datasetの行にあるデフォルトの id 列は、Weave によって作成時に自動的に割り当てられるため、編集できません。編集モーダルが表示され、書式設定用の Text、Code、Diff オプションを選択できます。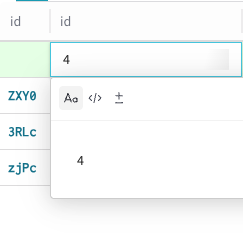
-
新しい行でデータを追加する各列について、step 6 を繰り返します。
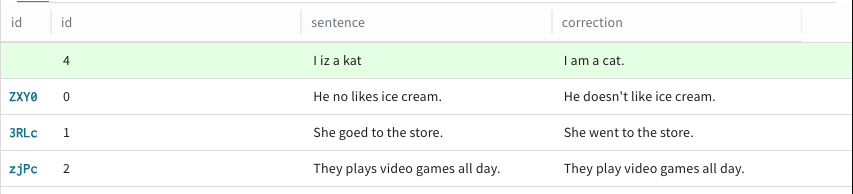
-
Datasetに追加する各行について、step 5 を繰り返します。 -
編集が完了したら、モーダルの右上にある Publish をクリックして
Datasetを公開します。変更を公開しない場合は、Cancel をクリックします。
Datasetを UI で利用できます。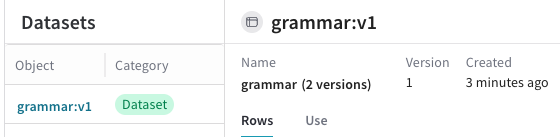

データセットを削除する
Dataset を Weave プロジェクトから削除する場合は、以下の手順を使用します。
-
削除したい
Datasetが含まれる Weave プロジェクトにアクセスします。 -
サイドバーから Datasets を選択します。利用可能な
Datasetが表示されます。 -
Object 列で、削除する
Datasetの名前とバージョンをクリックします。名前、バージョン、作成者、Datasetの行などの情報を表示するポップアウト モーダルが開きます。 -
モーダルの右上にあるゴミ箱アイコンをクリックします。
Datasetの削除確認を求めるポップアップモーダルが表示されます。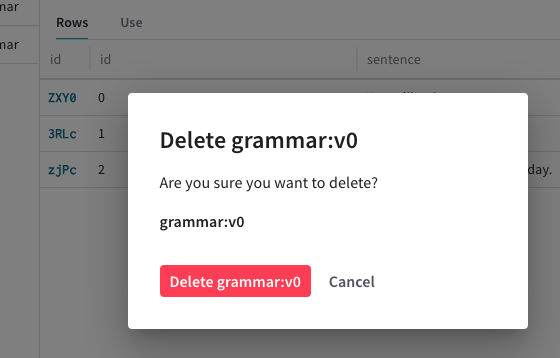
-
ポップアップモーダルで、
Datasetを削除するには Delete をクリックします。削除したくない場合は、Cancel をクリックします。Datasetは削除され、Weave ダッシュボードの Datasets タブには表示されなくなります。
新しいエージェントのトレースを Dataset に追加する
Dataset に追加するには、エージェントメッセージをデータセットに追加する を参照してください。
データセットに新しいトレースを追加する
@weave.op デコレータを使用する Ops と Calls から生成されたトレースを Dataset に追加するには:
- 編集したい Weave プロジェクトにアクセスします。
- サイドバーで Traces を選択します。
-
新しい例を作成したい
Datasetsを含む Call を 1 つ以上選択します。 - 右上のメニューで、Add selected rows to a dataset アイコン (ごみ箱アイコンの横) をクリックします。必要に応じて Show latest versions をオフにすると、利用可能なすべてのデータセットの全バージョンが表示されます。
-
Choose a dataset ドロップダウンから、例を追加する
Datasetを選択します。Configure field mapping オプションが表示されます。 - 任意: Configure field mapping では、Call のフィールドを対応するデータセット列にどうマッピングするかを調整できます。
-
フィールドマッピングの設定が完了したら、Next をクリックします。新しい
Datasetのプレビューが表示されます。 - 空の行 (緑色) に、新しい例の値を追加します。id フィールドは編集できず、Weave が自動的に作成します。
- Add to dataset をクリックします。Configure field mapping 画面に戻るには、Back をクリックします。
-
確認ポップアップで、変更を確認するには View the dataset をクリックします。あるいは、Datasets タブにアクセスして
Datasetの更新を確認します。
その他のデータセット操作
Dataset がすでにある場合に役立つ、追加の SDK 操作について説明します。
- Python
- TypeScript
行の選択
select method を使用すると、インデックスを指定して Dataset から特定の行を選択できます。これは、データのサブセットを作成する際に便利です。たとえば、少数の examples の一部に対して Evaluate したい場合に役立ちます。