이 노트북은 대화형 노트북입니다. 로컬에서 실행하거나 다음 링크를 사용할 수 있습니다:
왜 Weave를 사용해야 하나요
- LLM 파이프라인 추적: 코드 생성 과정의 입력, 출력, 중간 step을 기록합니다.
- LLM 출력 평가: 디버깅 도구와 시각화를 활용해 생성한 코드의 평가를 만들고 비교합니다.
환경 설정
Weave는 입력, 출력, 메타데이터를 포함한 OpenAI API 호출을 자동으로 추적합니다. OpenAI와 상호작용할 때 별도의 로깅 코드를 추가할 필요가 없습니다. Weave가 백그라운드에서 이를 처리합니다.
구조화된 출력과 Pydantic 모델
- 유형 안정성: 예상 출력에 맞춰 Pydantic 모델을 정의하면 생성된 코드, 프로그램 실행기, 단위 테스트에 엄격한 구조를 강제 적용할 수 있습니다.
- 더 쉬운 파싱: 구조화된 출력 모드를 사용하면 모델의 응답을 미리 정의한 Pydantic 모델로 직접 파싱할 수 있어 복잡한 후처리의 필요성이 줄어듭니다.
- 향상된 신뢰성: 기대하는 정확한 형식을 지정하면 언어 모델이 예기치 않거나 형식이 잘못된 출력을 생성할 가능성을 줄일 수 있습니다.
코드 포매터 구현
CodeFormatter 클래스를 구현하세요. 이 포매터는 생성된 코드, 프로그램 러너, 단위 테스트에 린팅 및 스타일 규칙을 적용합니다.
CodeFormatter 클래스는 생성된 코드를 정리하고 포맷하는 데 사용할 수 있는 여러 Weave 오퍼레이션을 제공합니다:
- 이스케이프된 줄바꿈을 실제 줄바꿈으로 바꾸기.
- 사용되지 않는 임포트와 변수를 제거하기.
- 임포트 정렬하기.
- PEP 8 포맷 적용하기.
- 누락된 임포트 추가하기.
CodeGenerationPipeline 정의
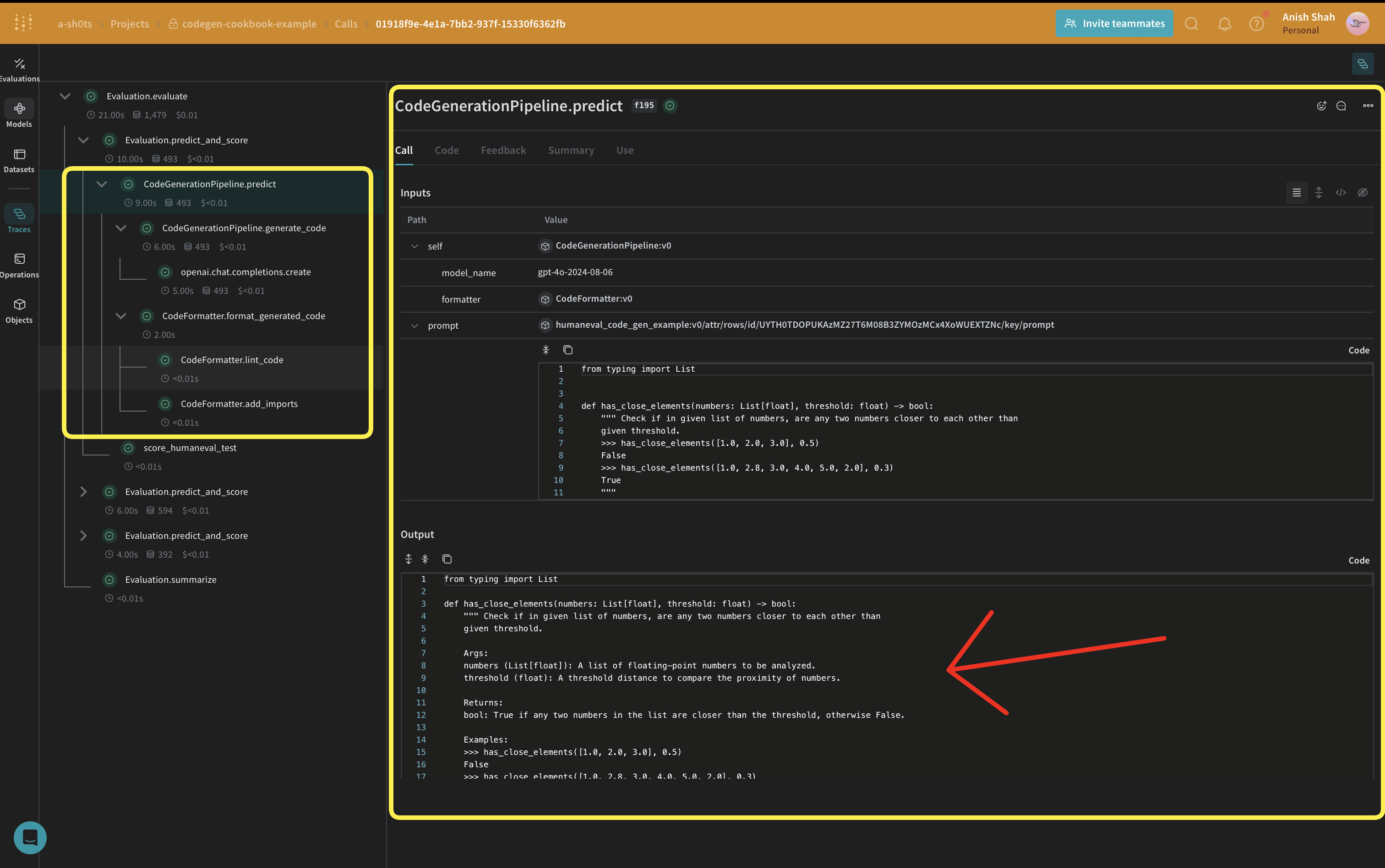
weave.Model을 사용합니다. model_name은 속성으로 유지되므로 이를 바꿔 가며 실험하고, Weave에서 diff로 비교할 수 있습니다. 함수 호출은 @weave.op으로 트래킹되며, 입력과 출력이 로깅되어 오류 추적과 디버깅에 도움이 됩니다.
CodeGenerationPipeline 클래스는 코드 생성 로직을 Weave Model로 캡슐화하며, 다음과 같은 여러 이점을 제공합니다:
- 자동 실험 추적: Weave는 모델의 각 run에 대한 입력, 출력, 파라미터를 자동으로 캡처합니다.
- 버전 관리: 모델의 속성이나 코드 변경 사항이 자동으로 버전 관리되므로, 시간이 지남에 따라 코드 생성 파이프라인이 어떻게 발전하는지 보여주는 이력이 생성됩니다.
- 재현성: 버전 관리와 추적을 통해 코드 생성 파이프라인의 이전 결과나 설정을 언제든지 재현할 수 있습니다.
- 하이퍼파라미터 관리: 모델 속성(
model_name등)이 여러 run 전반에서 정의되고 추적되므로 실험을 더 쉽게 수행할 수 있습니다. - Weave 생태계와의 인테그레이션:
weave.Model을 사용하면 파이프라인을 평가 및 서빙 기능과 같은 다른 Weave 도구와 연결할 수 있습니다.
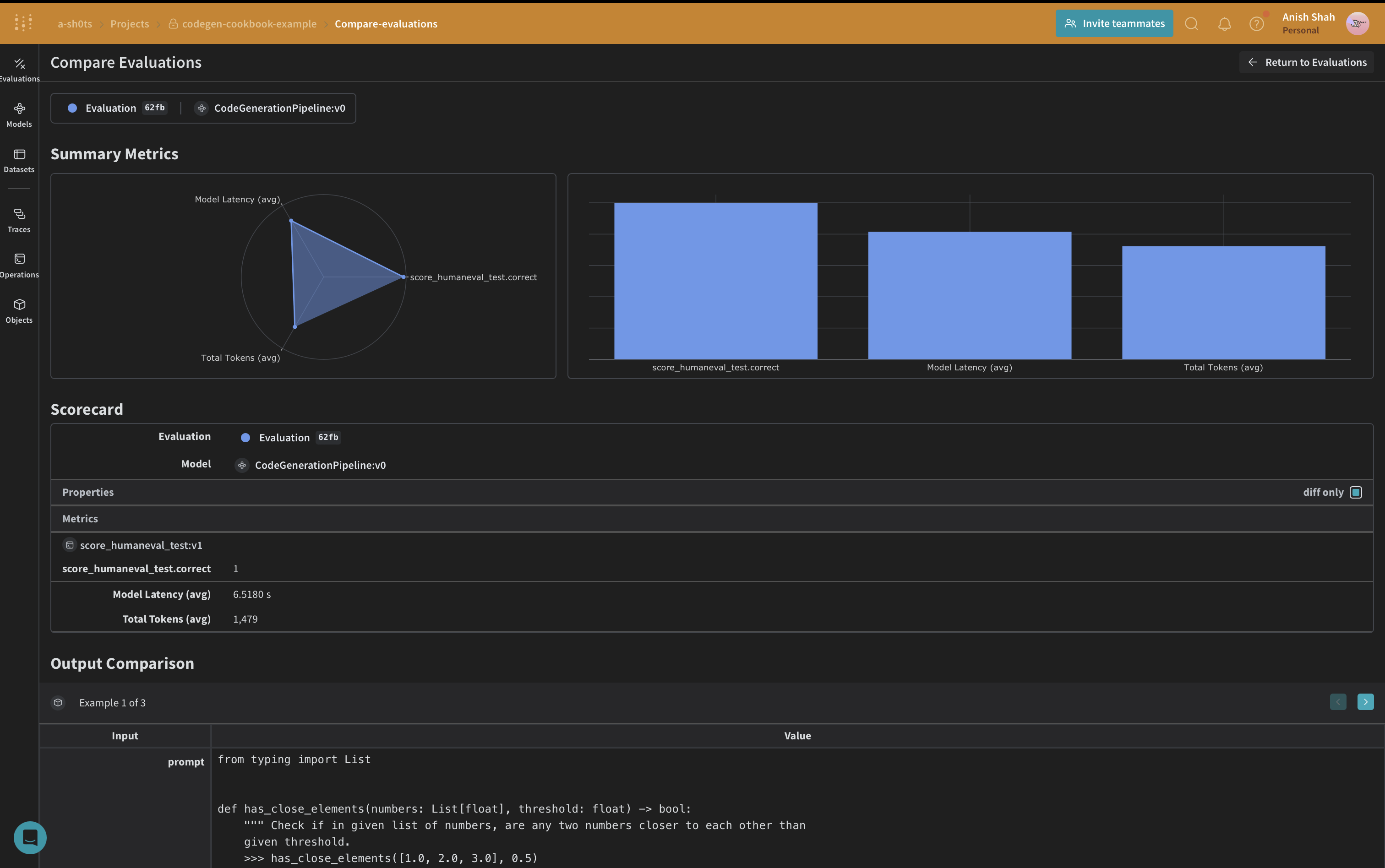
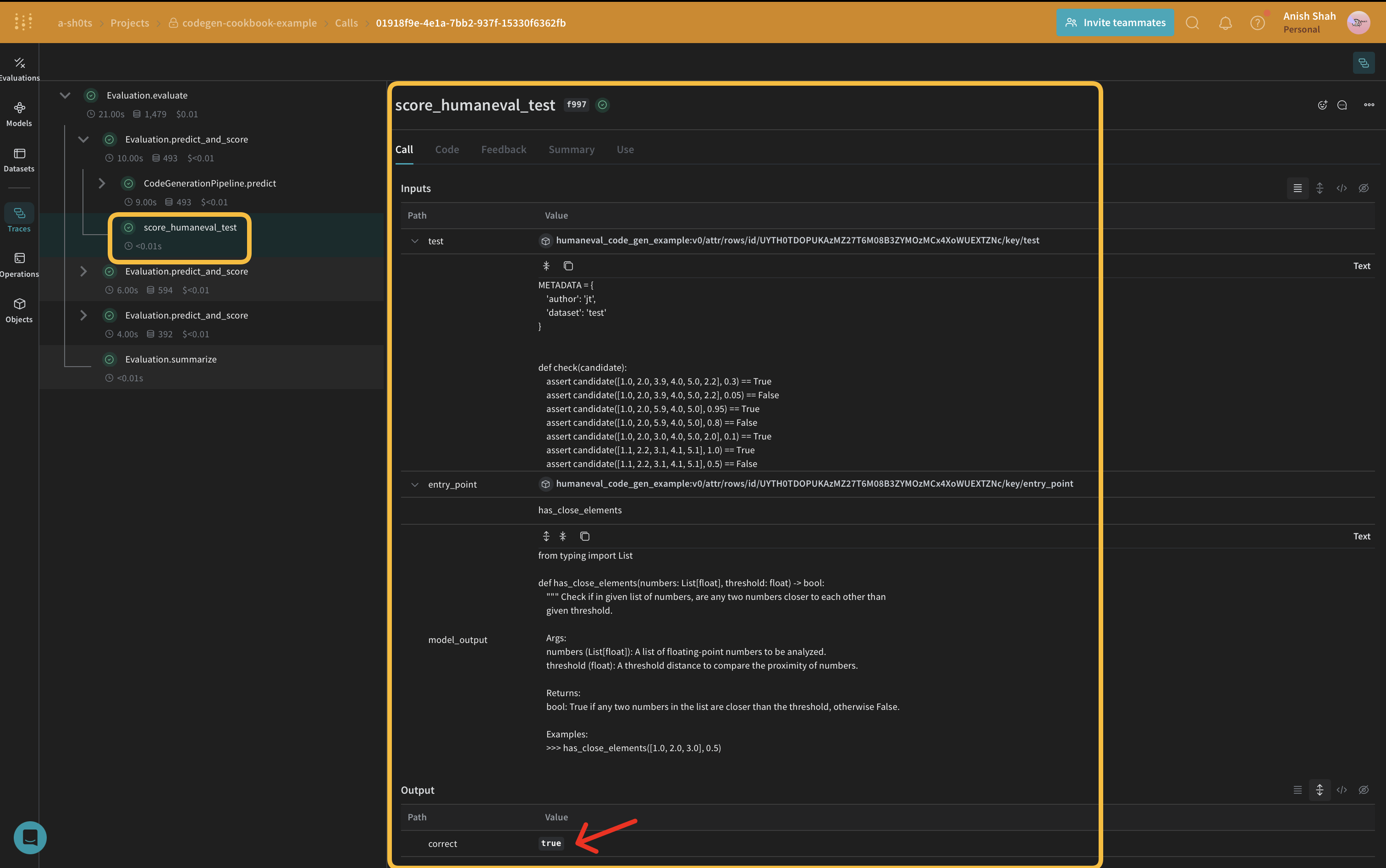
평가 메트릭 구현
weave.Scorer 하위 클래스를 사용해 평가 메트릭을 구현하세요. 이렇게 하면 데이터셋의 각 model_output에 대해 score가 실행됩니다. model_output은 weave.Model의 predict 함수 출력에서 가져오고, prompt는 human-eval 데이터셋에서 가져옵니다.
Weave 데이터셋 만들기 및 평가 실행
결론
- 코드 생성 프로세스의 각 step에 대한 Weave 오퍼레이션 생성.
- 추적과 평가를 쉽게 할 수 있도록 파이프라인을 Weave Model로 래핑.
- Weave 오퍼레이션을 사용한 맞춤형 평가 메트릭 구현.
- 데이터셋을 생성하고 파이프라인 평가 실행.