EvaluationLogger를 사용해 기존 Python 또는 TypeScript 코드에서 예측과 점수를 기록하는 방법을 보여줍니다. 이를 통해 전체 데이터셋과 Scorer 모음을 먼저 정의하지 않고도 Weave에서 모델 성능을 평가할 수 있습니다.
이 접근 방식은 전체 데이터셋이나 모든 scorer가 처음부터 정의되어 있지 않을 수 있는 복잡한 워크플로에서 특히 유용합니다.
미리 정의된 Dataset과 Scorer 객체 목록이 필요한 표준 Evaluation 객체와 달리, EvaluationLogger를 사용하면 개별 예측과 그에 해당하는 점수를 사용할 수 있게 되는 대로 점진적으로 기록할 수 있습니다.
더 체계적인 평가를 선호하시나요?미리 정의된 데이터셋과 scorer를 갖춘, 더 구조화된 평가 프레임워크를 원한다면 Weave의 표준 Evaluation 프레임워크를 참조하세요.
EvaluationLogger는 유연성을 제공하고, 표준 프레임워크는 구조와 가이드를 제공합니다.기본 워크플로
- 로거 초기화:
EvaluationLogger인스턴스를 생성하고, 필요에 따라model및dataset에 대한 메타데이터를 전달합니다. 생략하면 기본값이 사용됩니다.LLM 호출(예: OpenAI)의 토큰 사용량과 비용을 수집하려면 LLM을 호출하기 **전에EvaluationLogger를 초기화하세요. 먼저 LLM을 호출하고 나중에 예측을 로깅하면 토큰 및 비용 데이터는 수집되지 않습니다. - 예측 로깅: 시스템의 각 입력/출력 쌍에 대해
log_prediction()을 호출합니다. - 점수 로깅: 반환된
ScoreLogger를 사용해 해당 예측에 대한log_score()를 호출합니다. 예측마다 여러 점수를 기록할 수 있습니다. - 예측 완료: 예측을 최종 확정하려면 점수를 로깅한 뒤 항상
finish()를 호출합니다. - 요약 로깅: 모든 예측 처리가 끝나면
log_summary()를 호출해 점수를 집계하고 선택 커스텀 메트릭을 추가합니다.
log_example()을 사용해 2~4단계를 단일 Call로 결합할 수 있습니다.
기본 예제
EvaluationLogger를 사용해 기존 코드에 인라인으로 예측과 점수를 로깅하는 방법을 보여줍니다.
- Python
- TypeScript
user_model 모델 함수는 입력 목록에 대해 정의되며 적용됩니다. 각 예제마다:- 입력과 출력은
log_prediction을 사용해 로깅됩니다. - 정확성 점수(
correctness_score)는log_score를 통해 로깅됩니다. finish()는 해당 예측에 대한 로깅을 마무리합니다.
log_summary는 집계 메트릭을 기록하고 Weave에서 점수 자동 요약을 트리거합니다.log_example()를 사용한 간소화된 로깅
log_example()을 사용하면 입력, 출력, 그리고 점수를 단일 Call로 로깅할 수 있습니다. 이 편의 방법은 log_prediction(), log_score(), finish()를 한 단계로 결합하며, 배치 또는 오프라인 평가 중처럼 로깅할 입력, 모델 출력, 점수가 이미 준비되어 있을 때 유용합니다.
log_example() 호출은 다음과 동일합니다:
Weave TypeScript SDK에서는
log_example()을 사용할 수 없습니다. TypeScript 사용자는 기본 예제에 나와 있는 logPrediction() 및 logScore() 패턴을 사용하세요.고급 활용
EvaluationLogger는 더 복잡한 평가 시나리오를 지원할 수 있도록 기본 워크플로를 넘어서는 유연한 사용 패턴을 제공합니다. 다음 섹션에서는 자동 리소스 관리를 위한 컨텍스트 매니저 사용, 모델 실행과 로깅의 분리, 리치 미디어 데이터 처리, 그리고 여러 모델 평가를 나란히 비교하는 등 고급 기법을 설명합니다.
컨텍스트 관리자 사용
EvaluationLogger는 예측과 점수 모두에 대해 컨텍스트 관리자(with 문)를 지원합니다. 이를 사용하면 코드를 더 깔끔하게 작성할 수 있고, 리소스를 자동으로 정리할 수 있으며, LLM judge Call과 같은 중첩된 오퍼레이션도 더 효과적으로 추적할 수 있습니다.
이 문맥에서 with 문을 사용하면 다음과 같은 이점이 있습니다.
- 컨텍스트를 벗어날 때
finish()가 자동으로 호출됨. - 중첩된 LLM Call에 대한 토큰 및 비용 추적 개선.
- 예측 컨텍스트 내에서 모델 실행 후 출력 설정 가능.
- Python
- TypeScript
기존 데이터셋에 연결하기
log_prediction에 inputs로 전달하면, Weave는 평가 run이 실행될 때마다 데이터를 다시 임포트합니다. 그 결과 중복 데이터가 저장되며, 데이터셋이 크거나 많은 평가에서 이를 재사용하는 경우 저장 공간이 낭비될 수 있습니다.
이 중복을 방지하려면 평가를 실행하기 전에 먼저 데이터셋을 Weave에 게시한 다음, 게시된 데이터셋의 행을 inputs로 전달하세요. 그러면 Weave는 데이터를 다시 임포트하는 대신 내부 참조를 사용해 게시된 행 참조를 해석합니다. 이 방식을 사용하면 표준 Evaluation 프레임워크와 동일하게 연결된 환경을 사용할 수 있으며, 각 예측은 Weave UI의 특정 데이터셋 행에 다시 연결됩니다.
다음 예제에서는 데이터셋을 게시하고 이를 EvaluationLogger에 연결한 뒤, 다른 데이터셋과 마찬가지로 조회하고 순회합니다.
- Python
- TypeScript
로깅 전에 출력 먼저 계산하기
- Python
- TypeScript
리치 미디어 로깅
log_prediction 또는 log_score 메서드에 dict 또는 미디어 객체를 전달하면 됩니다.
- Python
- TypeScript
여러 평가 기록 및 비교
EvaluationLogger를 사용하면 Weave UI에서 여러 평가를 나란히 기록하고 비교할 수 있습니다. 이는 동일한 데이터셋에서 서로 다른 모델의 성능을 평가하는 데 유용합니다.
- 다음 코드 샘플을 실행합니다.
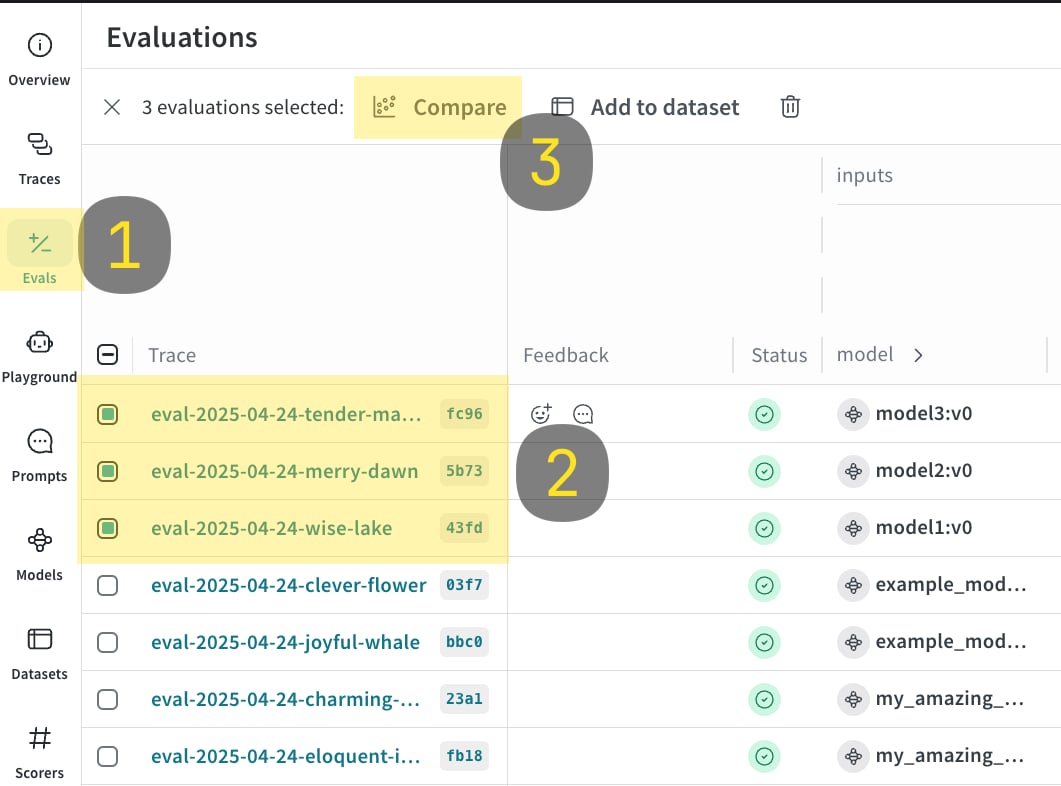
- Weave UI에서
Evals탭으로 이동합니다. - 비교하려는 eval을 선택합니다.
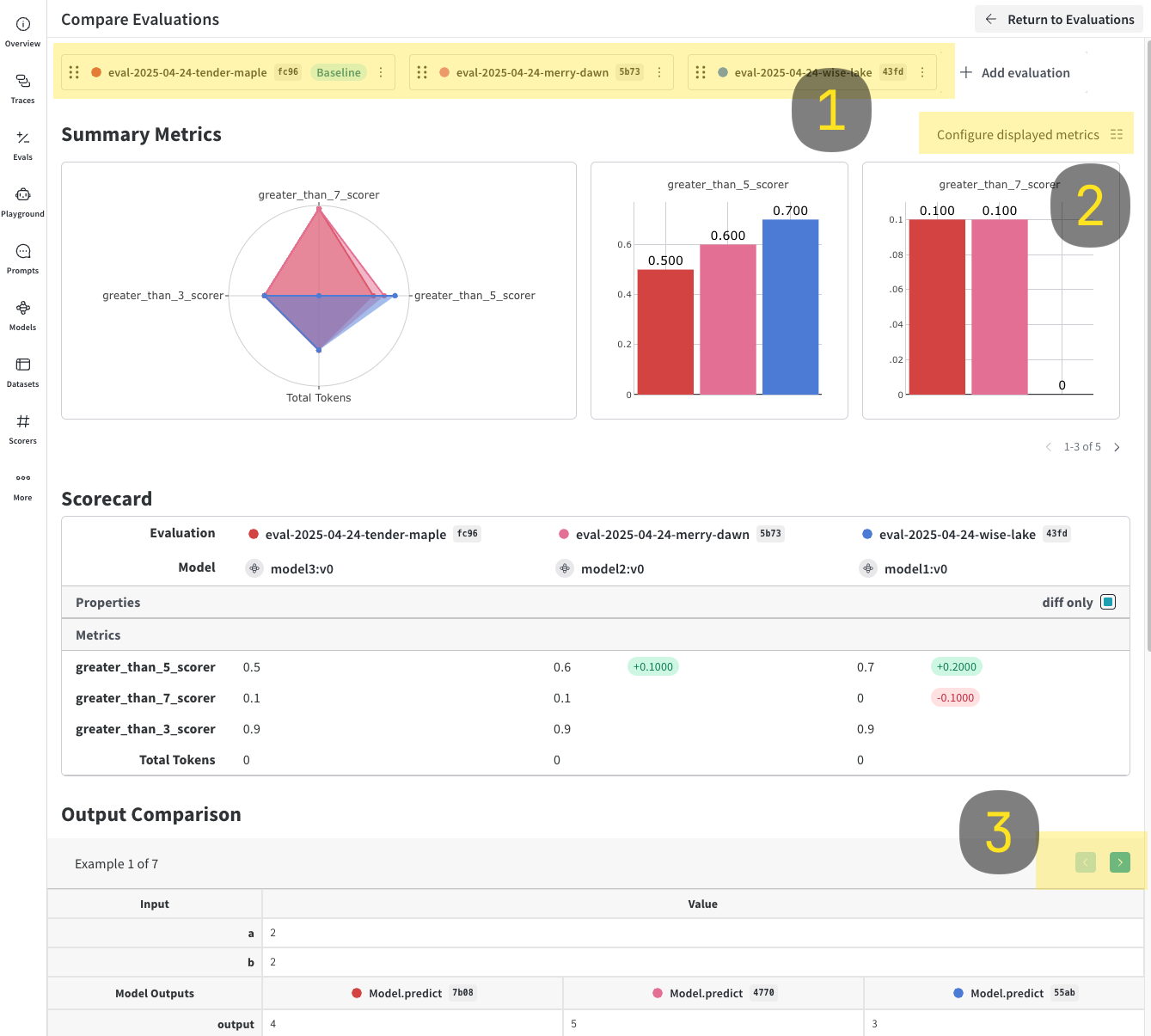
- Compare 버튼을 클릭합니다. Compare 뷰에서 다음 작업을 할 수 있습니다.
- 추가하거나 제거할 Evals 선택.
- 표시하거나 숨길 메트릭 선택.
- 특정 예제를 페이지별로 살펴보며, 주어진 데이터셋에서 동일한 입력에 대해 서로 다른 모델이 어떻게 수행되었는지 확인.
- Python
- TypeScript
사용 팁
EvaluationLogger를 최대한 효과적으로 사용할 수 있습니다.
- Python
- TypeScript
- 각 예측 후에는 즉시
finish()를 호출하세요. - 개별 예측에 연결되지 않은 메트릭(예를 들어, 전체 지연 시간)을 캡처하려면
log_summary를 사용하세요. - 리치 미디어 로깅은 정성적 분석에 매우 유용합니다.