このページでは、本番トラフィックを監視する以前のアプローチについて説明します。新しい実装では、Weave for Agents の Signals を使用してください。エージェント シグナルを表示するを参照してください。
- 自動スコアリング: 本番に入ってくるすべてのトレースが自動的に処理され、一般的な品質上の問題やエラーについてスコアリングされます。
- インフラストラクチャー: 処理は CoreWeave compute と CoreWeave GPUs によって支えられており、数百万件のトレースにもスケーラブルに対応できます。
- 動作に関する洞察を得る。システムメトリクスを超えて、エージェントがハルシネーションを起こしていないか、会話パターンに従えているか、根拠となる証拠に基づいて応答できているかを把握できます。
- リサーチループを加速する。シグナル によって生成されたスコアと失敗分析を使用して弱点を特定し、モデル改善、データアノテーション、または強化学習の検討に活用できます。
利用可能なシグナル
品質シグナル
エラーシグナル
シグナルの仕組み
- トレースの選択: Quality シグナルは、正常終了したルートレベルのトレースを評価します。Error シグナルは、失敗したトレースを評価します。Weave は子スパンや中間の Call をスコアリングしません。
- プロンプトの構築: Weave は、トレースのメタデータ、inputs、outputs、例外の詳細 (存在する場合) 、およびオペレーションのソースコードを含むプロンプトを構築します。Weave は、シグナルの分類器プロンプトに、検出対象の特定の問題に関する指示を追加します。
- LLM によるスコアリング: 各シグナルについて、Serverless Inference モデルが二値分類 (その問題がトレースに存在するかどうか) を実行します。検出された問題は、カンマ区切りの string tags として返されます (例:
"Low-quality, User-frustration, Forgetful") 。
Monitors ページからシグナルを追加する
- wandb.ai にアクセスし、Weave プロジェクトを開きます。
- Weave のプロジェクトのサイドバーで、Monitors を選択します。
- Monitors が有効になっていない project にシグナルを追加するには、カードをクリックしてチェックボックスをオンにし、Setup monitors をクリックします。
- 既存の Monitor にシグナルを追加するには、Monitors ページの右上にある Browse signals を選択します。すると Add signals ドロワーが開き、利用可能なシグナルがカテゴリ (Quality 分類器 や Error 分類器 など) ごとにグループ化され、各シグナルにチェックボックスが表示されます。個別のシグナルを選択することも、グループに対して Enable all を使用することも、Create custom signal を選択することもできます。その後、ドロワーの下部で Add signals を選択します。
アクティブなシグナルを管理する
- Monitors ページで、Manage signals () ボタンを選択します。カテゴリごとに整理された、現在アクティブなすべてのシグナルの一覧を表示するドロワーが開きます。
- シグナルにカーソルを合わせ、Remove signal () ボタンを選択して、そのシグナルを無効にします。
組み込みシグナルを使用する
Traces ページでタグ付きの Call トレースを確認する
@weave.op decorator を使って Ops としてトレースする場合、Weave はシグナル の結果を Call object の feedback として保存します。これらの結果は Traces ページからクエリできます。
Traces ページでは、Signals 列を使って、特定の動作を示すトレースを確認できます。Signals 列には、条件を満たした タグ が表示されます。これらの タグ にカーソルを合わせると、スコアの信頼度と推論を確認できます。
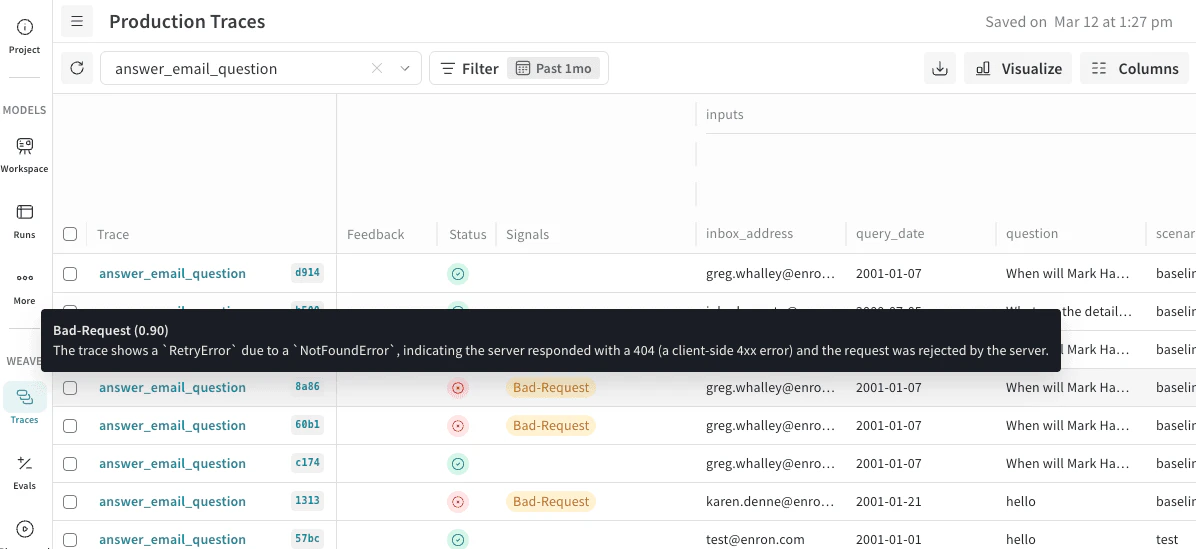
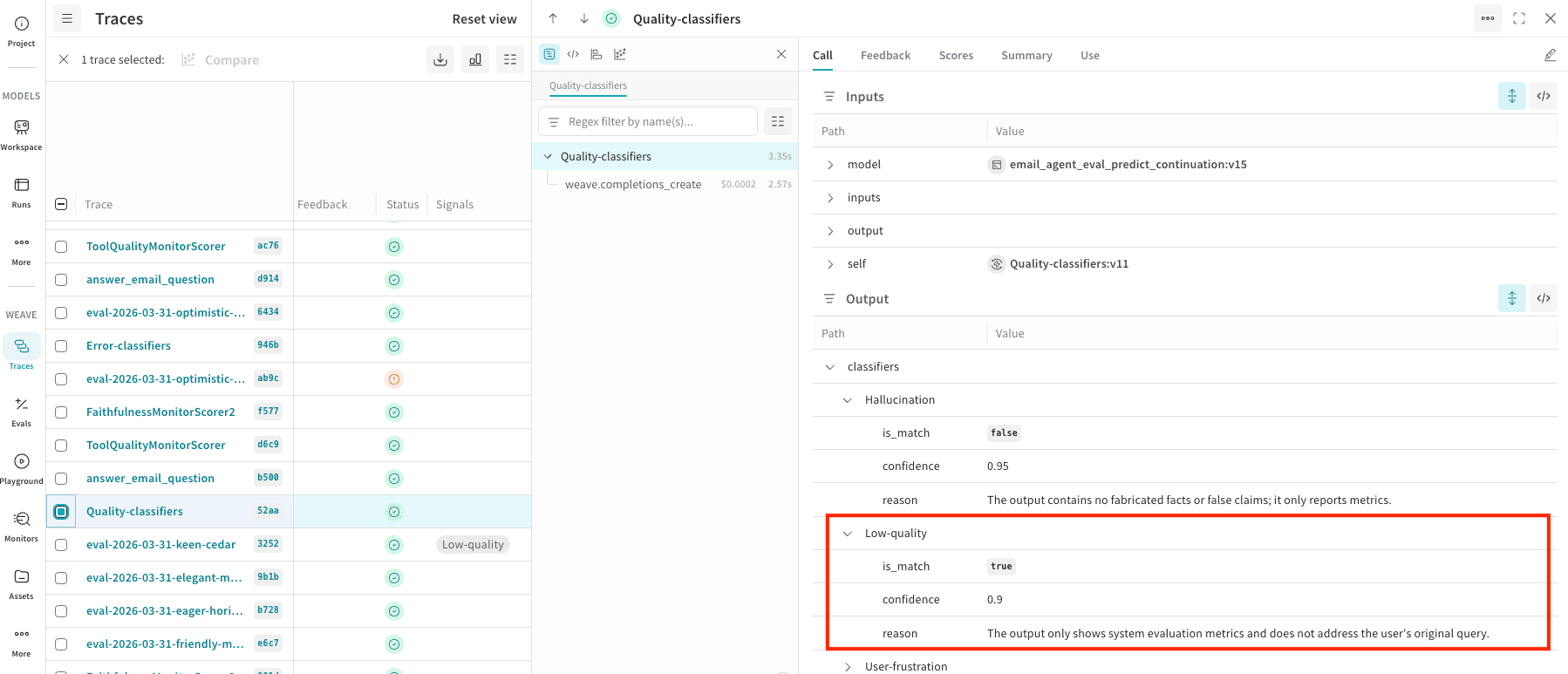
classifier_meta を確認してください。たとえば、次のスクリーンショットでは、Quality-classifiers シグナル が Low-quality に一致し、確信度 (0.9) とこの評価の理由が表示されています。
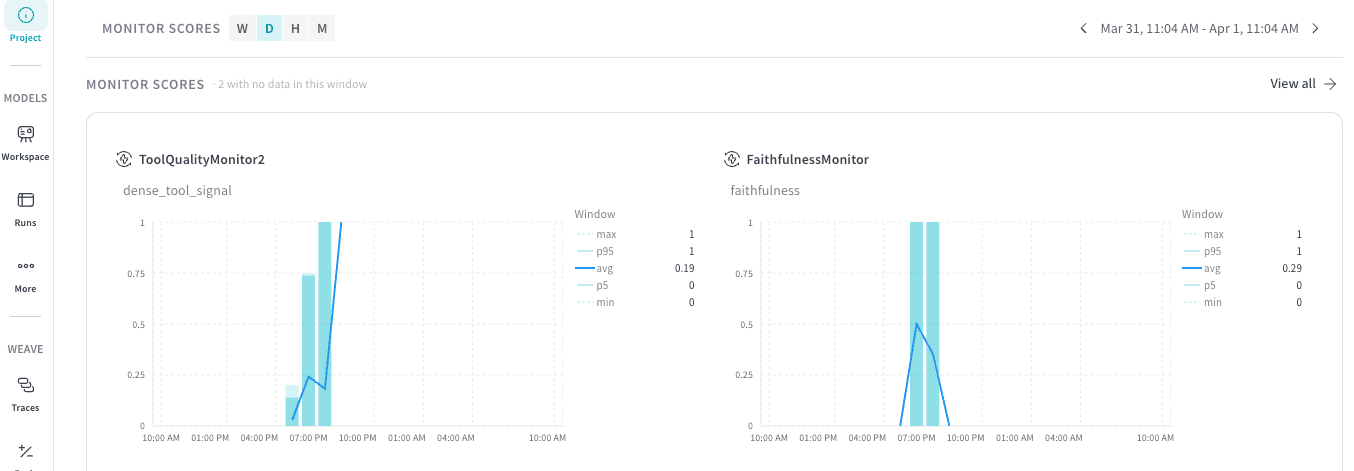
project ダッシュボードでシグナルを確認する
- プロジェクトのサイドバーで Project を選択します。
- Project ダッシュボードの上部で、Weave タブを選択します。
- Weave ダッシュボードのパネルで、Monitor Scores を確認します。
シグナルにアラートを設定する
組み込みシグナルではカバーできない特定の監視を行うには、カスタムモニターを設定するを参照してください。