이 노트북은 대화형 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다:
사전 요구 사항
Weave로 프롬프트를 만들고 반복적으로 개선하기
데이터셋 조회
base64로 인코딩되어 있으므로 LLM이 별도의 전처리 없이 바로 사용할 수 있습니다.
NER 파이프라인 구축하기
- 데이터셋의 PIL 이미지를 받아 VLM에 전달할 수 있는 이미지의
base64인코딩 문자열 표현을 반환하는encode_image함수 - 이미지와 system 프롬프트를 받아, system 프롬프트에 설명된 대로 해당 이미지에서 추출한 엔터티를 반환하는
extract_named_entities_from_image함수
named_entity_recognation이라는 함수를 만드세요. 이 함수는 다음을 수행합니다:
- 이미지 데이터를 NER 파이프라인에 전달합니다.
- 결과를 올바른 형식의 JSON으로 반환합니다.
@weave.op() 데코레이터를 사용하세요.
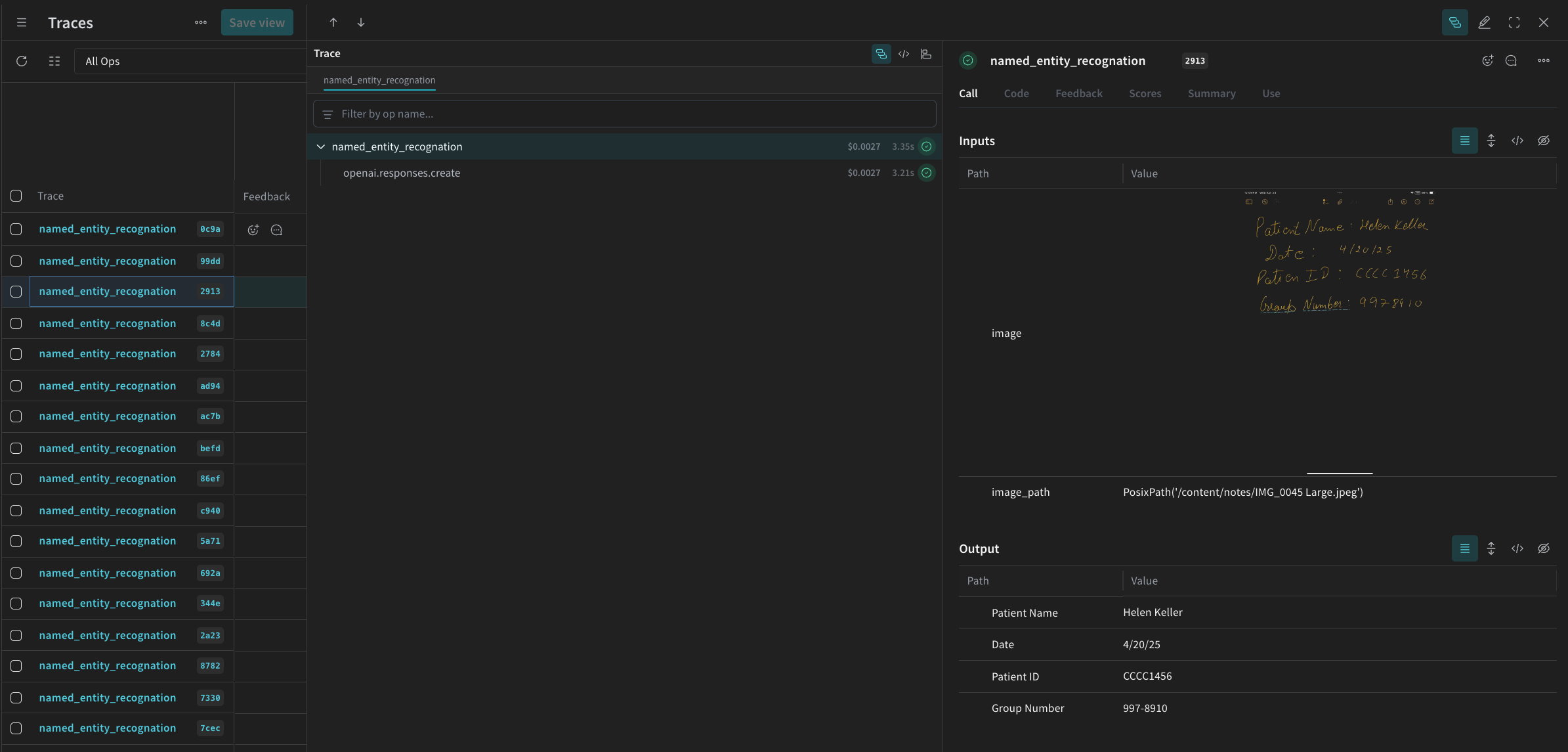
named_entity_recognation이 실행될 때마다 전체 트레이스 결과를 Weave UI에서 볼 수 있습니다. 트레이스를 보려면 Weave 프로젝트의 Traces 탭으로 이동하세요.
processing_results.json에 저장합니다. 결과는 Weave UI에서도 확인할 수 있습니다.
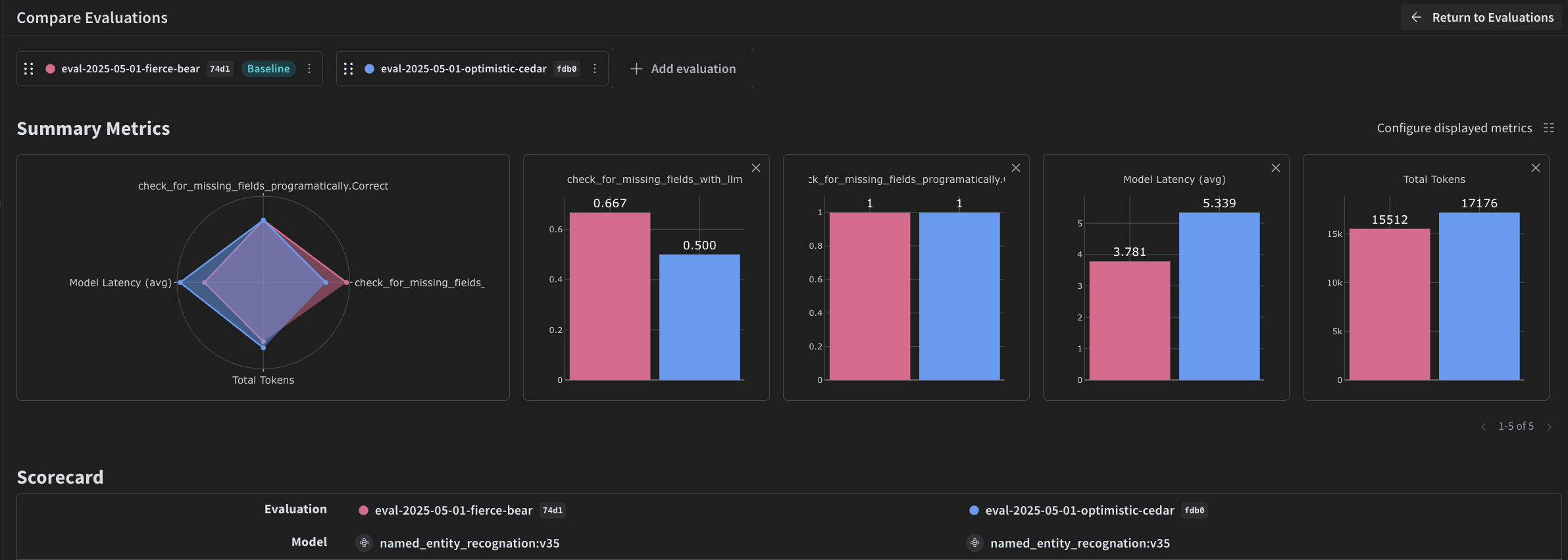
Weave를 사용해 파이프라인 평가하기
- 프로그래매틱 Scorer.
- LLM-as-a-judge Scorer.
프로그램 방식 Scorer
check_for_missing_fields_programatically는 모델 출력(named_entity_recognition 함수의 출력)을 받아 결과에서 누락되었거나 비어 있는 키를 파악합니다.
이 검사는 모델이 어떤 필드도 추출하지 못한 샘플을 식별하는 데 유용합니다.
LLM-as-a-judge scorer
check_for_missing_fields_with_llm은 LLM(구체적으로는 OpenAI의 gpt-4o)을 사용해 점수화를 수행합니다. eval_prompt의 내용에 지정된 대로, check_for_missing_fields_with_llm은 Boolean 값을 출력합니다. 모든 필드가 이미지의 정보와 일치하고 형식도 올바르면 Scorer는 true를 반환합니다. 하나라도 누락되었거나 비어 있거나 올바르지 않거나 일치하지 않는 필드가 있으면 결과는 false가 되며, Scorer는 문제를 설명하는 메시지도 함께 반환합니다.
평가 실행
dataset을 자동으로 순회하며 결과를 Weave UI에 함께 기록하는 평가 call을 정의합니다.
다음 코드는 평가를 시작하고 NER 파이프라인의 모든 출력에 두 개의 Scorer를 적용합니다. 결과는 Weave UI의 Evals 탭에서 확인할 수 있습니다.