Vous voulez tester les modèles Groq sur Weave sans rien configurer ? Essayez le LLM Playground.
Model.
Tracing
weave.init(project_name="<your-wandb-project-name>") et utilisez la bibliothèque normalement. Remplacez les valeurs entre <> par les vôtres.
 |
|---|
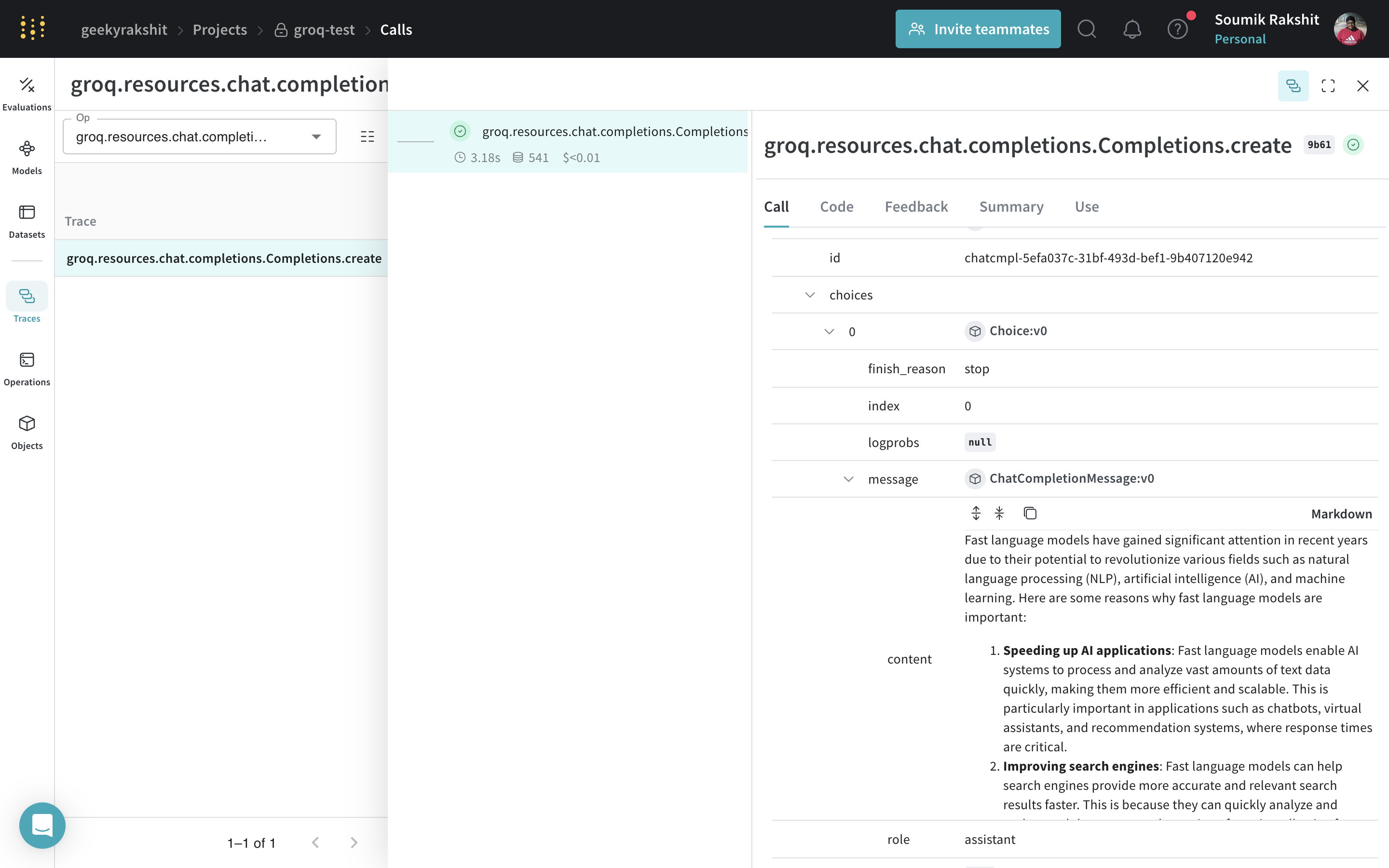
| Weave suit et journalise désormais tous les appels LLM effectués via la bibliothèque Groq. Vous pouvez consulter les traces dans l’interface web de Weave. |
Suivez vos propres ops
@weave.op pour capturer les entrées, les sorties et la logique de l’application afin que vous puissiez déboguer la façon dont les données circulent dans votre application. Vous pouvez imbriquer des ops en profondeur et créer une arborescence de fonctions que vous souhaitez suivre. Cela gère également automatiquement les versions du code pendant que vous expérimentez, afin de capturer des détails ad hoc qui n’ont pas été commités dans git.
Créez une fonction décorée avec @weave.op.
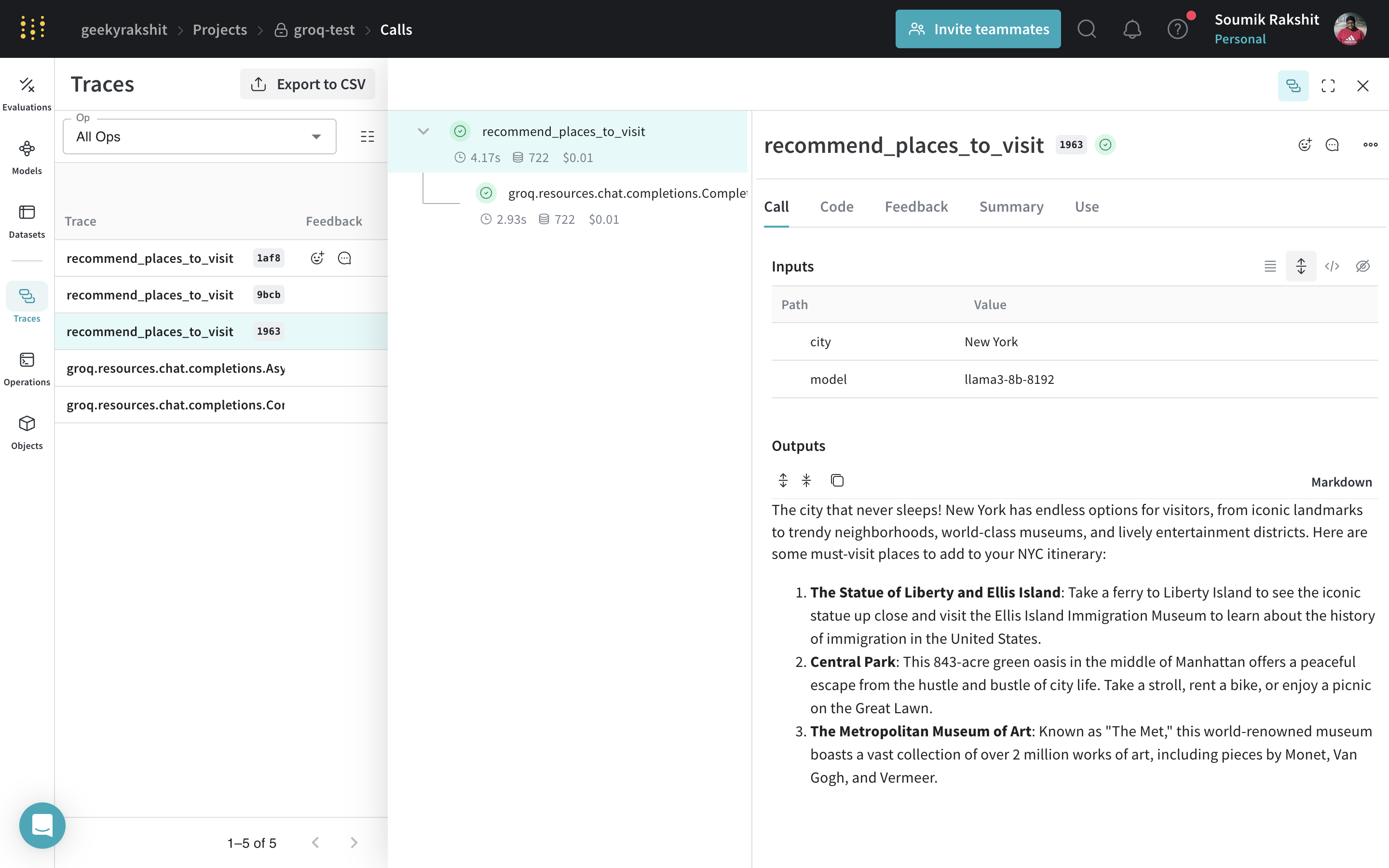
Dans l’exemple suivant, la fonction recommend_places_to_visit, décorée avec @weave.op, recommande des lieux à visiter dans une ville.
 |
|---|
Décorez la fonction recommend_places_to_visit avec @weave.op pour tracer ses entrées, ses sorties et tous les appels LM internes effectués dans la fonction. |
Créez un Model pour faciliter l’expérimentation
Model, vous pouvez capturer et organiser les détails expérimentaux de votre application, comme le prompt système ou le modèle que vous utilisez. Cela facilite l’organisation et la comparaison des différentes itérations de votre application.
En plus de la gestion des versions du code et de la capture des entrées et des sorties, les Models capturent des paramètres structurés qui contrôlent le comportement de votre application, vous aidant à trouver les paramètres les plus efficaces. Vous pouvez également utiliser des Weave Models avec serve et des Evaluations.
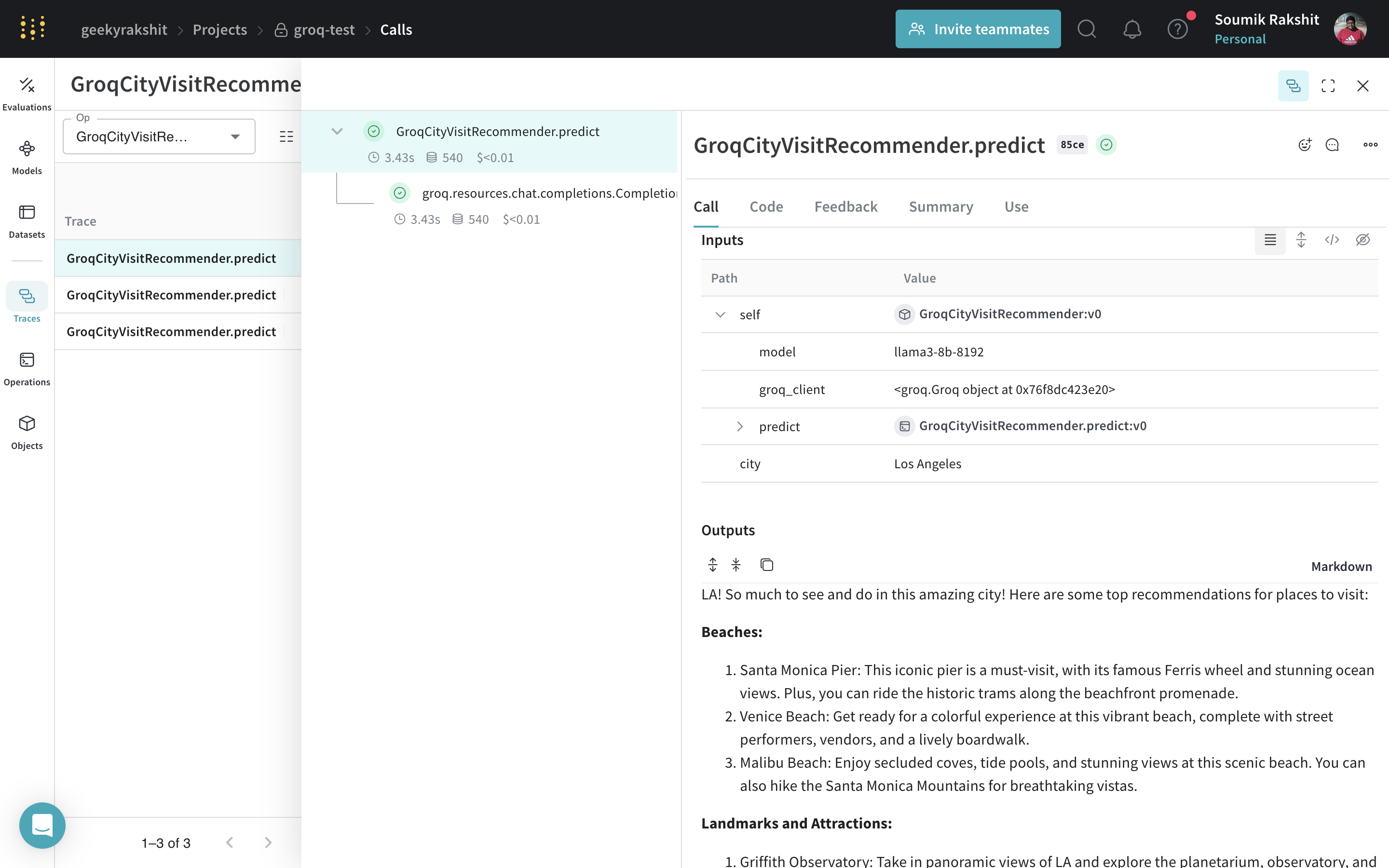
Dans l’exemple suivant, vous pouvez expérimenter avec GroqCityVisitRecommender. À chaque modification de l’un de ces éléments, vous obtenez une nouvelle version de GroqCityVisitRecommender.
 |
|---|
Tracez et gérez les versions de vos appels à l’aide d’un Model. |
Servir un Weave Model
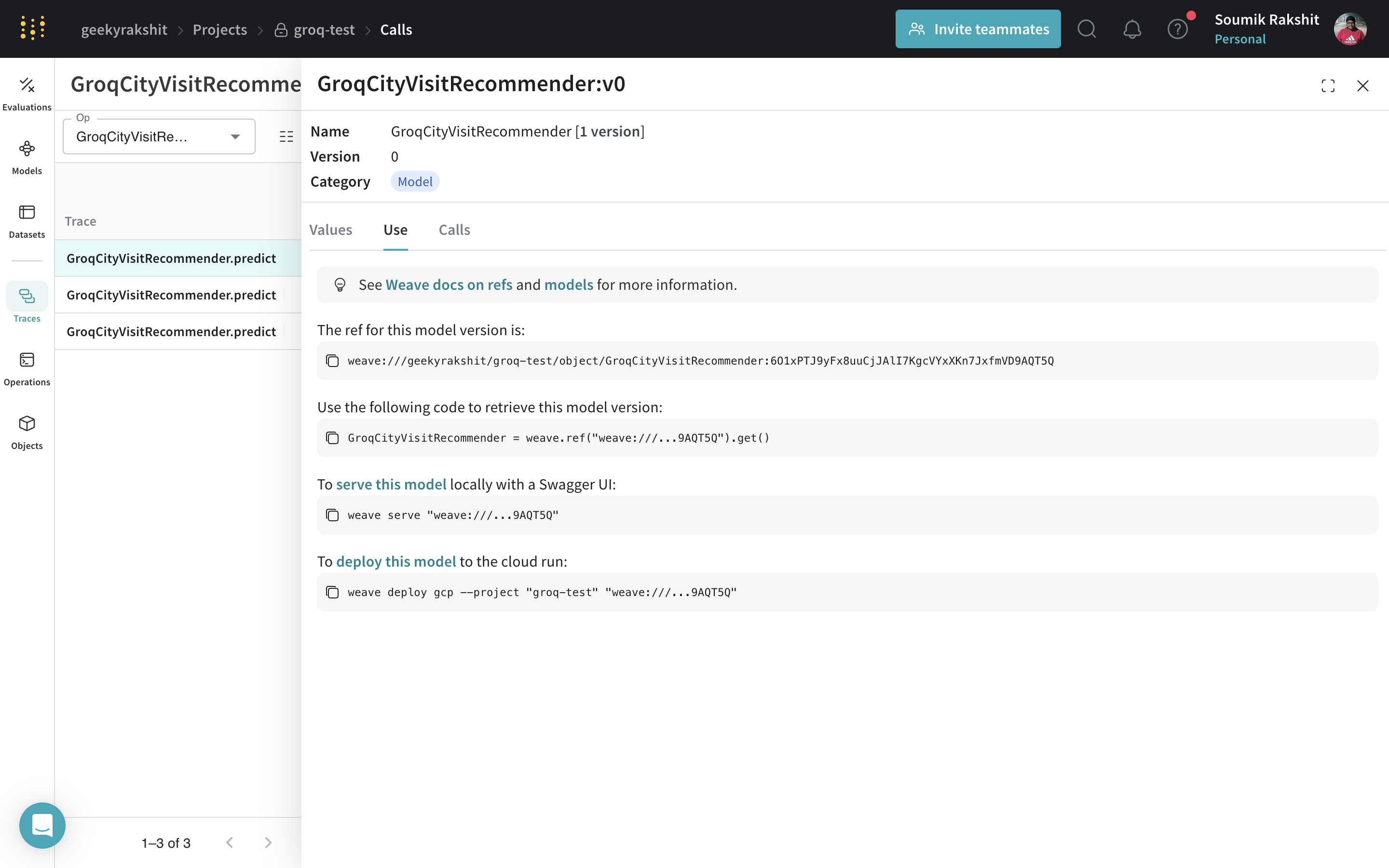
Model versionné, vous pouvez le déployer en tant que service pour des tests ou des applications en aval. À partir d’une référence Weave vers n’importe quel objet weave.Model, vous pouvez lancer un serveur FastAPI et le Serve.
 |
|---|
Vous pouvez trouver la référence Weave de n’importe quel weave.Model en ouvrant le modèle, puis en la copiant depuis l’UI. |