はじめに
- https://wandb.ai にアクセスし、project を選択します。
- サイドバーメニューで Agents を選択すると、project に保存されているすべてのエージェントとの会話を表示できます。
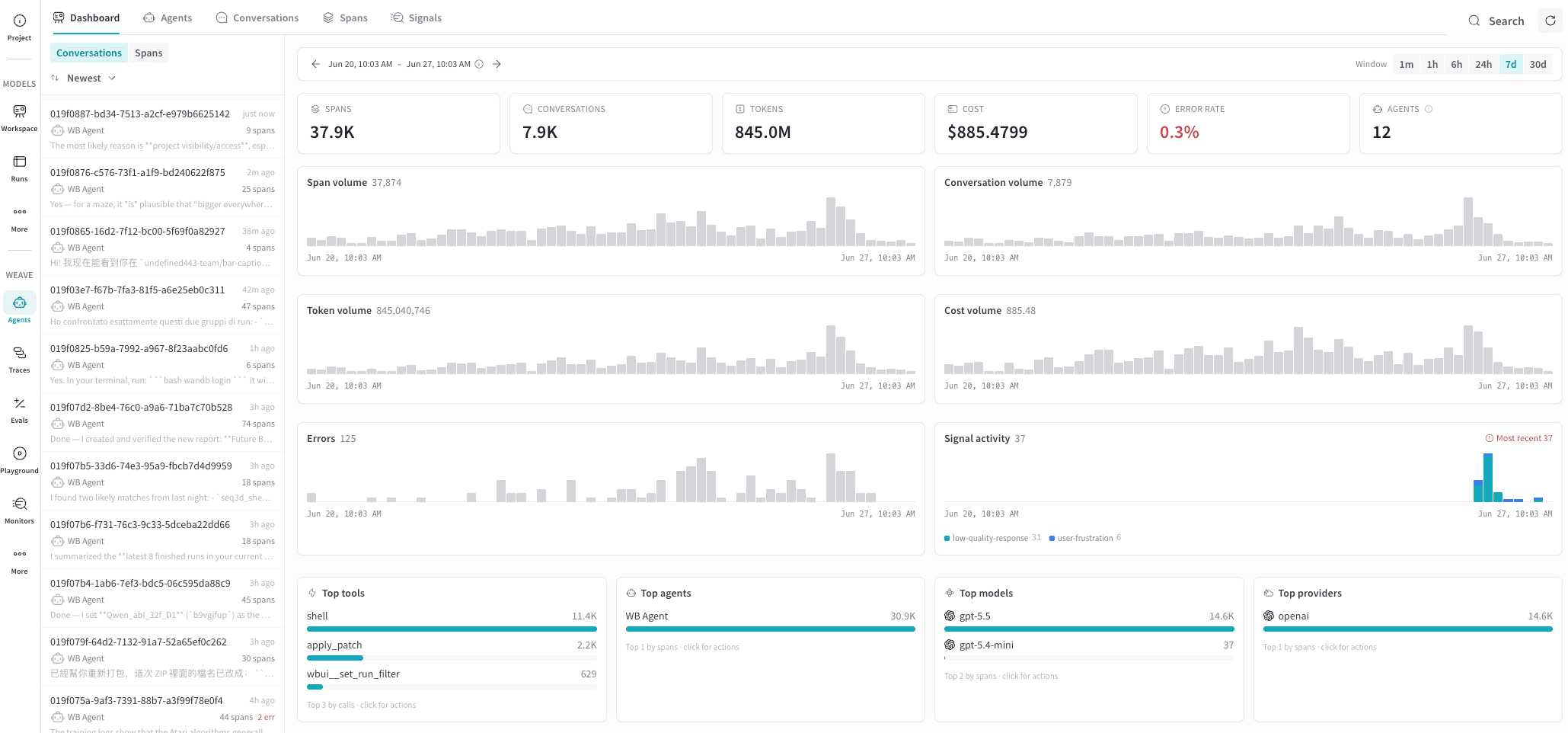
Dashboard タブ
Agents tab
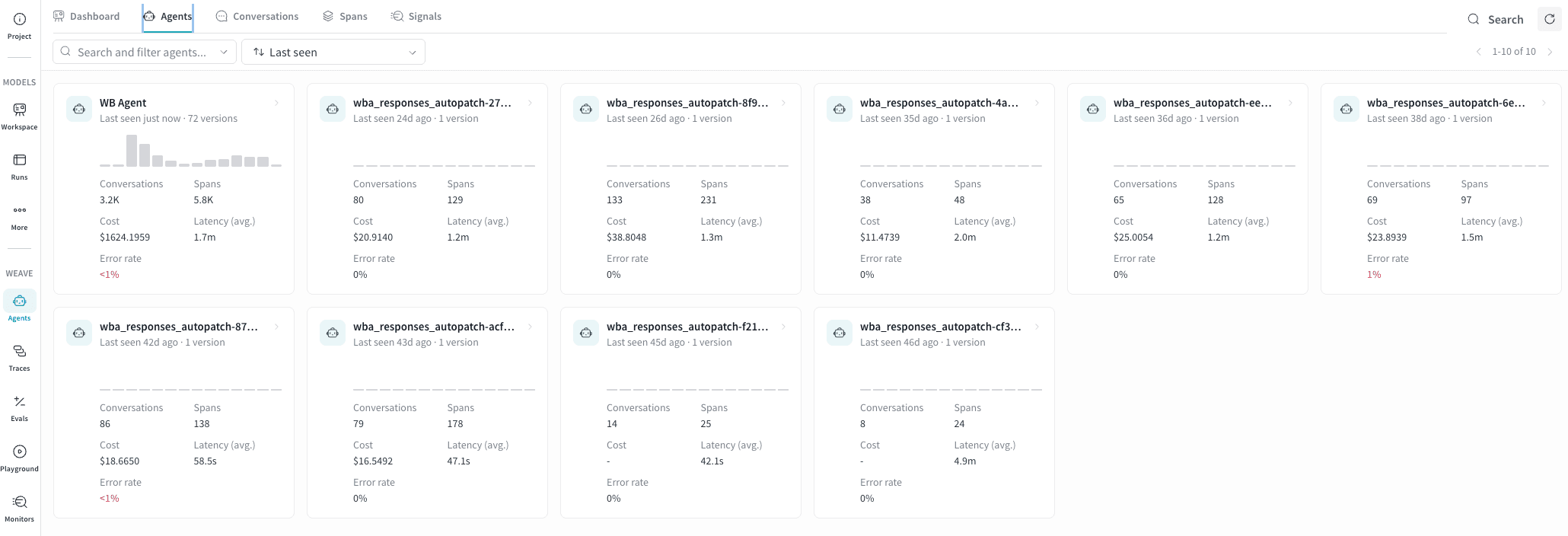
- 複数のエージェントの監視。 カードのグリッドを使うと、個々の会話を開かなくても、すべてのエージェントのレイテンシとエラー率を一度に比較できます。1 つのカードでレイテンシの急上昇や、新たに赤く表示されたエラー率が見られる場合は、調査すべきリグレッションの兆候です。
- 動きのないエージェントの特定。 Last seen で並べ替えると、最近アクティビティを記録していないエージェントを見つけやすくなります。これは、deployment が稼働中であることを確認したり、予期せずトレースのログを停止した可能性があるエージェントを特定したりするのに役立ちます。
- バージョンの比較。 各カードのバージョン数は、そのエージェントの異なるバージョンがいくつ deployment されたかを示します。エラー率の上昇に加えてバージョン数も多い場合は、最近の deployment で導入されたリグレッションを示している可能性があります。
- エージェントの詳細確認。 任意のカードをクリックすると、そのエージェントの詳細パネルが開き、そこから会話または スパン にアクセスできます。
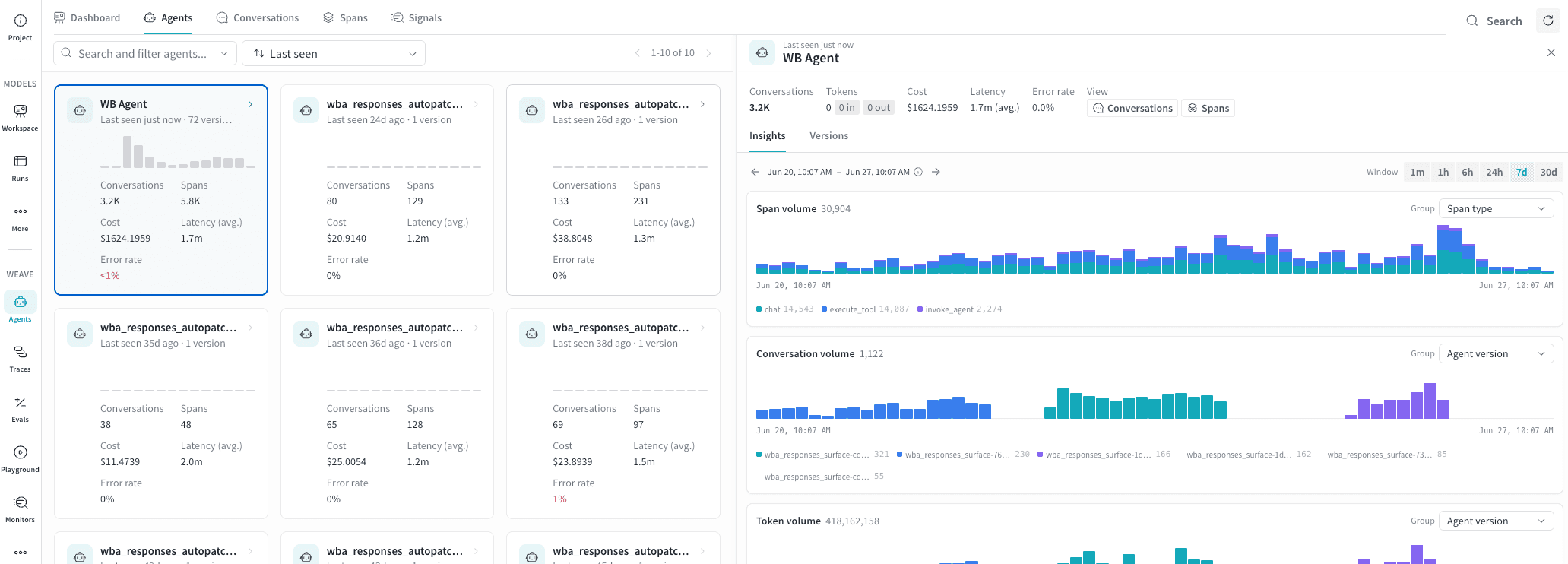
エージェントカード
エージェントを検索して並べ替える
- Last seen: 直近でアクティブだったエージェントから順に表示されます。
- Most invocations: 会話数が多い順に表示されます。
- Most input tokens: 入力 tokens の消費量が多い順に表示されます。
- Most errors: エラー数が多い順に表示されます。
Conversations タブ
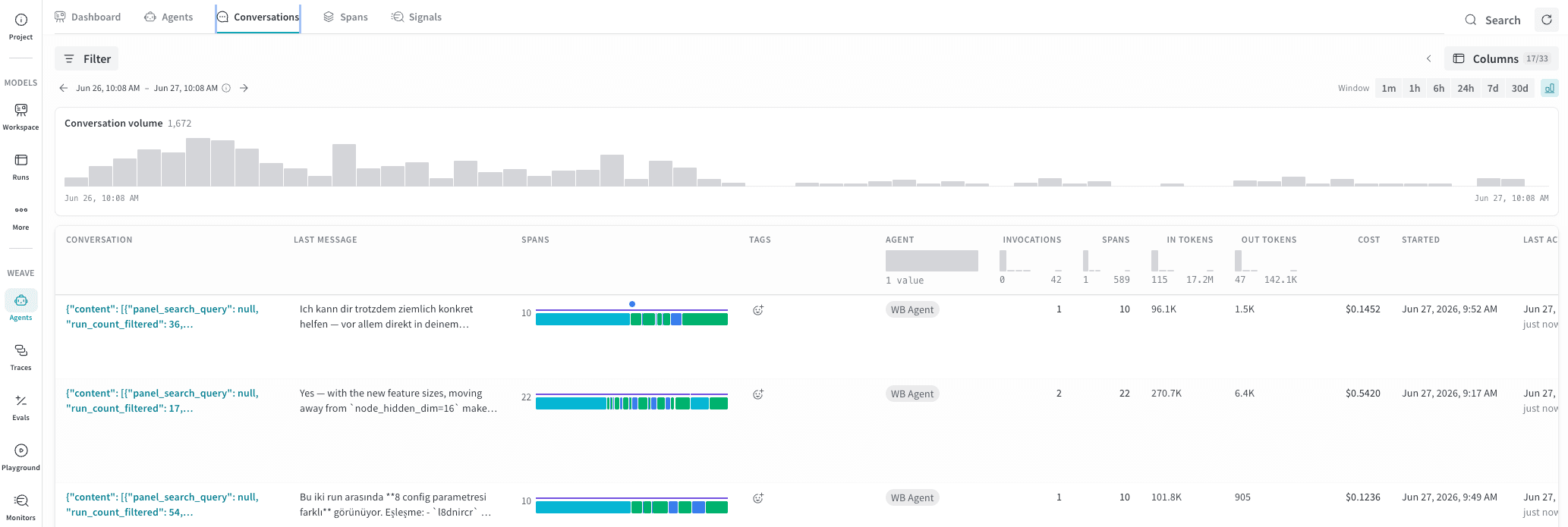
Conversations テーブル
Spans 列には、会話内のイベントのシーケンスをプレビューできる色分けされたストリップも表示され、Events timeline と同じイベントの色が使用されます。これにより、会話を開かなくても、その会話がツールの使用中心か、LLM 中心か、あるいは sub-agent への委譲を含むかをひと目で把握できます。
追加の列を表示または非表示にするには、ツールバーの Columns をクリックします。
フィルターと時間ウィンドウ
Agent の会話の詳細
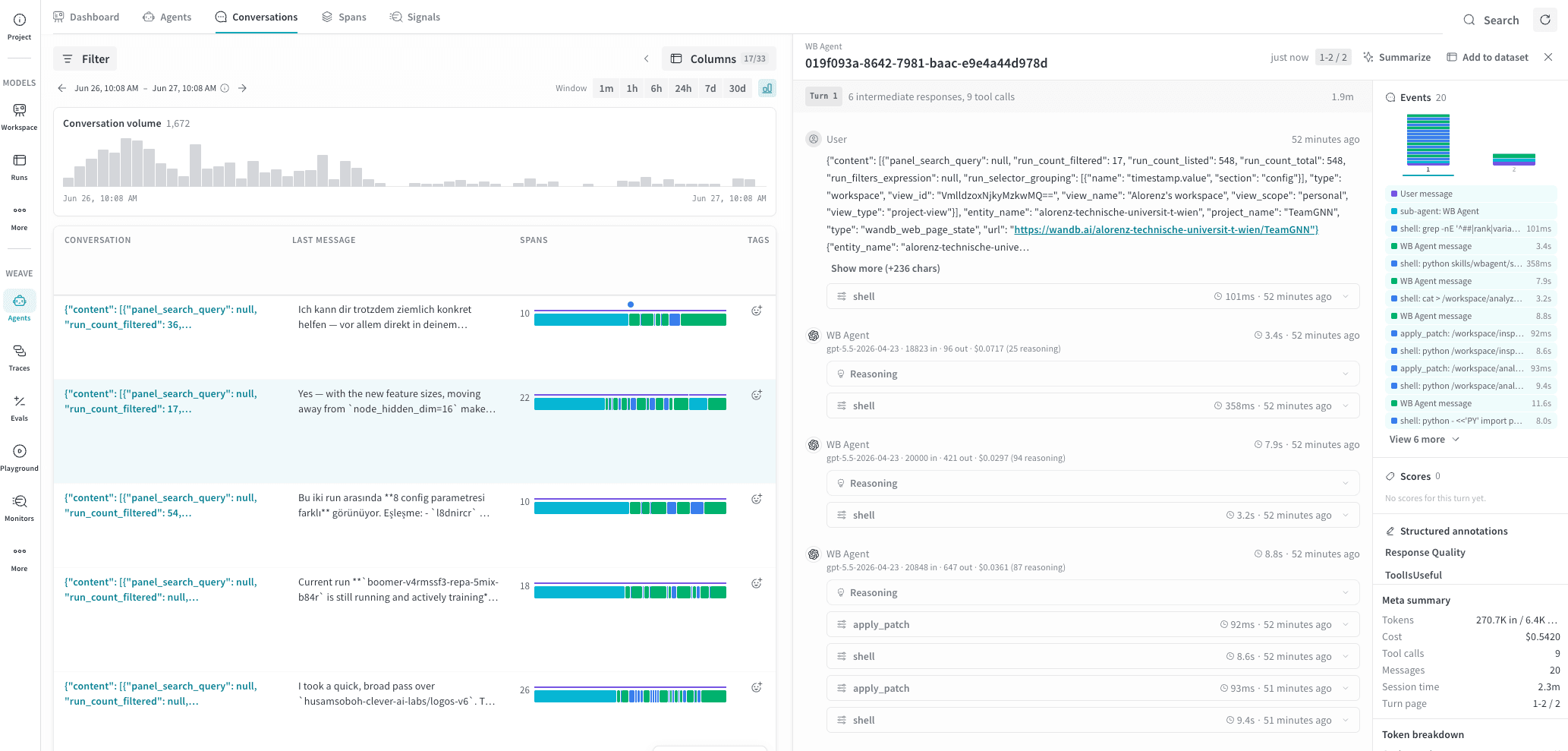
ターン
メッセージ
- エージェント名と使用されたモデル (例:
gpt-5.5-2026-04-23) 。 - タイムスタンプと所要時間。
- 入力および出力の token 数とコスト (例:
18823 in · 96 out · $0.0717) 。 - モデルで拡張思考が使用された場合は、展開可能な 推論 セクション。
- 応答テキスト。長い応答は自動的に折りたたまれます。
エラー状態
イベント
Events タイムラインを使うと、ターンがどのように構成されていたかを
すばやく把握できます。たとえば、メッセージ スレッド全体を読む前に、
LLM 中心だったのか、ツール中心だったのか、あるいは
サブエージェントへの委任が含まれていたのかを確認できます。
スコア
Meta summary
Token の内訳
Participants
エージェントのメッセージをデータセットに追加する
Datasetに追加するには、次の手順を実行します。
- 会話詳細パネルのヘッダーで、Add to dataset をクリックして Add example to dataset ドロワーを開きます。
- Choose a dataset で、ドロップダウンを使用して、トレースを追加するデータセットを選択します。
- Select context で、データセットに追加するメッセージを選択します。Next をクリックします。
- 選択内容を確認し、Add to dataset をクリックします。
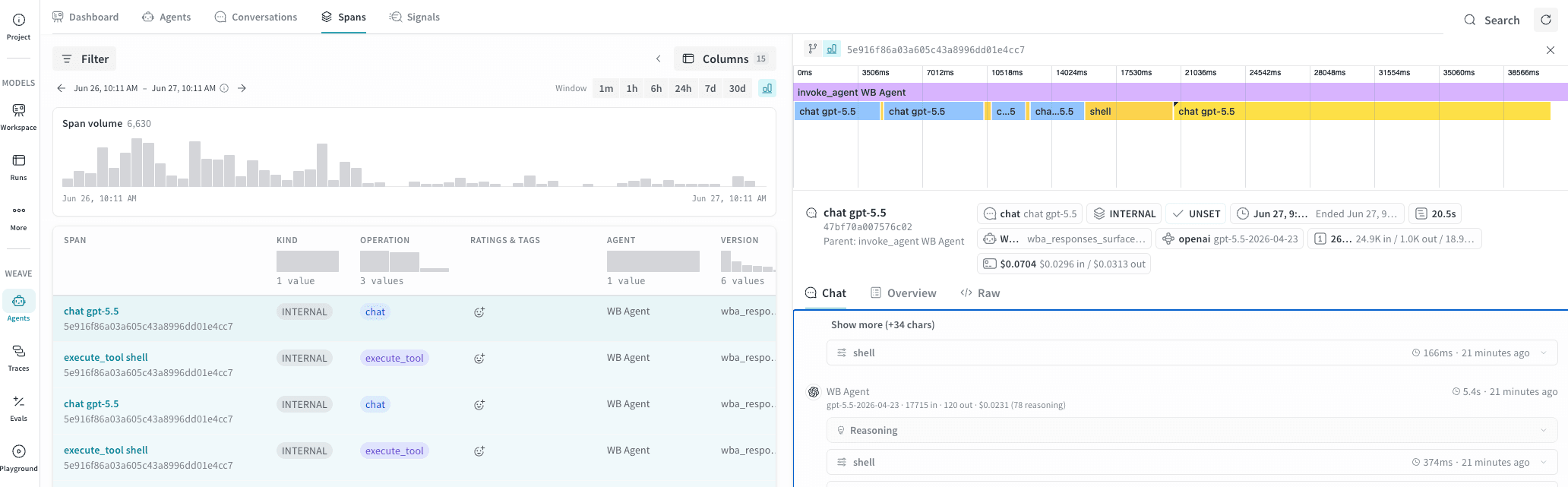
Spans タブ

Spans 表
キャッシュ token の内訳、推論 token、LLM パラメーター、W&B Run メタデータの追加列は、Columns ボタンから利用できます。
Spans タブは、Conversations タブでは得られない操作レベルの精度が必要な場合に特に役立ちます。
- 高コストな Call の特定。 In または Out token で並べ替えることで、会話レベルの合計ではなく、どの個別の LLM calls がコスト増の要因になっているかを特定できます。
- 特定の操作タイプのデバッグ。 Operation でフィルターすると、すべての
execute_toolspan を絞り込んでエラー率を確認したり、特定のモデルのすべてのchatspan を確認したりできます。 - 切り詰めの調査。 Finish を
max_tokensでフィルターすると、モデルが通常どおり完了する代わりに token 上限に達した span を検索できます。 - W&B Run との関連付け。 デフォルトで非表示の列には W&B Run ID と run ステップが含まれており、特定の span を W&B 内のトレーニングまたは評価 run に関連付けることができます。
トレース グループ
エージェント呼び出しの詳細
- 最も時間のかかった処理をひと目で特定できます。 幅の広いバーは、全体のレイテンシの大部分を占めたスパンを示します。
- 並列実行を確認できます。 バーが重なっている場合、それらのスパンは順番ではなく同時に実行されたことを示します。
- 任意のスパンをその場で確認できます。 タイムライン内のバーをクリックすると、そのスパンの詳細が表示されます。これには、入力メッセージ、出力メッセージ、トークン数、その他のメタデータが含まれます。