EvaluationLogger を使用して既存の Python または TypeScript のコードから予測とスコアを記録し、完全なデータセットや scorer 一式を最初に定義しなくても Weave でモデル性能を評価する方法を説明します。
この方法は、データセット全体やすべての scorer を最初に定義できない複雑な workflow で特に役立ちます。
あらかじめ定義した Dataset と Scorer オブジェクトの list が必要な標準の Evaluation オブジェクトとは異なり、EvaluationLogger では個々の予測とそれに関連するスコアを、利用可能になった時点で段階的にログできます。
より構造化された評価をご希望ですか?事前定義されたデータセットと scorer を備えた、より定型的な評価フレームワークを使用したい場合は、Weave の標準 Evaluation フレームワークを参照してください。
EvaluationLogger は柔軟性を重視している一方、標準フレームワークは構造とガイダンスを提供します。基本的なワークフロー
- ロガーを初期化する:
EvaluationLoggerのインスタンスを作成し、必要に応じてmodelとdatasetに関するメタデータを指定します。省略した場合、Weave はデフォルトを使用します。LLM Call (たとえば OpenAI) のトークン使用量とコストを記録するには、LLMを呼び出す前にEvaluationLoggerを初期化してください。 先にLLMを呼び出してから予測をログしても、Weave はトークンとコストのデータを取得しません。 - 予測をログする: システムの各入力/出力ペアに対して
log_prediction()を呼び出します。 - スコアをログする: 返された
ScoreLoggerを使用して、その予測に対するlog_score()を呼び出します。1つの予測に対して複数のスコアをログできます。 - 予測を完了する: 予測を確定するため、スコアをログしたら必ず
finish()を呼び出します。 - サマリーをログする: すべての予測の処理が完了したら、
log_summary()を呼び出してスコアを集計し、必要に応じてカスタムメトリクスを追加します。
log_example() を使用して手順 2~4 を 1 回の呼び出しにまとめることができます。
基本的な例
EvaluationLogger を使用して予測とスコアをログする方法を示しています。
- Python
- TypeScript
user_model モデル関数を定義し、入力のリストに適用します。各例について:- 入力と出力は
log_predictionを使用してログします。 - 正確性スコア (
correctness_score) はlog_scoreを使ってログします。 finish()はその予測のログ記録を完了します。
log_summary は集計メトリクスを記録し、Weave での自動スコア要約をトリガーします。log_example() を使用した簡易ログ記録
log_example() を使用すると、入力、1 つの出力、スコアを 1 回の呼び出しでログできます。この便利なメソッドは、log_prediction()、log_score()、finish() を 1 つのステップにまとめたものです。バッチ評価やオフライン評価のように、ログする入力、モデル出力、スコアがすでにそろっている場合に便利です。
log_example() 呼び出しは、次と同等です:
Weave TypeScript SDK では
log_example() は使用できません。TypeScript ユーザーは、基本例 に示されている logPrediction() と logScore() のパターンを使用してください。高度な使い方
EvaluationLogger は、基本的なワークフローを超えて、より複雑な評価シナリオに対応できる柔軟なパターンを提供します。以下のセクションでは、コンテキストマネージャーを使った自動的なリソース管理、モデル実行とログすることの分離、リッチメディアデータの活用、複数のモデル評価の比較表示などの高度な手法を紹介します。
コンテキストマネージャーを使用する
EvaluationLogger は、予測とスコアの両方でコンテキストマネージャー (with 文) をサポートしています。これにより、コードをより簡潔に保ち、リソースを自動的にクリーンアップし、LLM judge call のようなネストされた操作をより適切にトラッキングできます。
このコンテキストで with 文を使用する主な利点は次のとおりです。
- コンテキストを抜ける際に
finish()が自動的に呼び出される。 - ネストされた LLM call の token と cost の tracking が向上する。
- prediction コンテキスト内で、モデル実行後に output を設定できる。
- Python
- TypeScript
既存のデータセットにリンクする
log_prediction に inputs として渡すと、Weave は評価の run ごとにデータを再インポートします。そのため重複データが保存され、データセットが大きい場合や、多数の評価で再利用する場合には容量の無駄になることがあります。
この重複を避けるには、評価を実行する前にデータセットを Weave に公開し、その公開済みデータセットの行を inputs として渡してください。Weave はデータを再インポートする代わりに、公開済みの行への参照を内部参照として解決します。これにより、標準の Evaluation フレームワーク と同様に、各予測が Weave UI 内の特定のデータセット行にリンクされるようになります。
次の例では、データセットを公開して EvaluationLogger からそれにリンクし、その後は他のデータセットと同様に取得して反復処理します。
- Python
- TypeScript
ログする前に出力を取得する
- Python
- TypeScript
リッチメディアをログする
log_prediction または log_score メソッドに dict またはメディアオブジェクトを渡すだけです。
- Python
- TypeScript
複数の評価をログして比較する
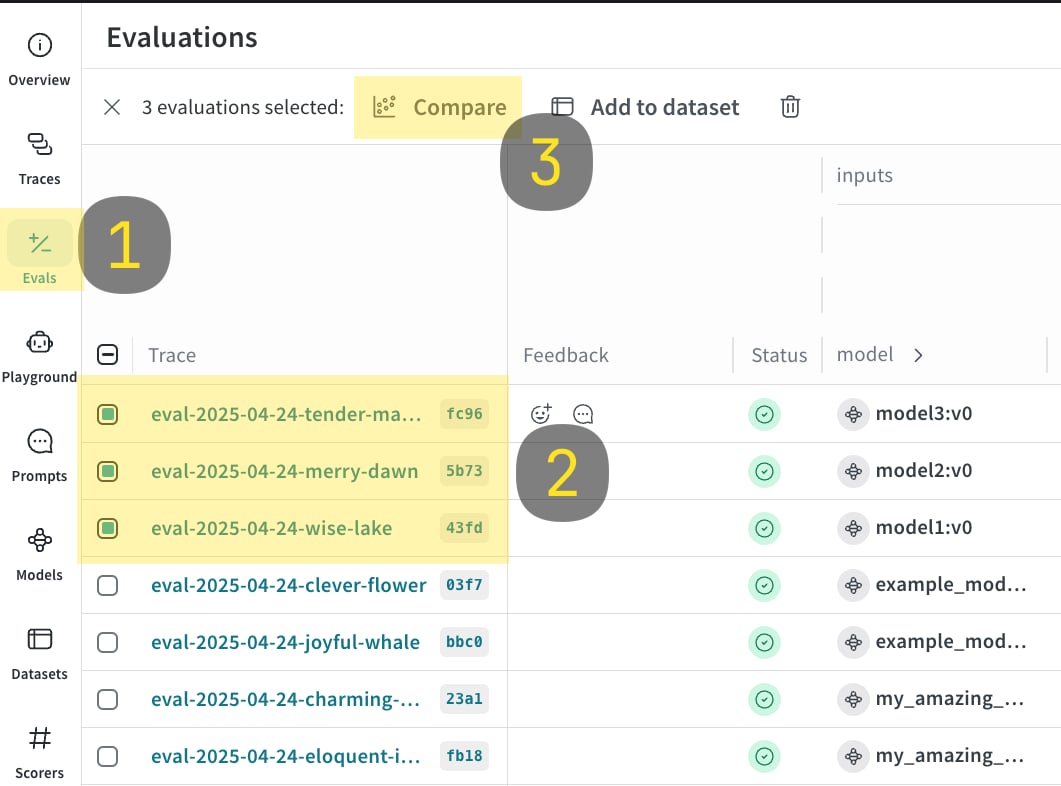
EvaluationLogger を使用すると、複数の評価をログして Weave UI で並べて比較できます。これは、同じデータセットに対して異なるモデルがどのように機能するかを評価する際に役立ちます。
- 以下のコードサンプルを実行します。
-
Weave UI で
Evalsタブにアクセスします。 - 比較したい eval を選択します。
-
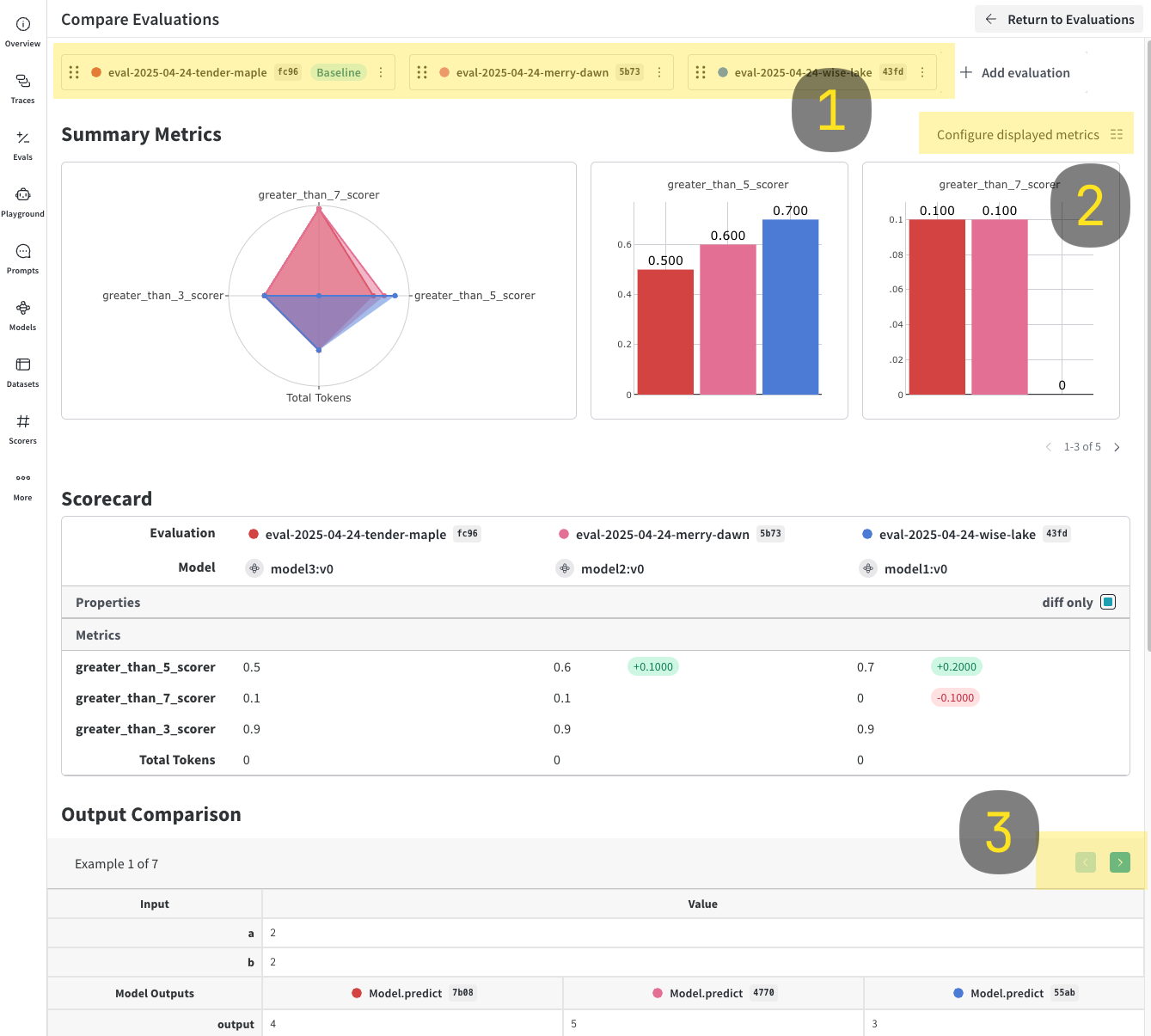
Compare ボタンをクリックします。Compare ビューでは、次のことができます。
- 追加または削除する Evals を選択する。
- 表示または非表示にするメトリクスを選択する。
- 特定の例をページで切り替えながら、同じデータセット内の同じ入力に対して各モデルがどのような結果を返したかを確認する。
- Python
- TypeScript
使用上のヒント
EvaluationLogger を最大限に活用するのに役立ちます。
- Python
- TypeScript
- 各予測の後は、すぐに
finish()を呼び出してください。 log_summaryを使用して、個々の予測に紐づかないメトリクス (たとえば、全体のレイテンシ) を記録します。- リッチメディアのログ記録は、定性的な分析に最適です。