작동 방식
- 데이터 로깅: 스크립트에서 설정 및 summary 데이터를 로깅합니다.
- 차트 사용자 지정: GraphQL 쿼리로 로깅된 데이터를 가져옵니다. 시각화 문법인 Vega를 사용해 쿼리 결과를 시각화합니다.
- 차트 로깅: 스크립트에서
wandb.plot_table()을 사용해 자체 프리셋을 호출합니다.
스크립트에서 차트 로깅하기
기본 제공 프리셋
- 선형 플롯
- 산점도
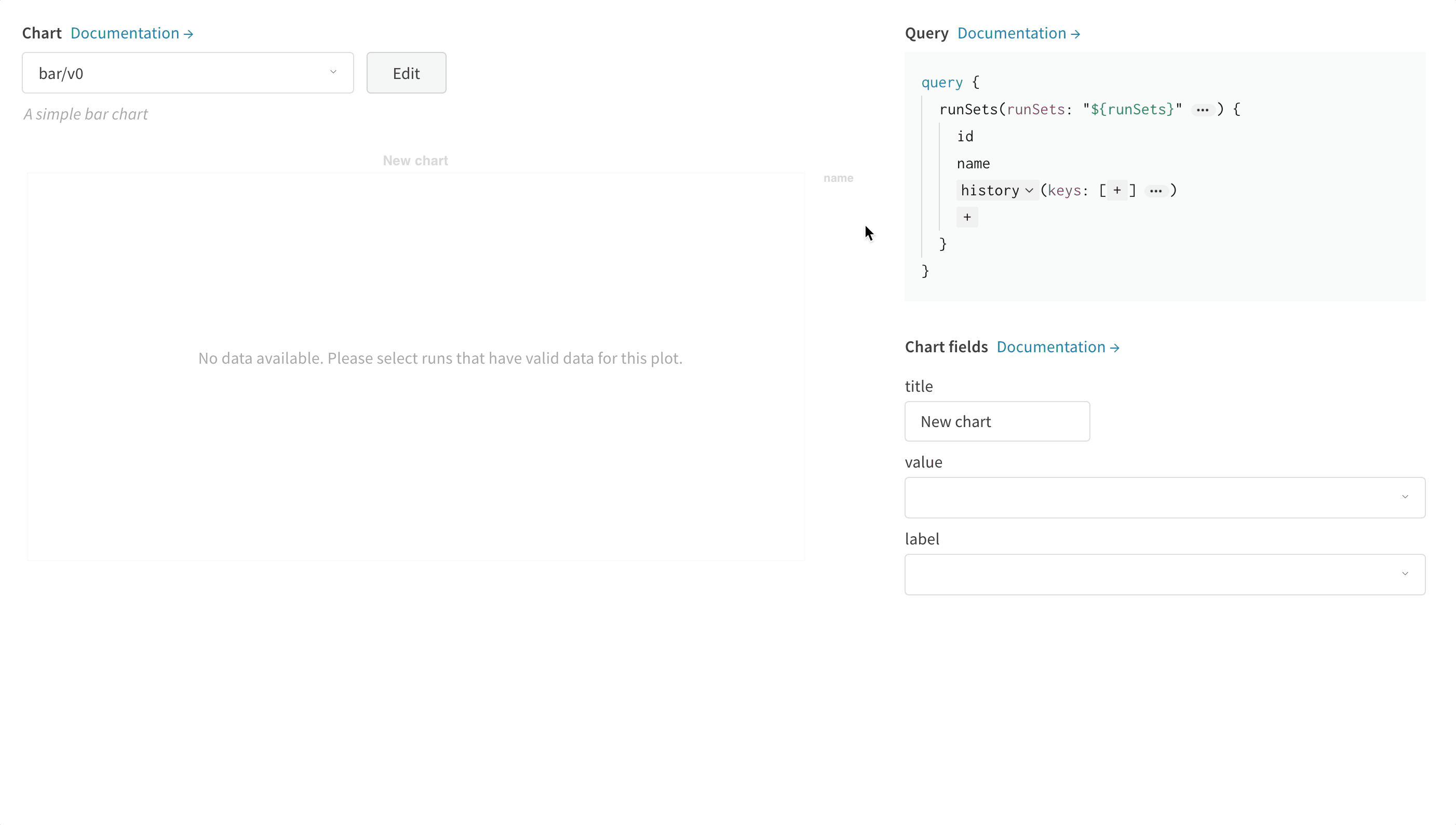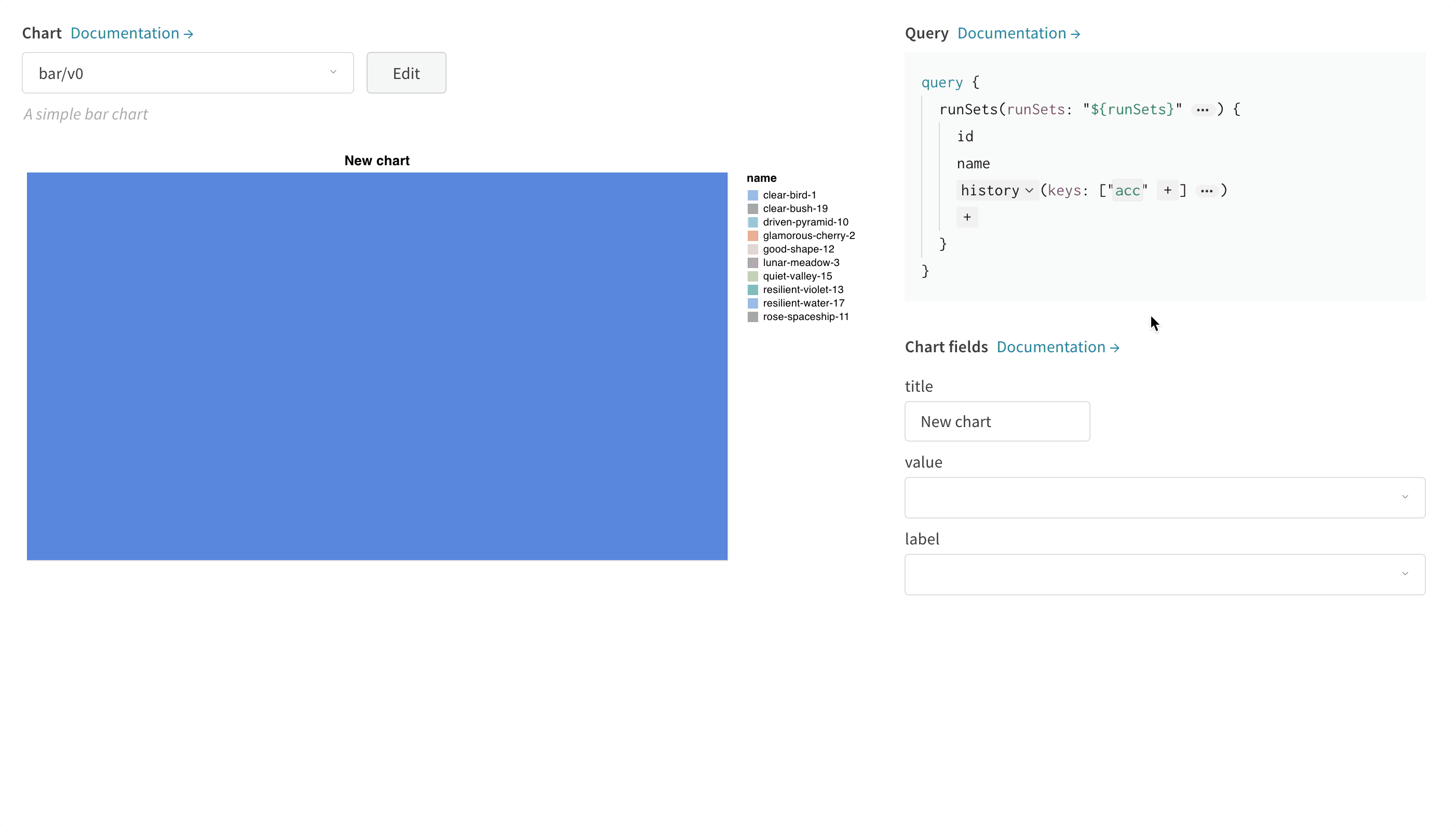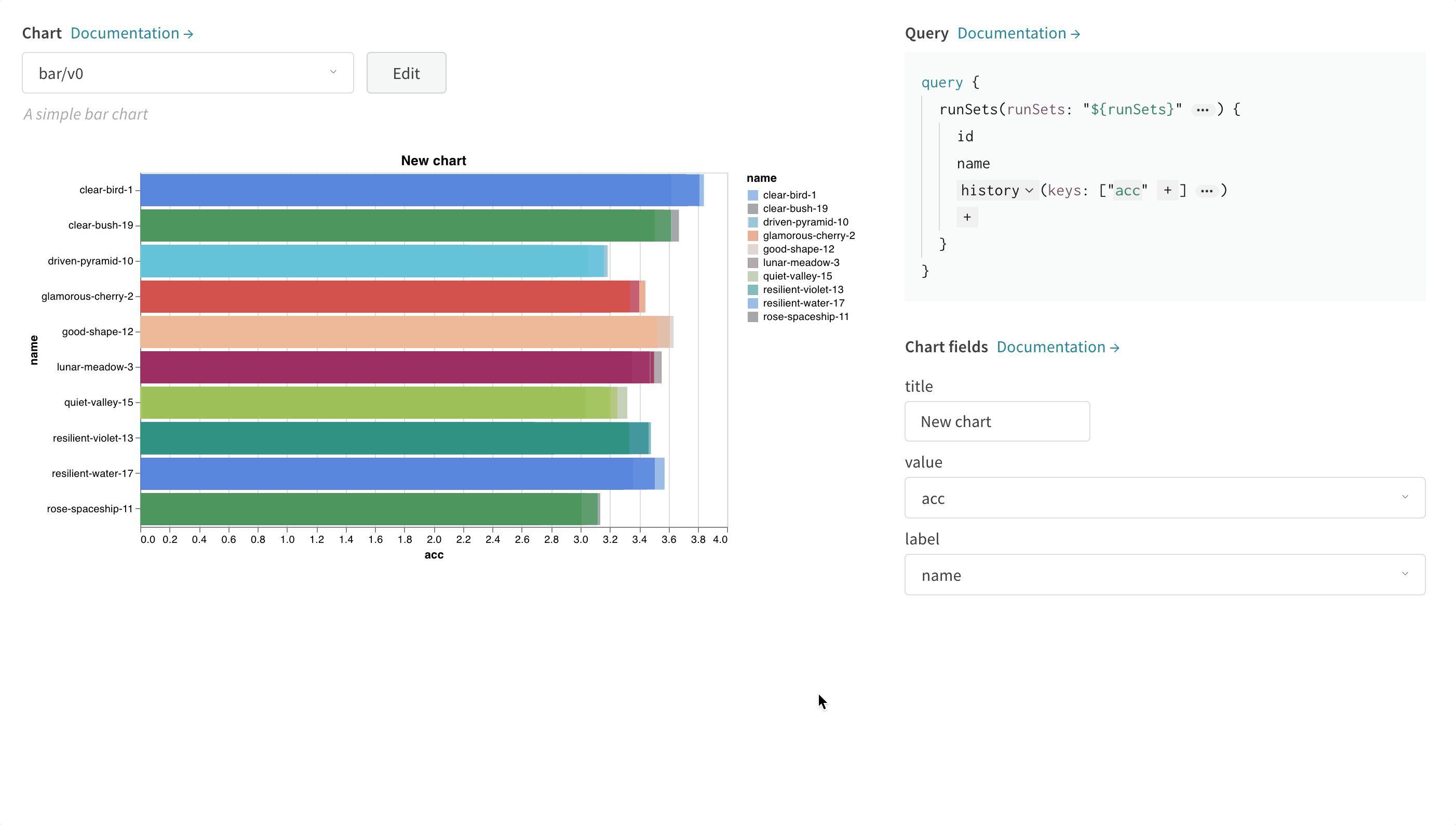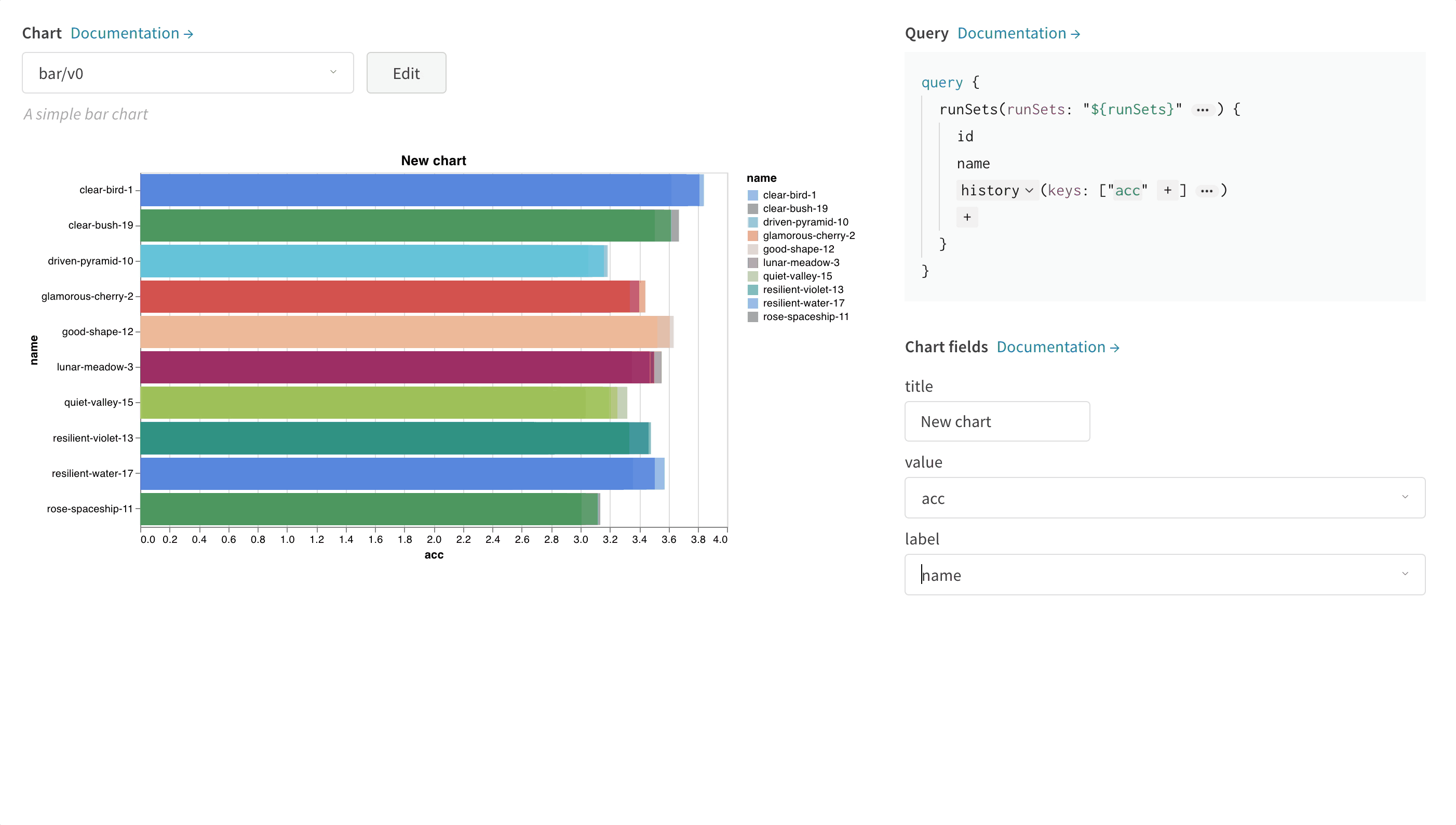
- 막대 차트
- 히스토그램
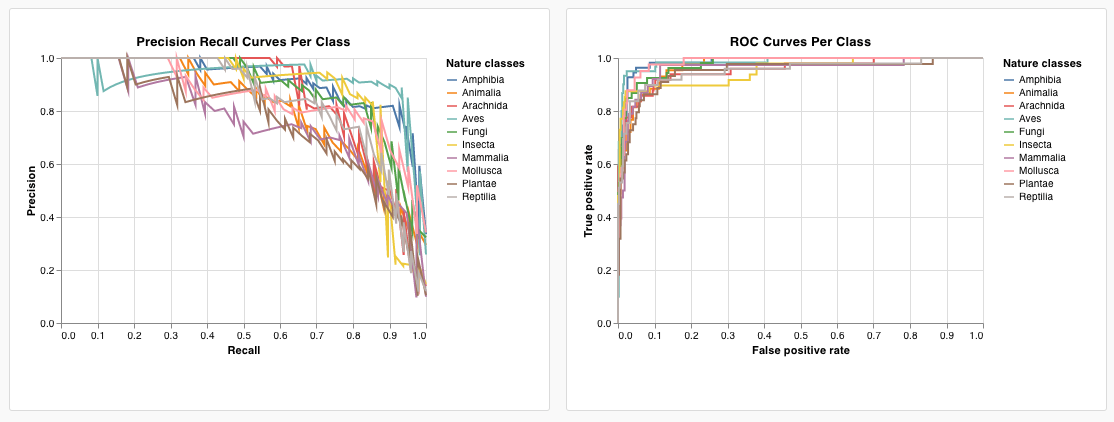
- PR 곡선
- ROC 곡선
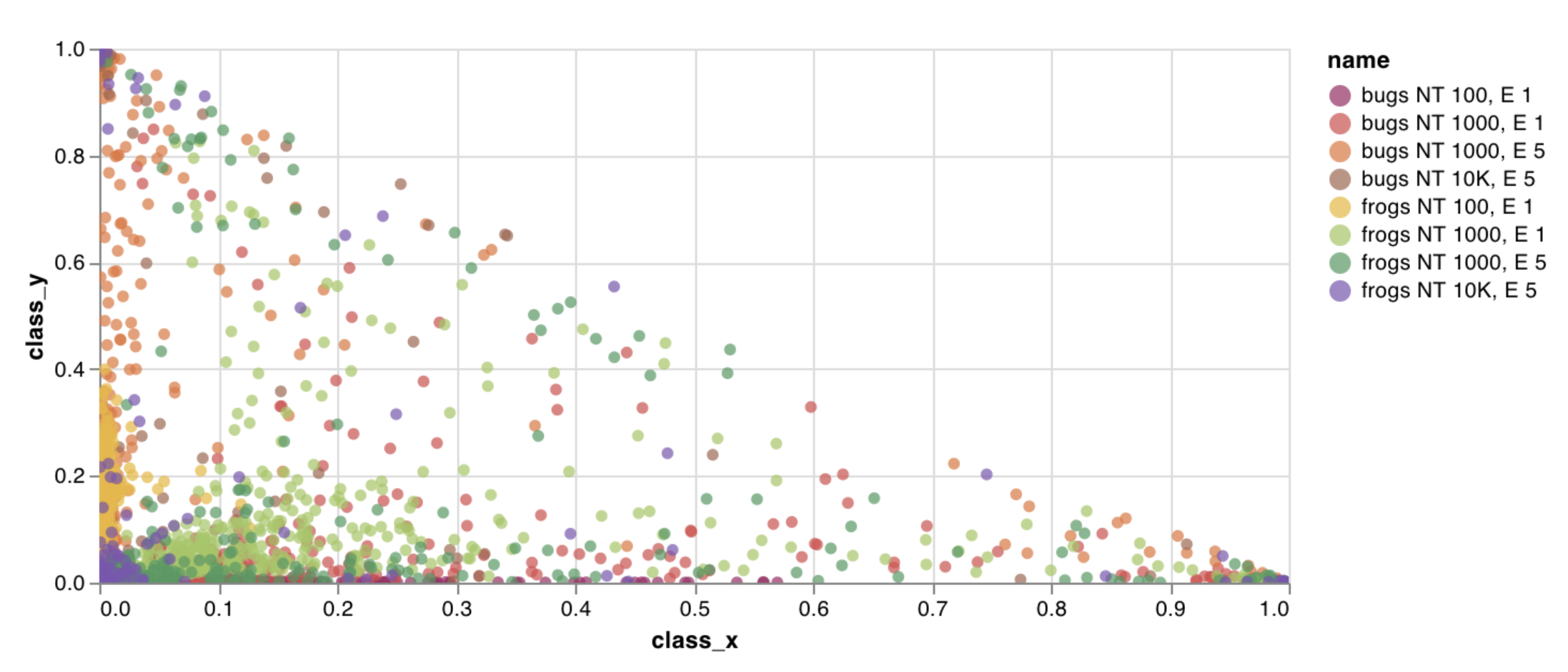
wandb.plot.line()맞춤형 선형 플롯을 기록합니다. 임의의 x축과 y축에서 (x, y) 점들을 순서대로 연결한 목록입니다.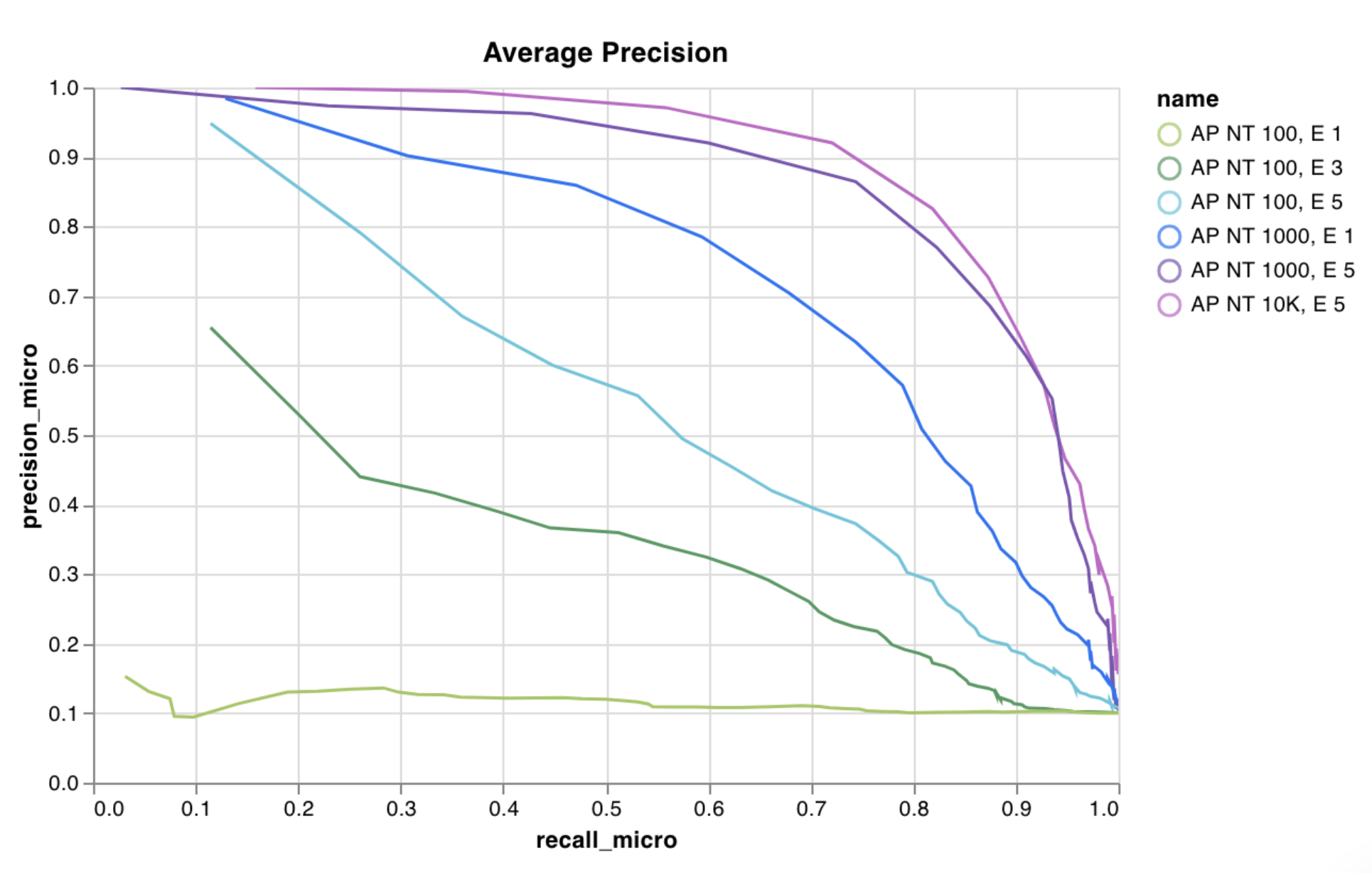
맞춤형 프리셋
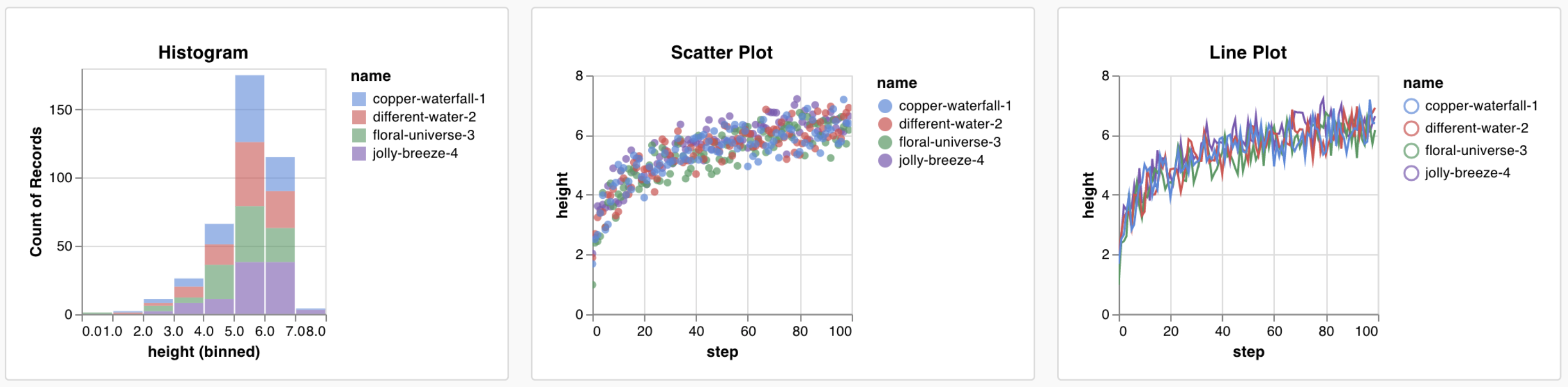
데이터 로깅
- Config: 실험의 초기 설정(독립 변수)입니다. 여기에는 트레이닝 시작 시
wandb.Run.config에 키로 로깅한 모든 이름 있는 필드가 포함됩니다. 예:wandb.Run.config.learning_rate = 0.0001 - Summary: 트레이닝 중 로깅된 단일 값(결과 또는 종속 변수)입니다. 예를 들어
wandb.Run.log({"val_acc" : 0.8})와 같습니다. 트레이닝 중wandb.Run.log()를 통해 이 키에 여러 번 기록하면, summary는 해당 키의 마지막 값으로 설정됩니다. - History: 로깅된 스칼라의 전체 시계열은
history필드를 통해 쿼리할 수 있습니다. - summaryTable: 여러 값의 목록을 로깅해야 한다면
wandb.Table()을 사용해 해당 데이터를 저장한 다음, 맞춤형 패널에서 쿼리하세요. - historyTable: 이력 데이터를 확인해야 한다면 맞춤형 차트 패널에서
historyTable을 쿼리하세요.wandb.Table()을 호출하거나 맞춤형 차트를 로깅할 때마다 해당 step의 이력에 새 테이블이 생성됩니다.
맞춤형 테이블 로깅
wandb.Table()을 사용해 데이터를 2차원 배열로 로깅합니다. 일반적으로 이 테이블의 각 행은 하나의 데이터 포인트를 나타내며, 각 열은 시각화하려는 각 데이터 포인트의 관련 필드 또는 차원을 나타냅니다. 맞춤형 패널을 설정하면 전체 테이블은 wandb.Run.log()에 전달한 키 이름(다음 예시의 custom_data_table)으로 접근할 수 있습니다. 개별 필드는 열 이름(x, y, z)으로 접근할 수 있습니다. 실험 전반에 걸쳐 여러 time step에서 테이블을 로깅할 수 있습니다. 각 테이블의 최대 크기는 10,000행입니다. Google Colab 노트북 예시를 사용해 보세요.
차트 사용자 지정
GraphQL 쿼리 작성하기
config, summary, history, summaryTable, historyTable 중에서 선택할 수 있습니다.
쿼리의 각 source는 서로 다른 로깅 데이터에 매핑됩니다.
- Config는 run configuration 값(하이퍼파라미터 및 기타 설정)을 가져옵니다.
- Summary는 summary 값을 가져옵니다. 기본적으로
wandb.Run.log()로 로깅한 키의 summary에는 해당 키에 마지막으로 기록된 값이 저장됩니다. 다른 집계를 사용하려면wandb.Run.define_metric(..., summary=...)를"min","max","mean","best", 또는"none"과 함께 호출하세요. 값을 직접 설정하려면wandb.Run.summary["key"] = value로 할당하세요. - History는 run 이력에서 스칼라 시계열을 가져옵니다(예: 각 step의
loss또는accuracy). 최종 숫자만이 아니라 전체 곡선이 필요할 때는 history를 사용하세요. - **
summaryTable**은 run summary에서wandb.Table을 로드합니다. 관심 있는 테이블이 run에 단일 스냅샷으로 저장되어 있을 때 사용하세요(예: 마지막에 한 번만 로깅하는 confusion matrix). - **
historyTable**은 run 이력에서wandb.Table을 로드합니다.wandb.Run.log()로 테이블을 로깅할 때마다 해당 테이블을 포함하는 step이 run 이력에 하나씩 추가됩니다. 테이블이 시간에 따라 바뀌거나 맞춤형 차트 편집기에서 step selector를 활성화하려는 경우 **historyTable**을 사용하세요(맞춤형 차트에 step slider를 표시하려면 어떻게 해야 하나요? 참고).
summaryTable**과 **historyTable**의 경우, **tableKey**는 wandb.Table 내부의 column 이름이 아니라 wandb.Run.log() 안에서 사용한 dictionary 키로 설정하세요.
다음 예시는 일반적인 사용 사례를 다룹니다.
- 각 step에서 로깅하는 테이블의 column을 plot하려는 경우(예: PR curve): **
historyTable**을 추가하고 **tableKey**를 로깅한 키로 설정한 다음(예:pr_curve), Chart fields에서 테이블 column을 매핑하세요. 맞춤형 차트 워크스루를 참고하세요. - summary에 있는 테이블의 column을 plot하려는 경우(예: composite histogram용 class scores): **
summaryTable**을 추가하고 **tableKey**를 해당 키로 설정하세요(튜토리얼에서는class_scores를 사용). Bonus: composite histograms를 참고하세요. - 트레이닝 step에 따른 스칼라 metric을 plot하려는 경우: history에서 해당 metric을 추가하세요. summary에서만 추가하면 차트에는 run별로 단일 값만 표시됩니다.
runSets_로 시작하며 선택한 쿼리 필드를 반영합니다. 직접 입력하지 말고 각 ${field:...} placeholder 옆의 드롭다운에서 선택하세요.
column이 전혀 나타나지 않으면 선택한 Runs에 해당 키가 있는지 확인하고, run 페이지를 열어 데이터가 어떻게 로깅되었는지 확인한 다음, **summaryTable**과 historyTable 중 어떤 것이 해당 로깅 패턴에 맞는지 점검하세요.
맞춤형 차트는 이 GraphQL 기반 panel query를 사용합니다. Query panels은 다른 표현식 언어를 사용하며 별도로 문서화되어 있습니다.
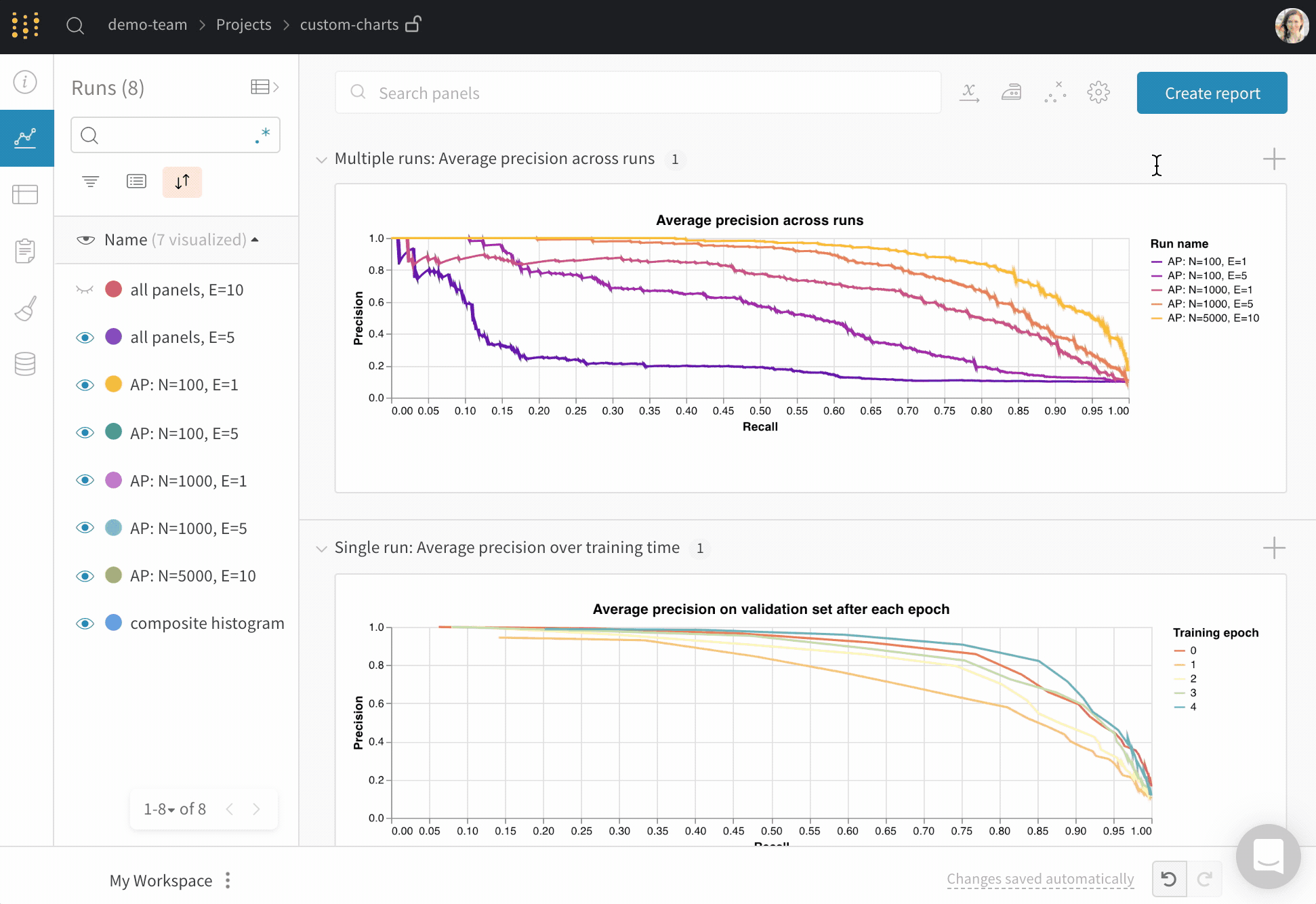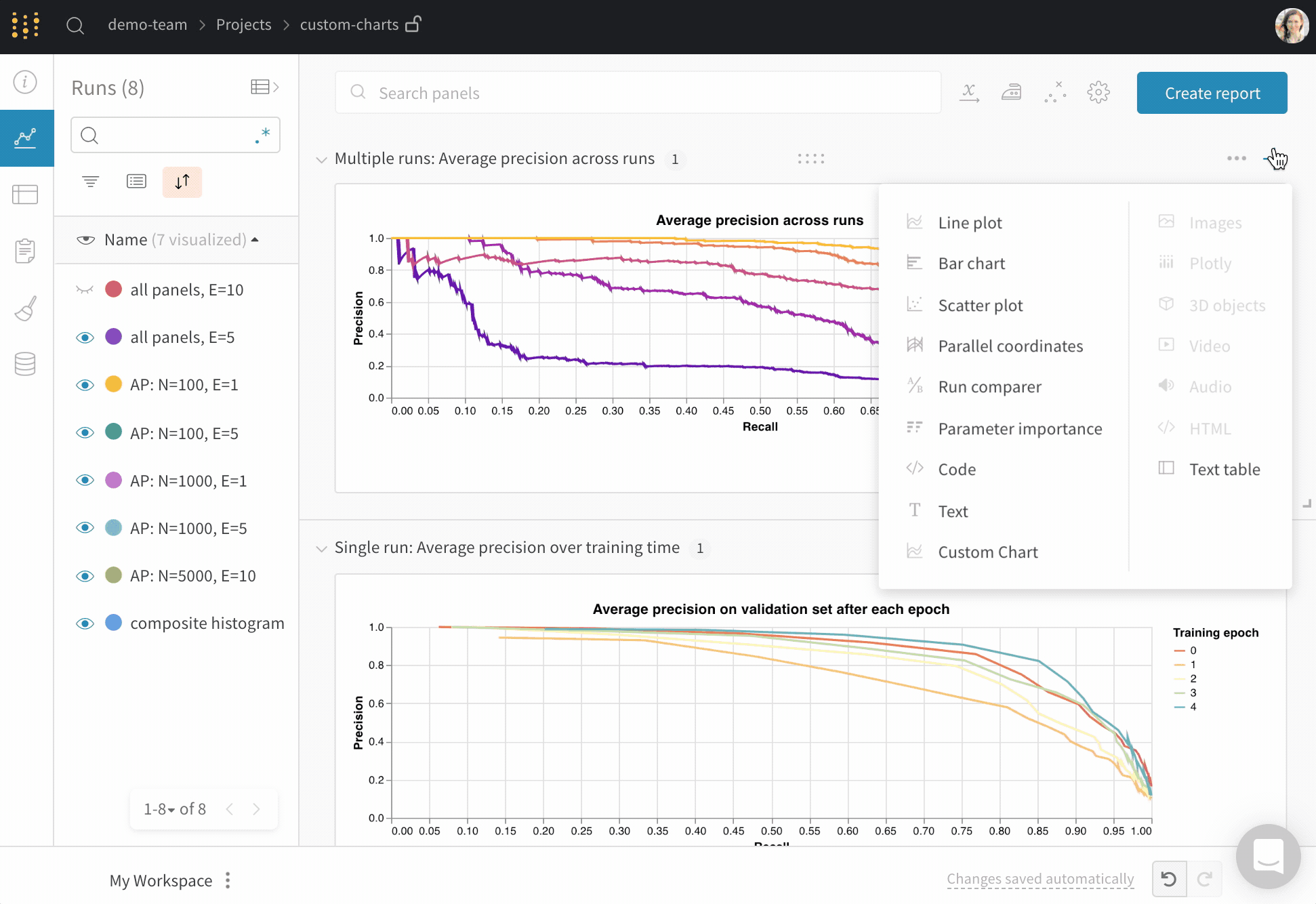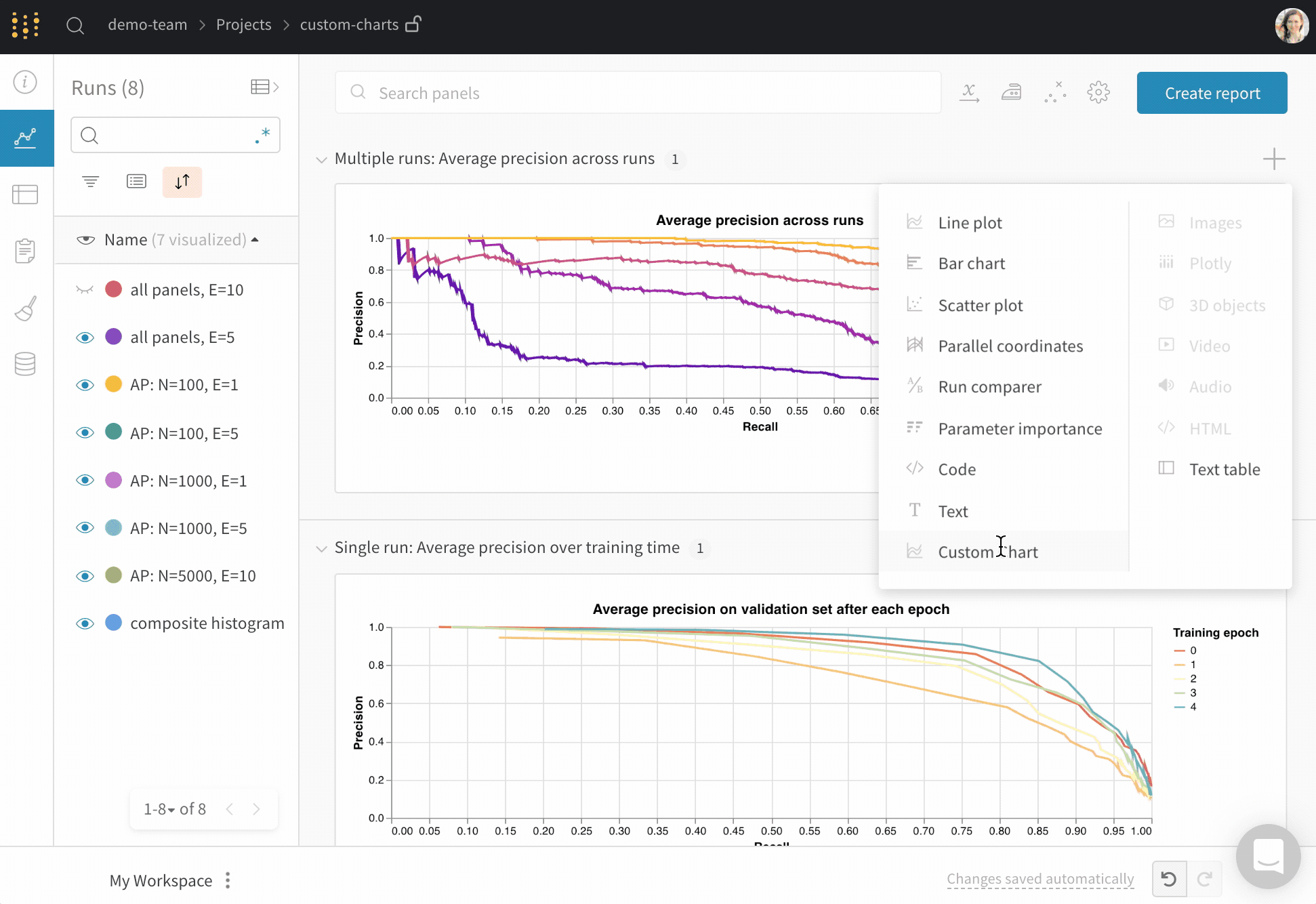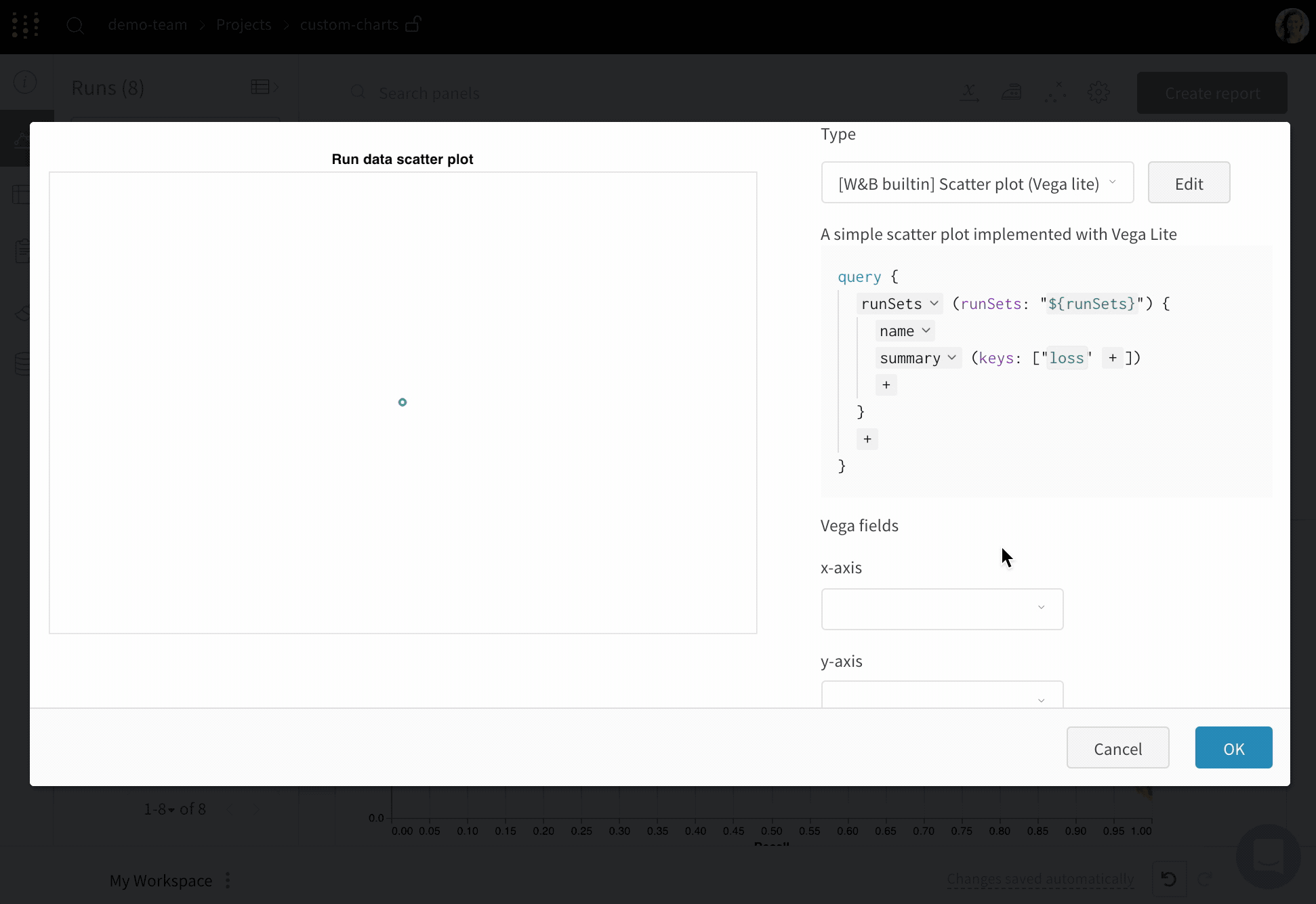
맞춤형 시각화
Vega 편집
"${field:<field-name>}" 형식의 템플릿 문자열을 추가하세요. 그러면 오른쪽의 Chart fields 영역에 드롭다운이 생성되고, 이를 사용해 Vega에 매핑할 쿼리 결과 열을 선택할 수 있습니다.
필드의 기본값을 설정하려면 다음 구문을 사용하세요: "${field:<field-name>:<placeholder text>}"
차트 프리셋 저장
Reports 및 가이드
- W&B 머신 러닝 시각화 IDE
- 맞춤형 차트를 사용해 NLP 어텐션 기반 모델 시각화하기
- 맞춤형 차트를 사용해 어텐션이 그라디언트 흐름에 미치는 영향 시각화하기
- 임의의 곡선 로깅하기
일반적인 사용 사례
- 오차 막대가 있는 막대 플롯을 맞춤 설정
- 맞춤형 x-y 좌표가 필요한 모델 검증 메트릭 표시(예: precision-recall curve)
- 서로 다른 두 모델 또는 실험의 데이터 분포를 히스토그램으로 겹쳐 표시
- 트레이닝 중 여러 시점의 스냅샷을 통해 메트릭 변화를 표시
- W&B에서 아직 사용할 수 없는 고유한 시각화를 만들어 다른 사람과 공유