임베딩은 사람, 이미지, 게시물, 단어와 같은 객체를 숫자 목록으로 표현한 것으로, 벡터 라고도 합니다. 머신 러닝과 데이터 과학에서는 다양한 애플리케이션에서 여러 방식으로 임베딩을 생성할 수 있습니다. 이 페이지는 사용자가 임베딩에 이미 익숙하며, W&B 내에서 이를 시각적으로 분석하려는 경우를 전제로 합니다.
이 가이드에서는 임베딩을 W&B에 로깅하고, PCA, UMAP, t-SNE와 같은 차원 축소 알고리즘을 사용해 Embedding Projector에서 2D 평면에 시각화하는 방법을 설명합니다. 이렇게 임베딩을 시각화하면 클러스터를 탐색하고, 데이터 포인트 간의 관계를 살펴보며, 임베딩이 기대한 구조를 잘 캡처하는지 검증하는 데 도움이 됩니다.
다음 리소스에서는 직접 사용해 보기 전에 Embedding Projector가 실제로 어떻게 작동하는지 확인할 수 있습니다:
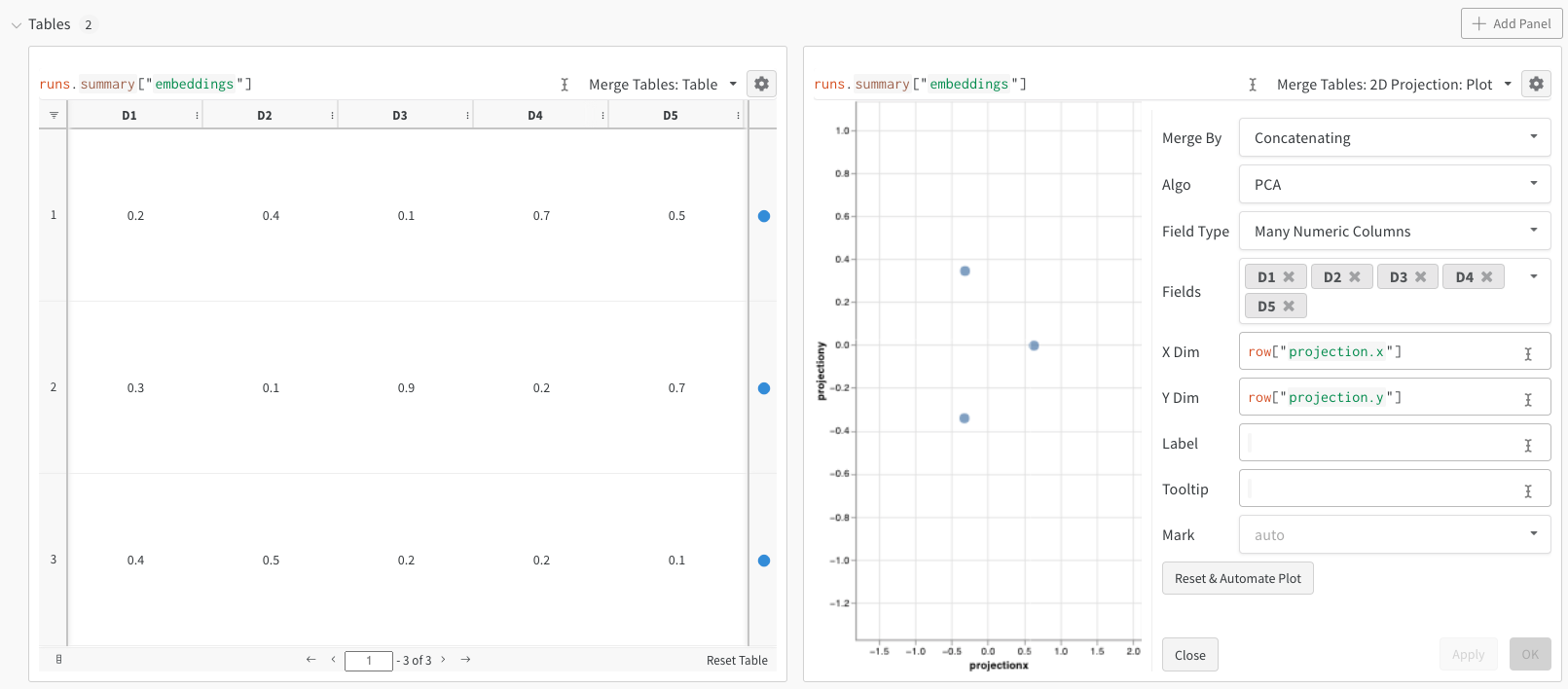
이 최소 예시는 임베딩을 로깅하고 projector에서 확인하는 데 필요한 가장 적은 코드만 보여줍니다. W&B에서는 wandb.Table 클래스를 사용해 임베딩을 로깅할 수 있습니다. 각각 5개 차원으로 이루어진 3개의 임베딩 예시를 살펴보세요:
앞의 코드를 실행하면 W&B 대시보드에 데이터가 포함된 새 Table이 생성됩니다. 오른쪽 상단의 패널 선택기에서 2D Projection을 선택하면 임베딩을 2차원으로 시각화할 수 있습니다. W&B는 자동으로 적절한 기본값을 선택하며, 톱니바퀴 아이콘을 클릭해 설정 메뉴에서 이를 재정의할 수 있습니다. 이 예제에서는 W&B가 사용 가능한 5개의 숫자 차원을 모두 사용합니다.
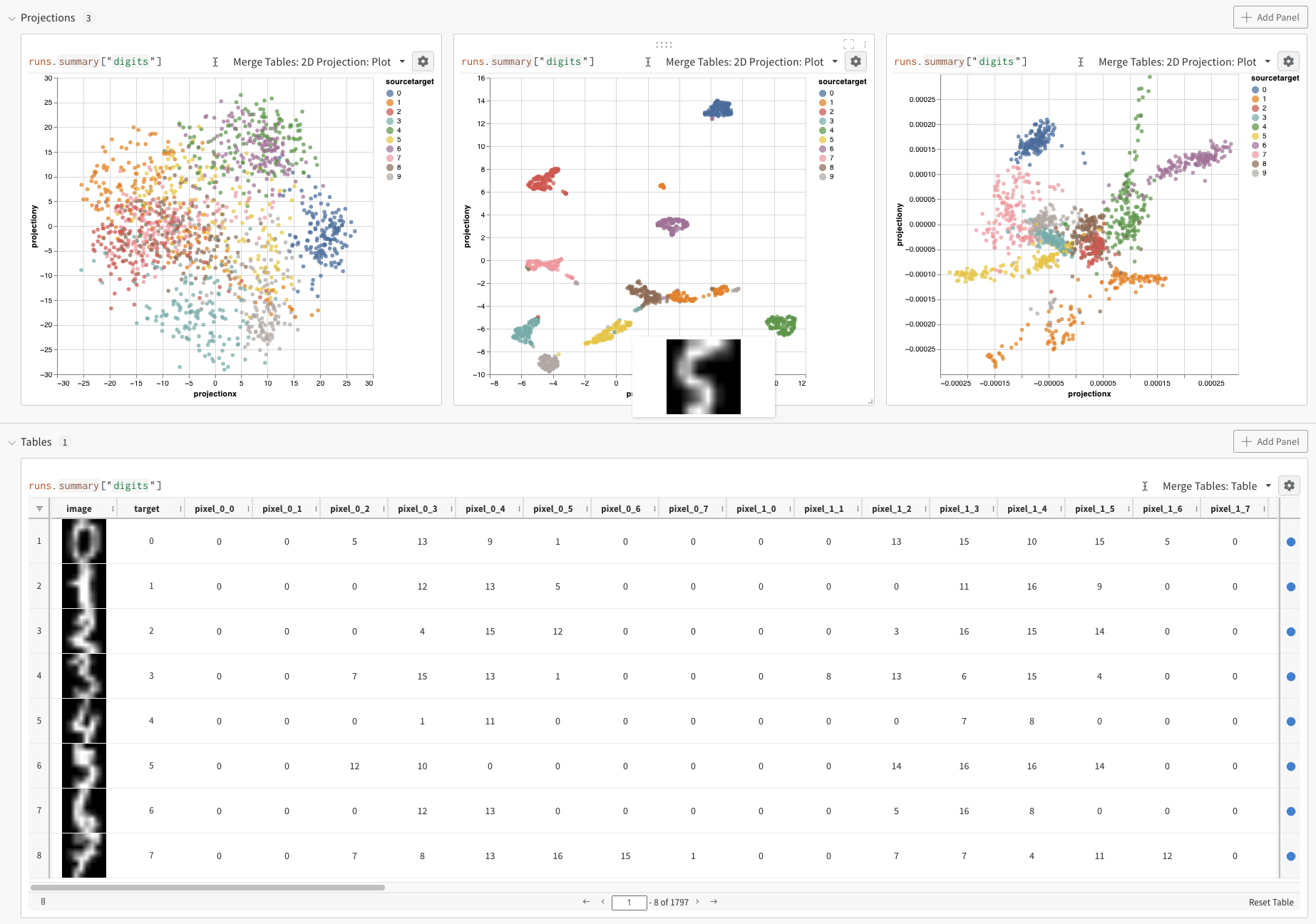
다음 예시는 더 높은 차원의 데이터와 더 다양한 오버레이를 사용하는, 보다 현실적인 워크플로를 보여줍니다. 앞선 예시에서는 임베딩 로깅의 기본 메커니즘을 보여주었지만, 일반적으로는 훨씬 더 많은 차원과 샘플을 다루게 됩니다. SciKit-Learn에서 제공하는 MNIST Digits 데이터셋(UCI ML hand-written digits dataset)을 살펴보세요. 이 데이터셋에는 1,797개의 레코드가 있으며, 각 레코드는 64차원입니다. 이 문제는 10개 클래스 분류 문제입니다. 또한 시각화를 위해 입력 데이터를 이미지로 변환할 수도 있습니다.
앞의 코드를 실행하면 UI에 다시 Table이 표시됩니다. 임베딩 정의, 색상, 알고리즘(PCA, UMAP, t-SNE), 알고리즘 파라미터, 오버레이를 구성하려면 2D Projection을 선택하세요. 이 경우 점 위에 마우스를 올리면 W&B가 이미지를 표시합니다. 이 설정들은 모두 적절한 기본값이므로 2D Projection을 한 번만 클릭해도 비슷한 결과를 볼 수 있습니다. 이 임베딩 튜토리얼 예시를 직접 살펴보세요.
다음 섹션에서는 데이터를 W&B에 로깅할 때 임베딩 데이터를 구조화할 수 있는 지원되는 방법을 설명합니다. 임베딩은 여러 형식으로 로깅할 수 있습니다.
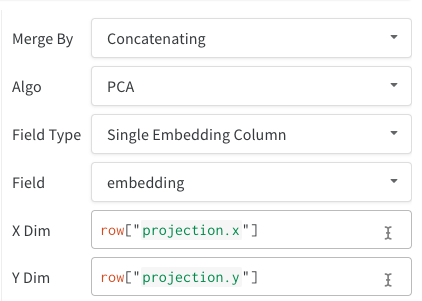
- 단일 임베딩 열: 데이터가 이미 행렬과 비슷한 형식인 경우가 많습니다. 이 경우 단일 임베딩 열을 만들 수 있으며, 셀 값의 데이터 유형은
list[int], list[float] 또는 np.ndarray일 수 있습니다.
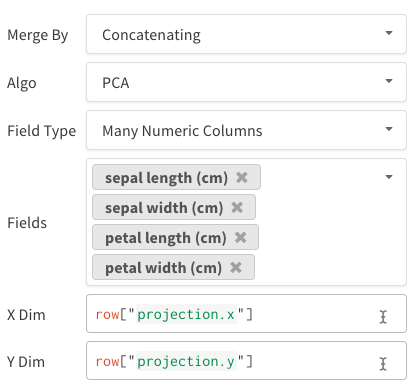
- 여러 숫자 열: 앞선 두 예시는 이 방식을 사용하며, 각 차원마다 열을 하나씩 만듭니다. W&B는 셀 값으로 Python
int 또는 float를 허용합니다.
모든 Table과 마찬가지로 Table을 구성하는 방법에도 여러 옵션이 있습니다.
- 데이터프레임에서 직접 생성:
wandb.Table(dataframe=df)를 사용합니다.
- 데이터 목록에서 직접 생성:
wandb.Table(data=[...], columns=[...])를 사용합니다.
- Table을 행별로 점진적으로 구축(코드에 루프가 있는 경우에 적합):
table.add_data(...)를 사용해 Table에 행을 추가하세요.
- Table에 임베딩 열 추가(예측 목록이 임베딩 형식인 경우에 적합):
table.add_col("col_name", ...).
- 계산 열 추가(Table 전체에 적용하려는 함수나 모델이 있는 경우에 적합):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)}).
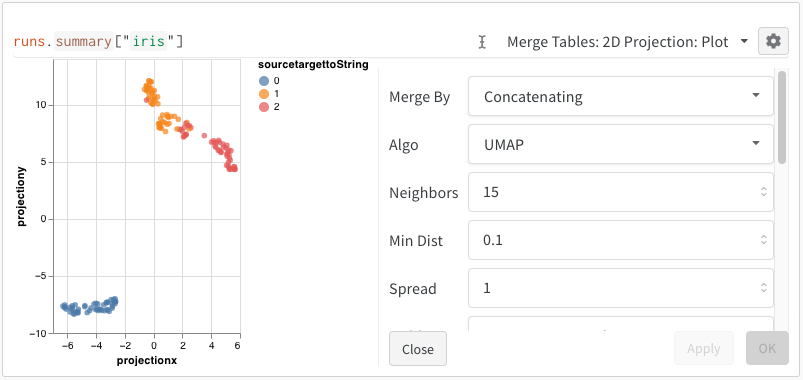
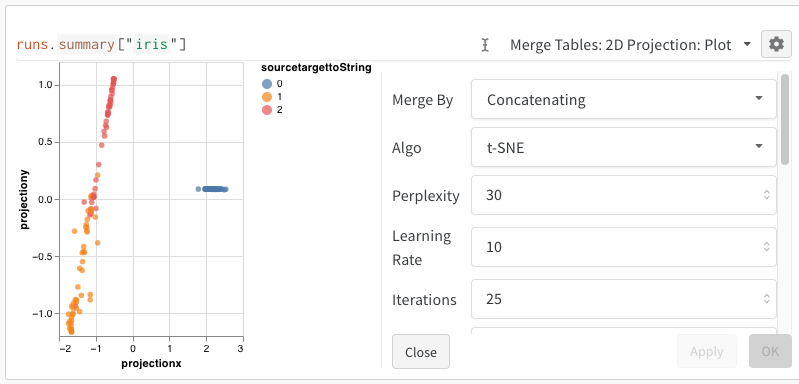
임베딩을 로깅한 후에는 임베딩이 투영되고 렌더링되는 방식을 조정할 수 있습니다. 2D Projection을 선택한 후 톱니바퀴 아이콘을 클릭하면 렌더링 설정을 편집할 수 있습니다. 원하는 열을 선택하는 것(이전 섹션 참조) 외에도 관심 있는 알고리즘과 원하는 매개변수를 선택할 수 있습니다. 아래 이미지는 UMAP과 t-SNE의 매개변수를 보여줍니다.
W&B는 세 알고리즘 모두에 대해 1,000개 행과 50개 차원의 무작위 부분집합으로 다운샘플링합니다.