This is an interactive notebook. You can run it locally or use the following links:
Routing prompts
This section explains why custom routing is useful when working with multiple LLMs. When building complex LLM workflows, you may need to prompt different models according to accuracy, cost, or call latency. You can use Not Diamond to route prompts in these workflows to the right model for your needs, helping maximize accuracy while saving on model costs. For any given distribution of data, rarely does a single model outperform every other model on every query. By combining multiple models into a “meta-model” that learns when to call each LLM, you can beat every individual model’s performance and even drive down costs and latency.Custom routing
The following inputs are required to train a custom router for your prompts:- A set of LLM prompts: Prompts must be strings and should be representative of the prompts used in your application.
- LLM responses: The responses from candidate LLMs for each input. Candidate LLMs can include both supported LLMs and your own custom models.
- Evaluation scores for responses to the inputs from candidate LLMs: Scores are numbers, and can be any metric that fits your needs.
Set up the training data
In this section, you prepare the training and test data that the custom router learns from. In practice, you use your own Evaluations to train a custom router. For this example notebook, however, you use LLM responses for the HumanEval dataset to train a custom router for coding tasks. Start by downloading the dataset prepared for this example, then parse LLM responses intoEvaluationResults for each model. This split of training and test data is used in later sections to train the router and to evaluate its out-of-sample performance.
Train a custom router
With theEvaluationResults prepared, you can now submit them to Not Diamond to train a custom router. Make sure you have created an account and
generated an API key, then insert your API key in the following code. The API key authenticates the training request.
Evaluate your custom router
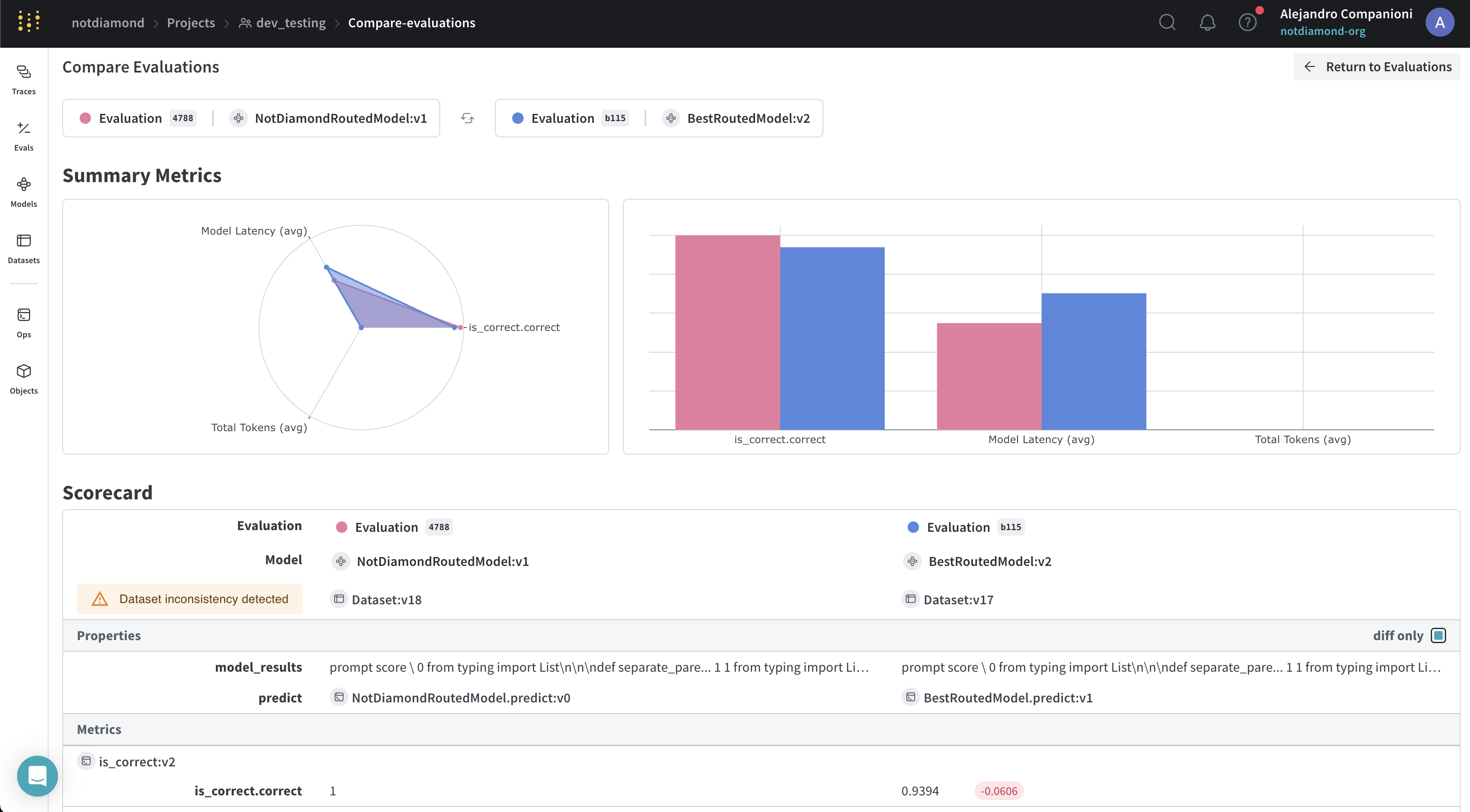
This section shows how to measure whether the custom router improves on the best individual model. Once you’ve trained your custom router, you can evaluate its performance in one of the following ways:- In-sample performance by submitting the training prompts.
- Out-of-sample performance by submitting new or held-out prompts.