weave.init() exécuté. Ce guide explique comment utiliser Weave avec LiteLLM pour capturer les traces, encapsuler les appels dans des ops versionnées, organiser les expériences avec un Model et suivre le comportement des appels de fonction. Utilisez-le lorsque vous développez des applications LLM et souhaitez une observabilité sur les multiples fournisseurs de modèles pris en charge par LiteLLM.
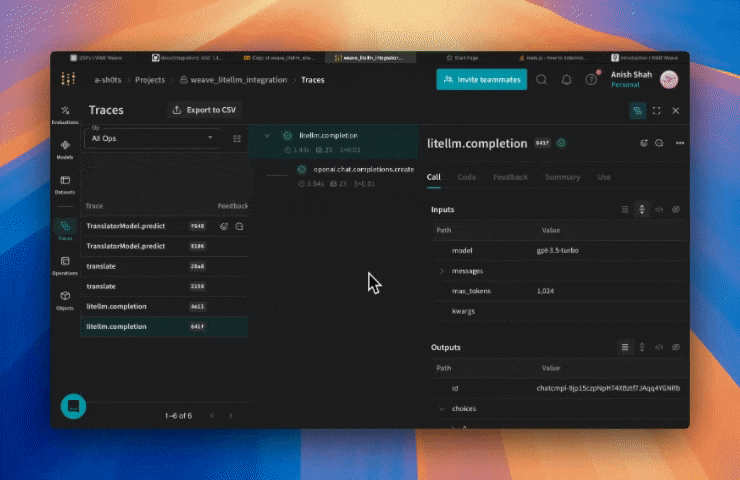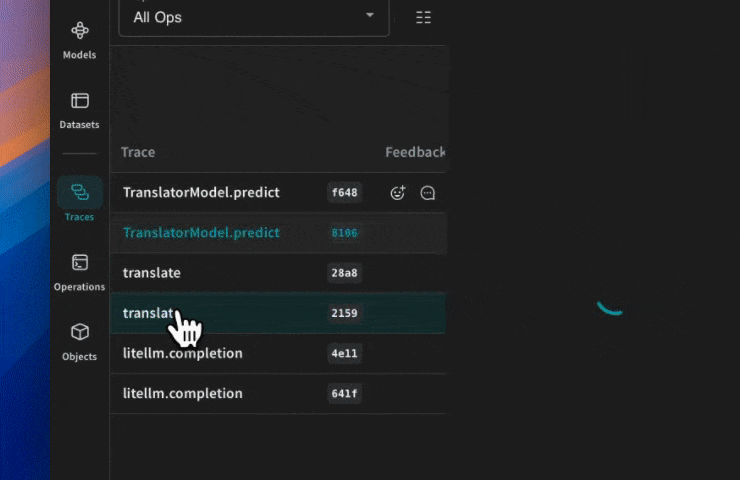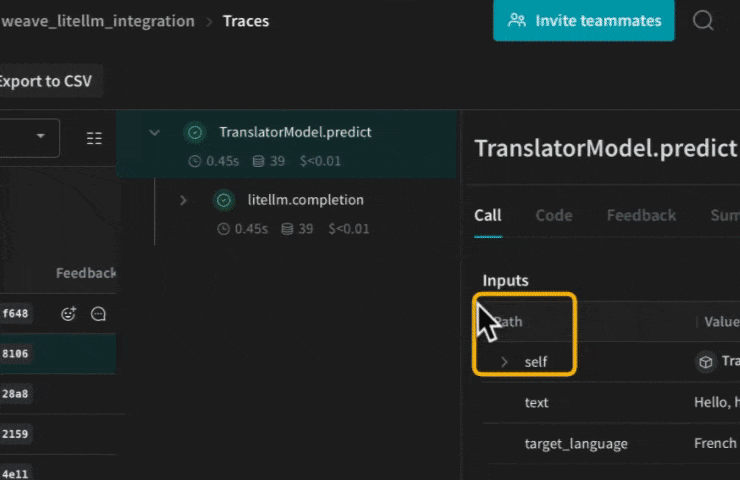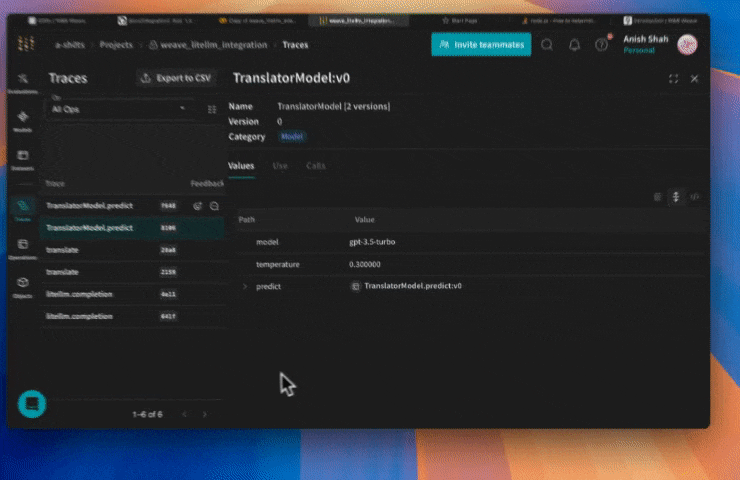
Traces
Remarque : Lorsque vous utilisez LiteLLM, veillez à importer la bibliothèque avecWeave capture automatiquement les traces pour LiteLLM. Utilisez la bibliothèque comme d’habitude et commencez par appelerimport litellmet à appeler la fonction de complétion aveclitellm.completion()plutôt quefrom litellm import completion. Cela garantit que toutes les fonctions et tous les paramètres sont correctement référencés.
weave.init() :
Utiliser vos propres ops
@weave.op() qui appelle la fonction de complétion de LiteLLM, et Weave suit pour vous les entrées et les sorties. Voici un exemple :
Créez un Model pour expérimenter plus facilement
Model, vous pouvez capturer et structurer les détails expérimentaux de votre application, comme le prompt système ou le modèle que vous utilisez. Cela vous aide à organiser et à comparer les différentes itérations de votre application.
En plus de la gestion des versions du code et de la capture des entrées et des sorties, les Models capturent des paramètres structurés qui contrôlent le comportement de votre application, ce qui vous aide à trouver quels paramètres fonctionnent le mieux. Vous pouvez également utiliser les Weave Models avec serve et les Évaluations.
Dans l’exemple suivant, vous pouvez tester différents modèles et différentes températures :
Appels de fonction