weave.init().
Traces
cohere-python. Utilisez la bibliothèque comme d’habitude. Commencez par appeler weave.init() :
weave.init(), Weave utilise votre entité par défaut. Pour trouver ou mettre à jour votre entité par défaut, reportez-vous à Paramètres utilisateur dans la documentation W&B Models.
Les modèles Cohere prennent en charge les connecteurs, qui vous permettent d’effectuer des requêtes vers d’autres API au niveau du point de terminaison. La réponse contient alors le texte généré avec des éléments de citation renvoyant vers les documents retournés par le connecteur.
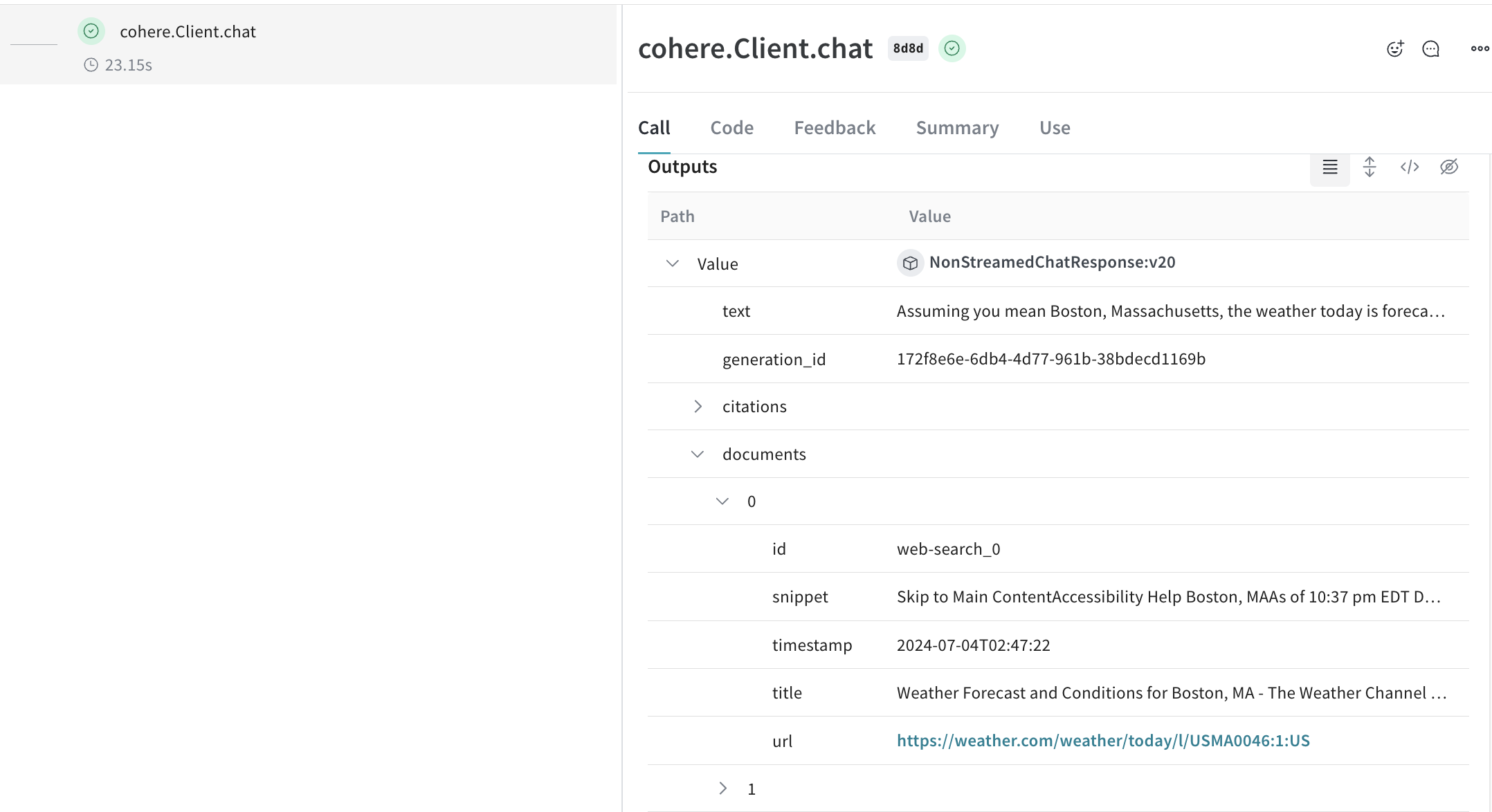
Weave patch les méthodes Cohere
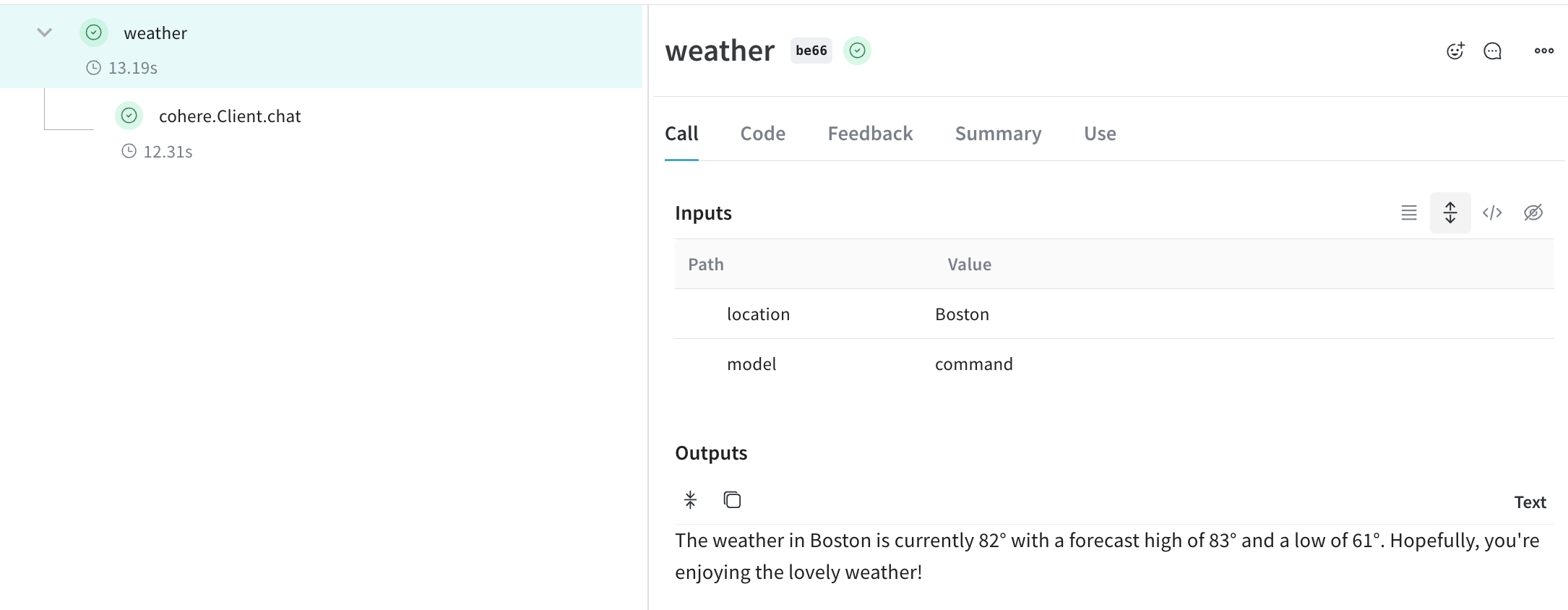
Client.chat(), AsyncClient.chat(), Client.chat_stream() et AsyncClient.chat_stream() pour suivre vos appels LLM.Encapsulez avec vos propres ops
@weave.op() qui appelle les méthodes de chat de Cohere, et Weave suit les entrées et les sorties pour vous. Voici un exemple :
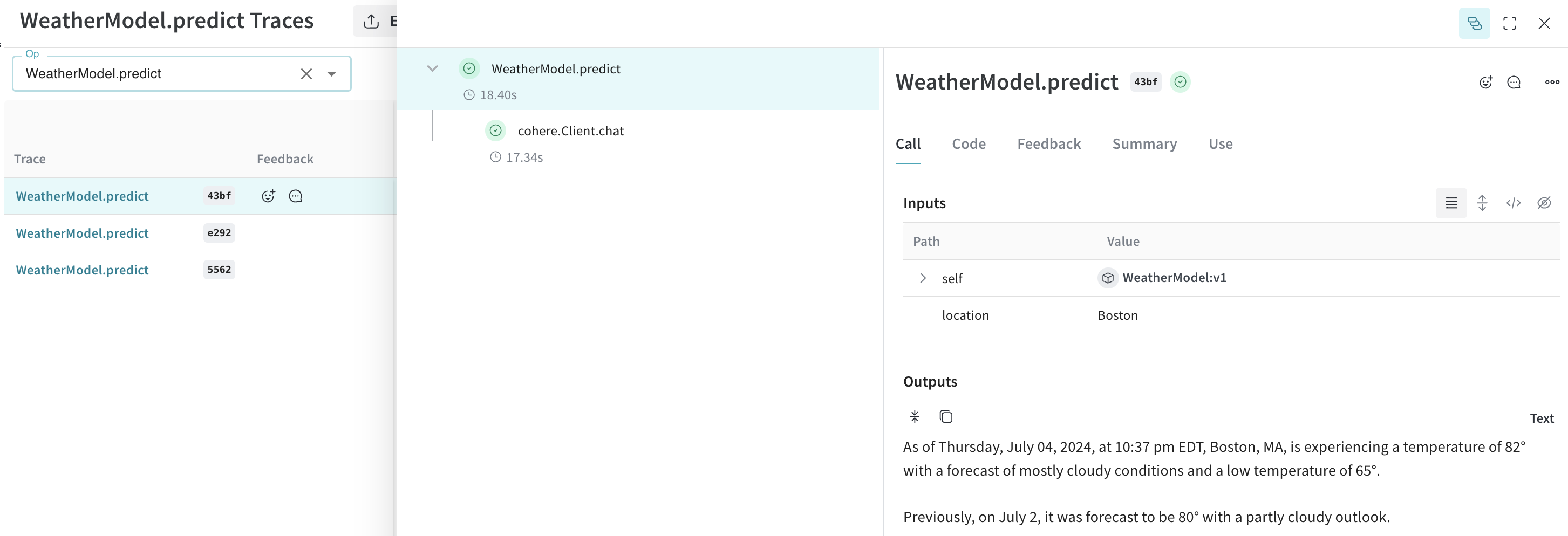
Créez un Model pour faciliter l’expérimentation
Model, vous pouvez capturer et organiser les détails expérimentaux de votre application, comme votre prompt système ou le modèle que vous utilisez. Cela facilite l’organisation et la comparaison des différentes itérations de votre application.
Au-delà de la gestion des versions du code et de la capture des entrées/sorties, les Models capturent des paramètres structurés qui contrôlent le comportement de votre application, vous aidant à identifier les paramètres les plus efficaces. Vous pouvez également utiliser les Weave Models avec serve et les Évaluations.
Dans l’exemple suivant, vous pouvez expérimenter avec model et temperature. Chaque fois que vous modifiez l’un d’eux, vous obtenez une nouvelle version de WeatherModel.