This is an interactive notebook. You can run it locally or use the links below:
What is chain of density summarization
- Starting with an initial summary
- Iteratively refining the summary, making it more concise while preserving key information
- Increasing the density of entities and technical details with each iteration
Why use Weave
In this tutorial, you’ll use Weave to implement and evaluate a Chain of Density summarization pipeline for ArXiv papers. You’ll learn how to:- Track your LLM pipeline: Use Weave to automatically log inputs, outputs, and intermediate steps of your summarization process.
- Evaluate LLM outputs: Create consistent evaluations of your summaries using Weave’s built-in tools.
- Build composable operations: Combine and reuse Weave operations across different parts of your summarization pipeline.
- Integrate with existing code: Add Weave to your existing Python code with minimal overhead.
Set up the environment
First, set up the environment and import the necessary libraries. This step installs the dependencies needed for the pipeline, including Weave for tracking, Anthropic for the LLM, and PyPDF2 for reading ArXiv PDFs.To get an Anthropic API key:
- Sign up for an account at https://www.anthropic.com.
- Navigate to the API section in your account settings.
- Generate a new API key.
- Store the API key securely in your
.envfile.
weave.init([PROJECT_NAME]) call sets up a new Weave project for the summarization task.
Define the ArxivPaper model
With the environment ready, the next step is to define the data structure the pipeline operates on. Create anArxivPaper class to represent the data:
Load PDF content
TheArxivPaper model holds metadata and a PDF URL, but the summarization pipeline needs the full text of the paper. To work with the full paper content, add a function to load and extract text from PDFs:
Implement Chain of Density summarization
Now, implement the core CoD summarization logic using Weave operations: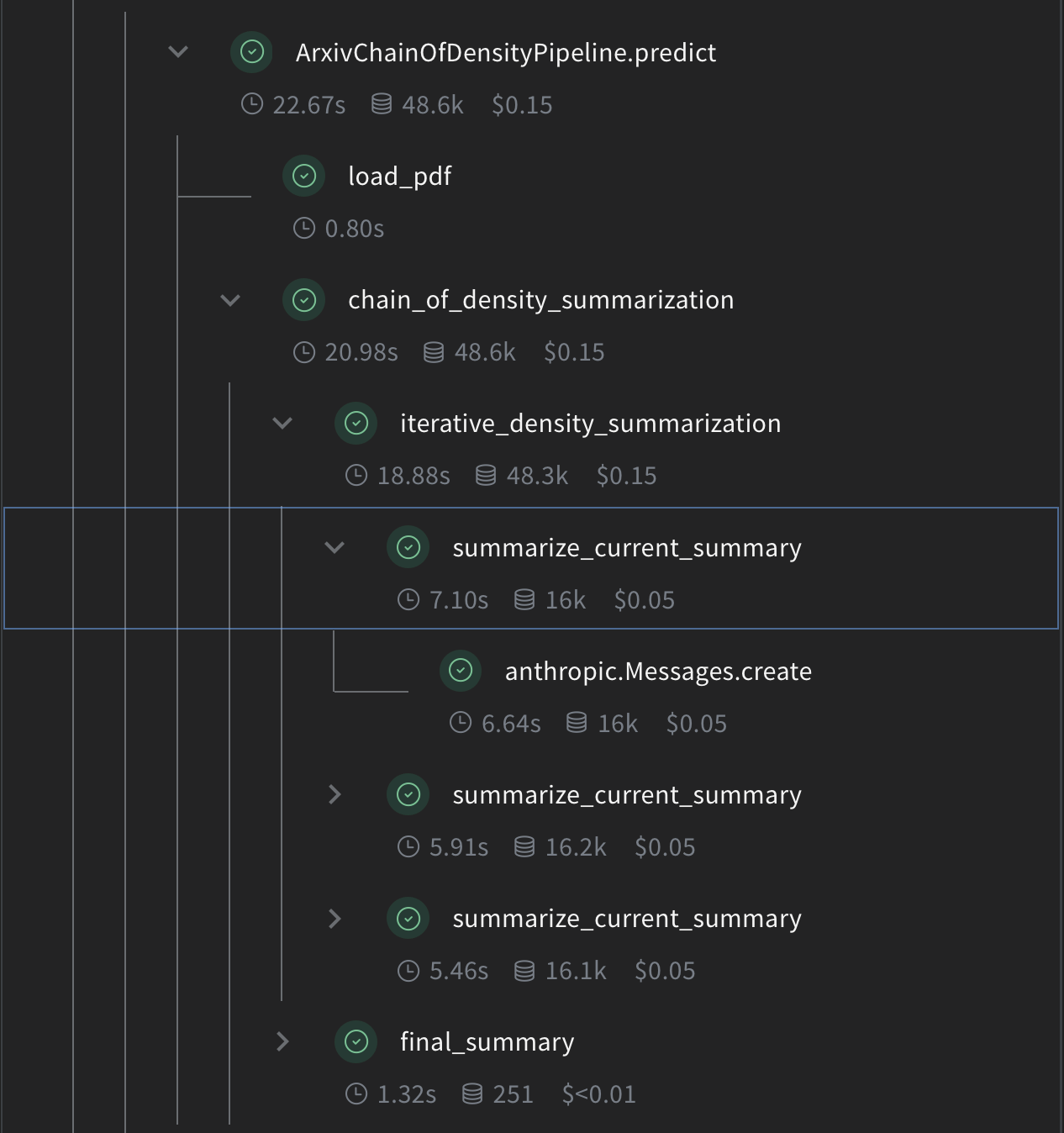
summarize_current_summary: Generates a single summary iteration based on the current state.iterative_density_summarization: Applies the CoD technique by callingsummarize_current_summarymultiple times.chain_of_density_summarization: Orchestrates the entire summarization process and returns the results.
@weave.op() decorators ensure that Weave tracks the inputs, outputs, and execution of these functions.
Create a Weave Model
With the summarization functions in place, the next step is to package them as a Weave Model so that runs, parameters, and versions are tracked together. Now, wrap the summarization pipeline in a Weave Model: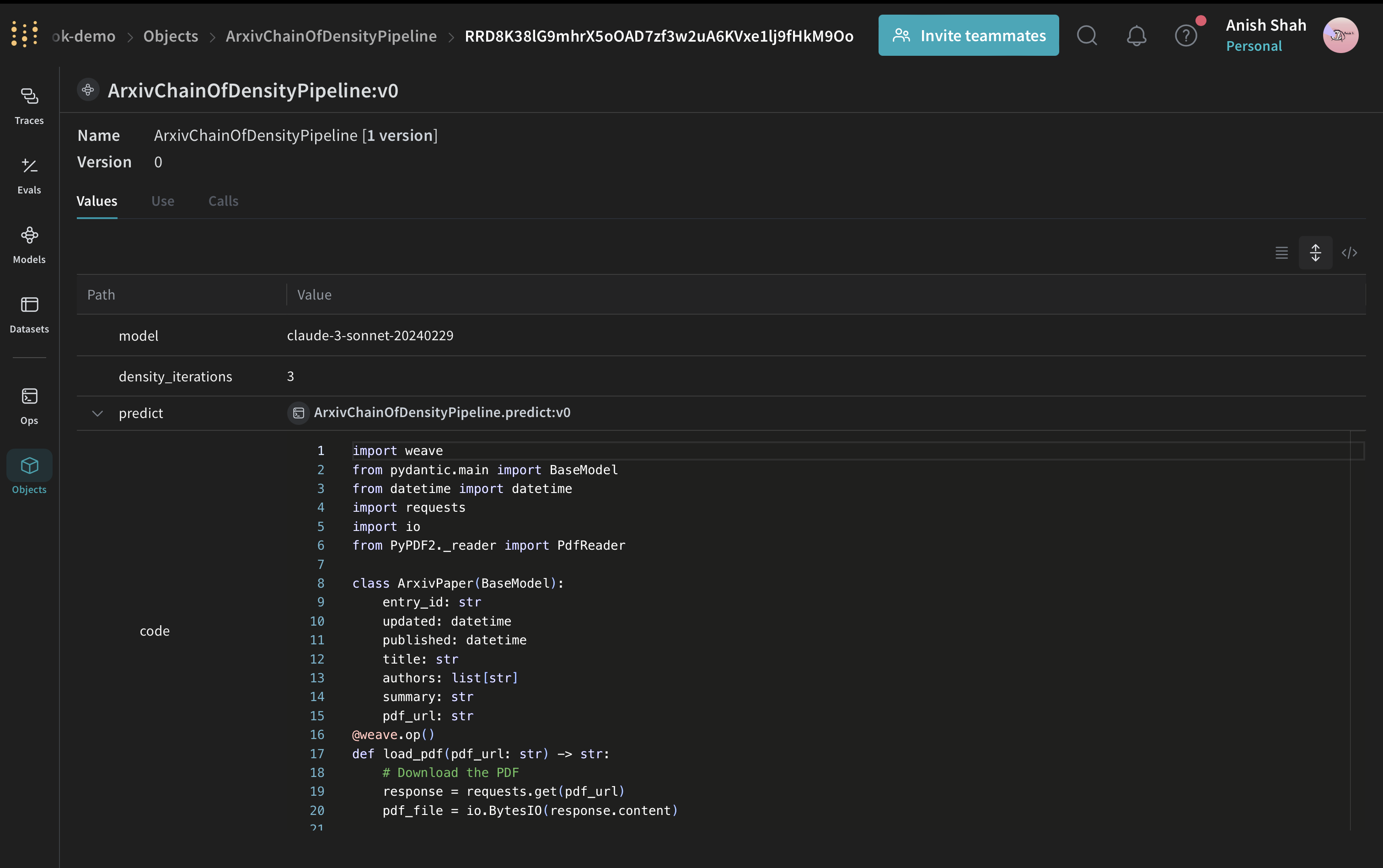
ArxivChainOfDensityPipeline class encapsulates the summarization logic as a Weave Model, providing several key benefits:
- Automatic experiment tracking: Weave captures inputs, outputs, and parameters for each run of the model.
- Versioning: Changes to the model’s attributes or code are automatically versioned, creating a clear history of how your summarization pipeline evolves over time.
- Reproducibility: The versioning and tracking let you reproduce any previous result or configuration of your summarization pipeline.
- Hyperparameter management: Model attributes (like
modelanddensity_iterations) are clearly defined and tracked across different runs, facilitating experimentation. - Integration with Weave ecosystem: Using
weave.Modelworks with other Weave tools, such as evaluations and serving capabilities.
Implement evaluation metrics
With the pipeline producing summaries, you need a way to measure their quality systematically. To assess the quality of the summaries, implement simple evaluation metrics:Create a Weave Dataset and run evaluation
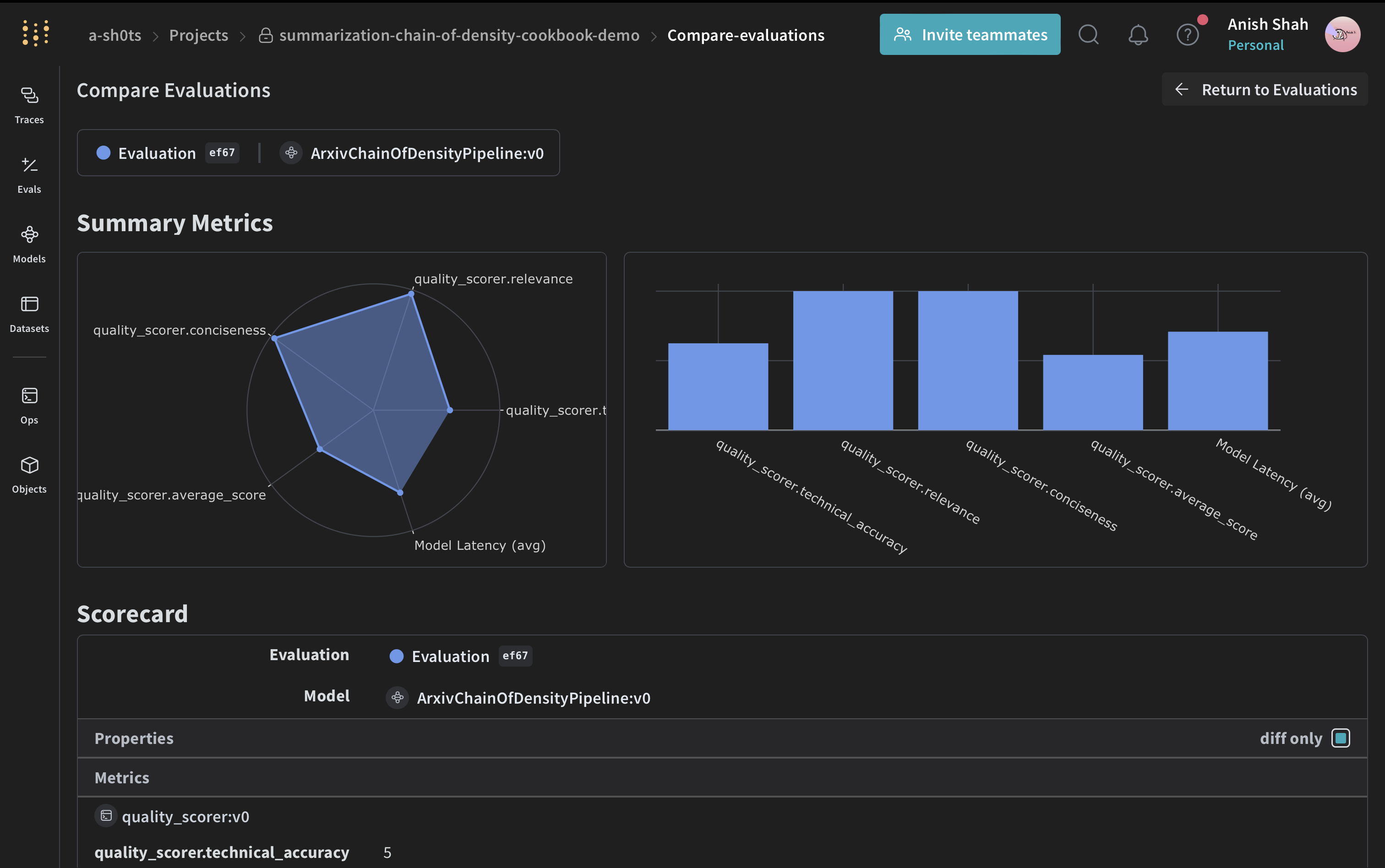
Now that the scoring function is defined, the final step is to apply it to sample inputs and execute the evaluation. To evaluate the pipeline, create a Weave Dataset and run an evaluation: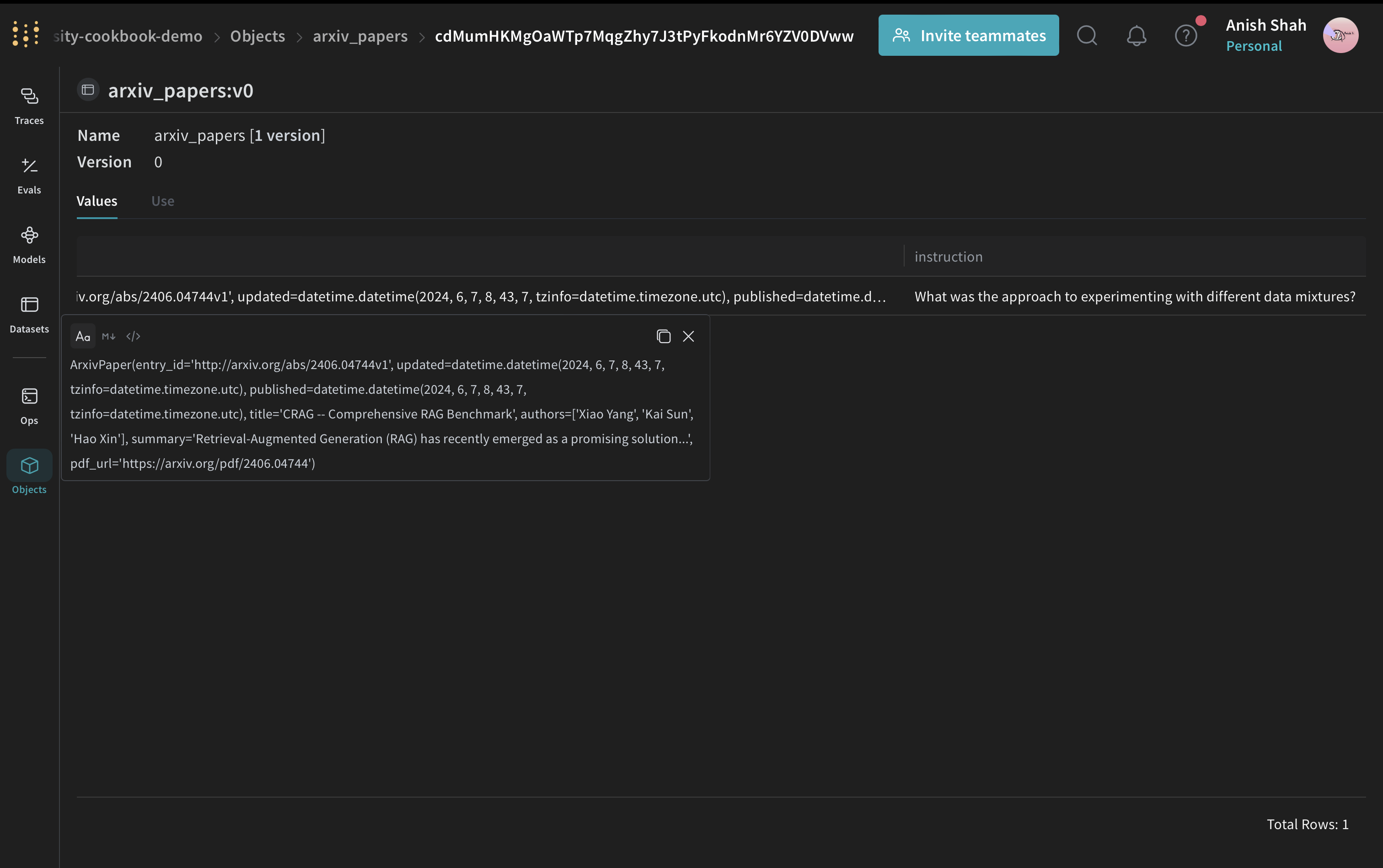
Conclusion
This example demonstrated how to implement a Chain of Density summarization pipeline for ArXiv papers using Weave. You learned how to:- Create Weave operations for each step of the summarization process
- Wrap the pipeline in a Weave Model for tracking and evaluation
- Implement custom evaluation metrics using Weave operations
- Create a dataset and run an evaluation of the pipeline