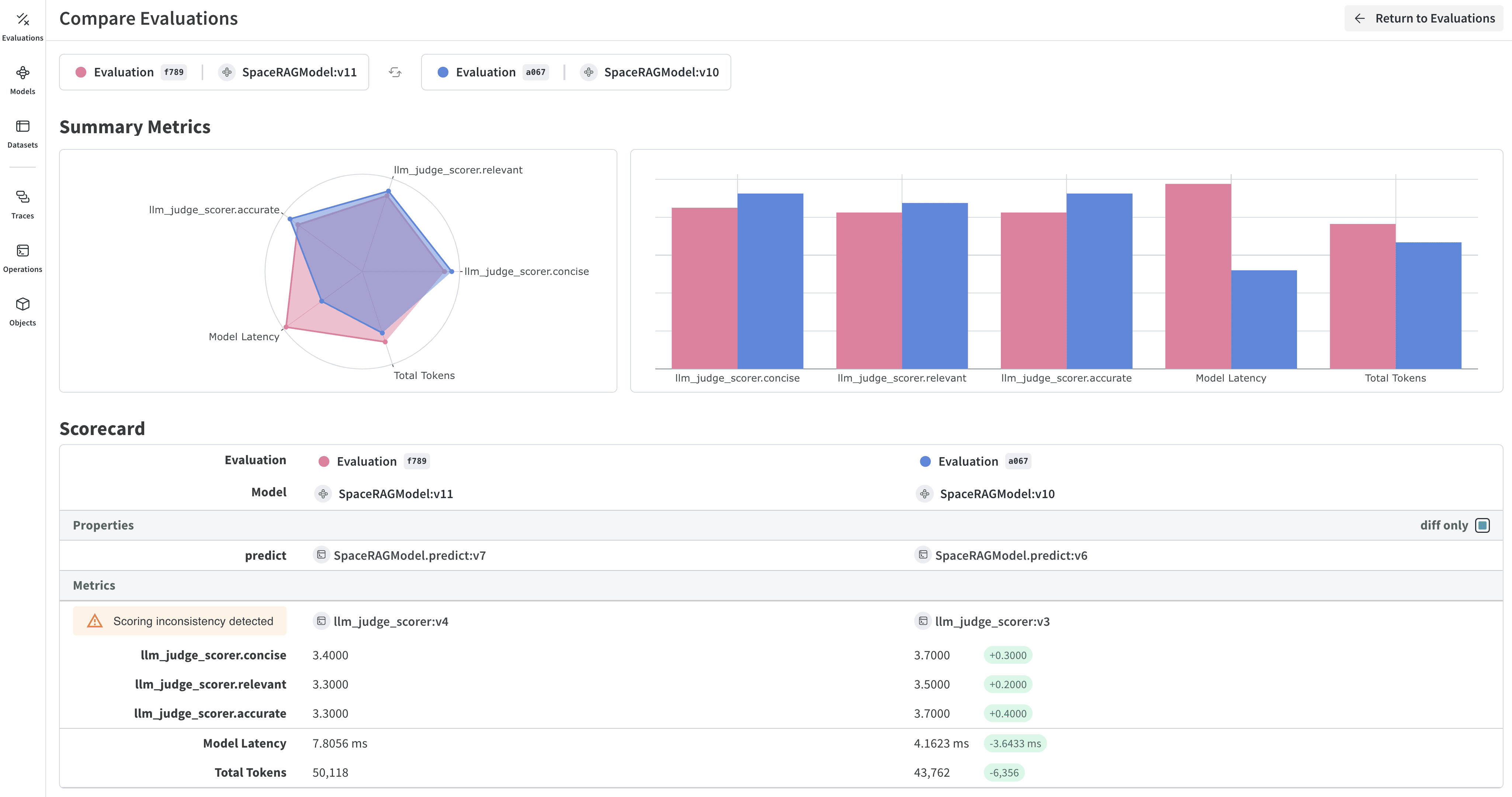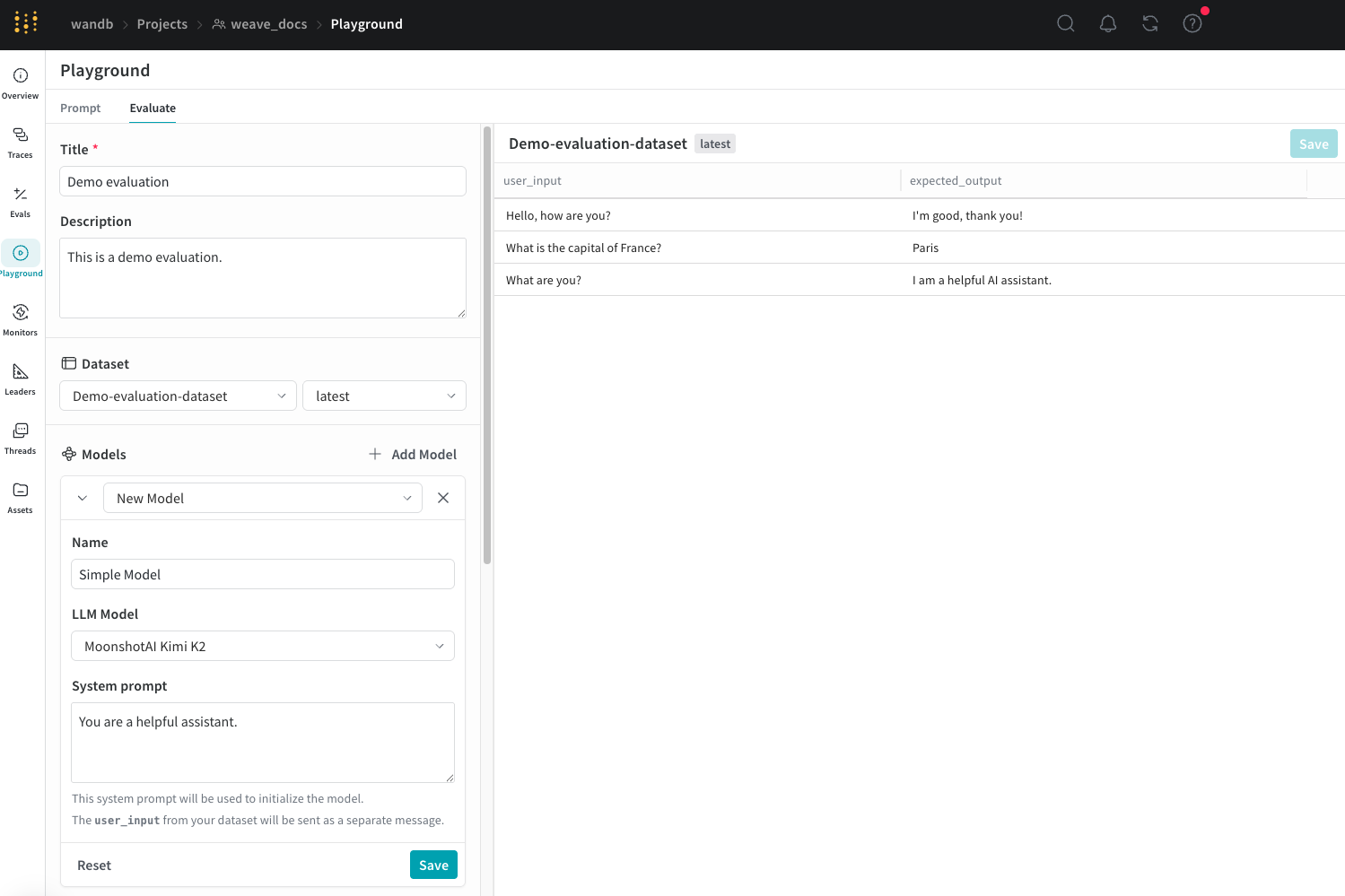
플레이그라운드에서 평가 설정
- Weave UI를 연 다음, 평가를 수행할 프로젝트를 엽니다. 그러면 Traces 페이지가 열립니다.
- Traces 페이지에서 왼쪽 메뉴의 Playground 아이콘을 클릭한 다음, Playground 페이지에서 Evaluate 탭을 선택합니다. Evaluate 페이지에서는 다음 중 하나를 선택할 수 있습니다.
- Load a demo example: 예상 출력 기준으로 MoonshotAI Kimi K2 모델을 평가하고, 정확성 판별에 LLM 기반 평가자를 사용하는 미리 정의된 설정을 불러옵니다. 이 설정을 사용해 인터페이스를 시험해 볼 수 있습니다.
- Start from scratch: 이후에 직접 구성할 수 있도록 빈 설정을 불러옵니다.
- Start from scratch를 선택한 경우, Title 및 Description 필드에 평가의 제목과 설명을 입력합니다.
데이터셋 추가
.csv.tsv.json.jsonl
- 드롭다운 메뉴를 클릭한 다음 다음 중 하나를 선택합니다.
- UI에서 새 데이터셋을 만들려면 Start from scratch를 선택합니다.
- 로컬 컴퓨터에서 데이터셋을 업로드하려면 Upload a file을 선택합니다.
- 또는 프로젝트에 이미 저장된 기존 데이터셋을 선택합니다.
- 선택 사항: 나중에 사용할 수 있도록 데이터셋을 프로젝트에 저장하려면 Save를 클릭합니다.
UI에서는 새 데이터셋만 편집할 수 있습니다.또한 Scorer가 데이터에 액세스할 수 있도록 데이터셋의 열 이름을
user_input 및 expected_output으로 지정하는 것도 중요합니다.모델 추가
- Add Model을 클릭한 다음 드롭다운 메뉴에서 New Model 또는 기존 모델을 선택합니다.
-
New Model을 선택한 경우 다음 필드를 설정합니다.
- Name: 새 모델을 잘 설명하는 이름을 입력합니다.
- LLM Model: OpenAI의 GPT-4처럼 새 모델의 기반이 될 파운데이션 모델을 선택합니다. 이미 액세스를 설정한 파운데이션 모델 목록에서 선택할 수 있으며, Add AI provider를 선택한 뒤 모델을 선택해 파운데이션 모델에 대한 액세스를 추가할 수도 있습니다. provider를 추가하면 해당 provider의 액세스 자격 증명을 입력하라는 메시지가 표시됩니다. Weave를 사용해 모델에 액세스하는 데 필요한 API 키, endpoints, 기타 설정 정보를 어디서 확인할 수 있는지는 provider 문서를 참조하세요.
- System Prompt: 예를 들어
You are a helpful assistant specializing in Python programming.처럼 모델이 어떻게 동작해야 하는지에 대한 지침을 입력합니다. 데이터셋의user_input는 다음 메시지로 전송되므로 시스템 프롬프트에 포함할 필요가 없습니다.
- 선택 사항: Save를 클릭해 나중에 사용할 수 있도록 모델을 프로젝트에 저장합니다.
- 선택 사항: 여러 모델을 동시에 평가하려면 Add Model을 다시 클릭하고 필요에 따라 다른 모델을 추가합니다.
Scorer 추가
-
Add Scorer를 클릭한 다음, 다음 필드를 설정합니다.
- Name: Scorer를 잘 설명하는 이름을 추가합니다.
-
Type: 점수 출력 방식을 선택합니다. 불리언 또는 숫자 중 하나를 선택할 수 있습니다. 불리언 Scorer는 모델 출력이 설정한 평가 파라미터를 충족했는지에 따라
True또는False의 이진값을 반환합니다. 숫자 Scorer는0에서1사이의 점수를 출력하여 모델 출력이 평가 파라미터를 얼마나 잘 충족했는지에 대한 전반적인 점수를 제공합니다. - LLM-as-a-judge-model: Scorer의 평가자로 사용할 파운데이션 모델을 선택합니다. Models 섹션의 LLM Model 필드와 마찬가지로, 이미 액세스를 설정한 파운데이션 모델 중에서 선택하거나 파운데이션 모델에 대한 새 액세스를 설정할 수 있습니다.
-
Scoring Prompt: 출력에서 무엇을 평가할지에 대한 LLM 기반 평가자의 파라미터를 입력합니다. 예를 들어 환각 여부를 확인하려는 경우, 다음과 비슷한 scoring prompt를 입력할 수 있습니다.
{user_input},{expected_output},{output}처럼 데이터셋과 응답의 필드를 scoring prompt에서 변수로 사용할 수 있습니다. 사용 가능한 변수 목록을 보려면 UI에서 Insert variable을 클릭합니다.
- 선택 사항: 나중에 사용할 수 있도록 Scorer를 프로젝트에 저장하려면 Save를 클릭합니다.
평가 실행
- Evaluation Playground에서 평가를 실행하려면 Run eval을 클릭합니다.
평가 결과 검토