Tous les exemples de code présentés sur cette page sont en Python.
Essayez Hugging Face Hub avec Weave dans Google Colab
Vous souhaitez tester Hugging Face Hub et Weave sans configuration préalable ? Vous pouvez essayer les exemples de code présentés ici sous la forme d’un notebook Jupyter dans Google Colab.
Aperçu
huggingface_hub fournit une interface unifiée pour exécuter l’inférence sur plusieurs services pour les modèles hébergés sur le Hub. Vous pouvez appeler ces modèles à l’aide de InferenceClient.
Weave capture automatiquement les traces pour InferenceClient. Pour commencer le suivi, appelez weave.init() et utilisez la bibliothèque normalement.
Prérequis
-
Avant de pouvoir utiliser
huggingface_hubavec Weave, vous devez installer les bibliothèques nécessaires ou les mettre à jour vers leur dernière version. La commande suivante installe ou met à jourhuggingface_hubetweavevers la dernière version, s’ils sont déjà installés, tout en réduisant la sortie d’installation. -
Pour utiliser l’inférence avec un modèle sur le Hugging Face Hub, configurez votre User Access Token. Vous pouvez définir ce token depuis votre page Settings de Hugging Face Hub ou par programmation. L’exemple de code suivant vous invite à saisir votre
HUGGINGFACE_TOKENet définit ce token comme variable d’environnement.
Traçage de base
InferenceClient. Pour commencer le suivi, initialisez Weave en appelant weave.init(), puis utilisez la bibliothèque comme d’habitude.
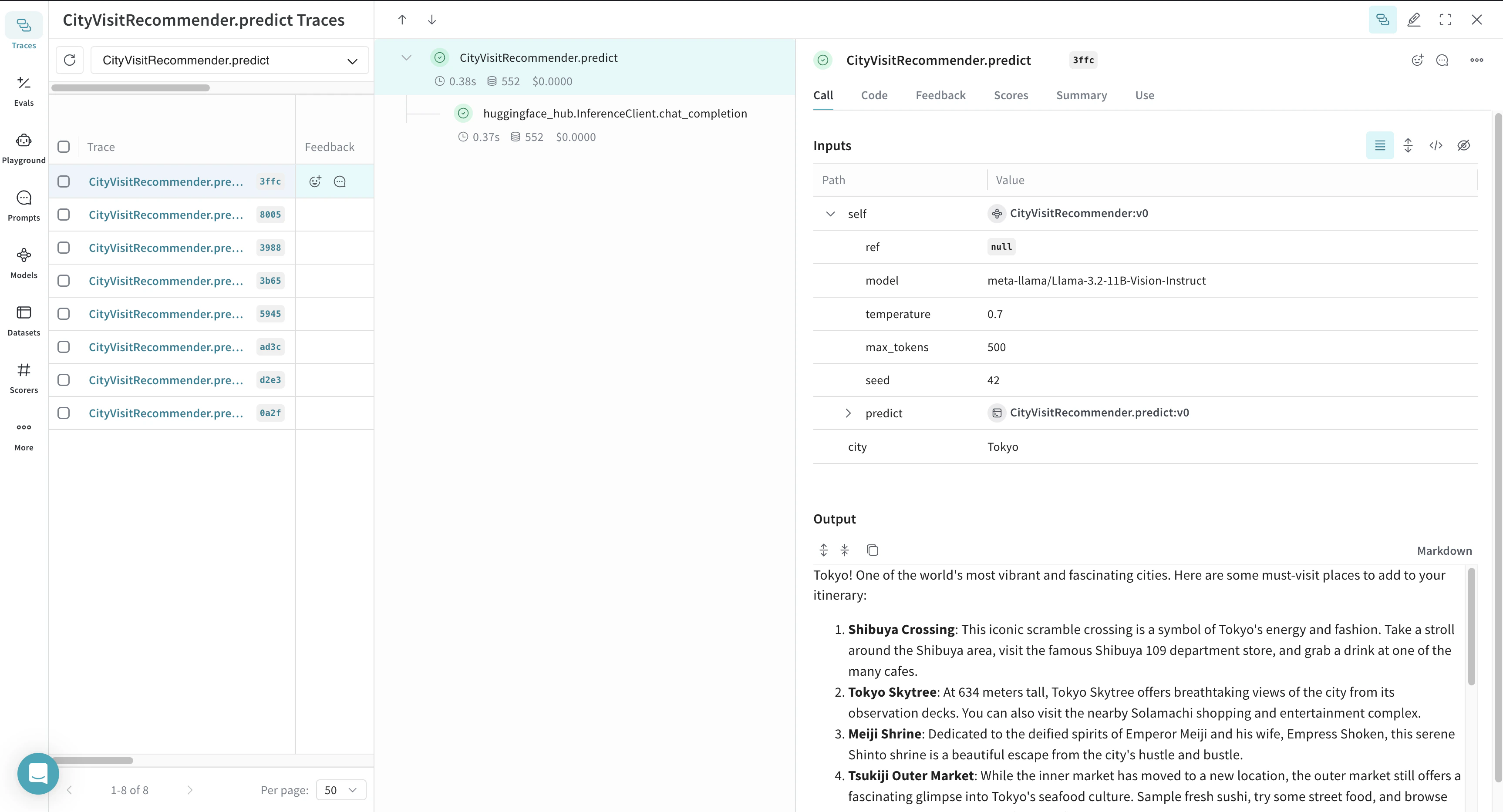
L’exemple suivant montre comment consigner les appels d’inférence vers le Hugging Face Hub à l’aide de Weave :
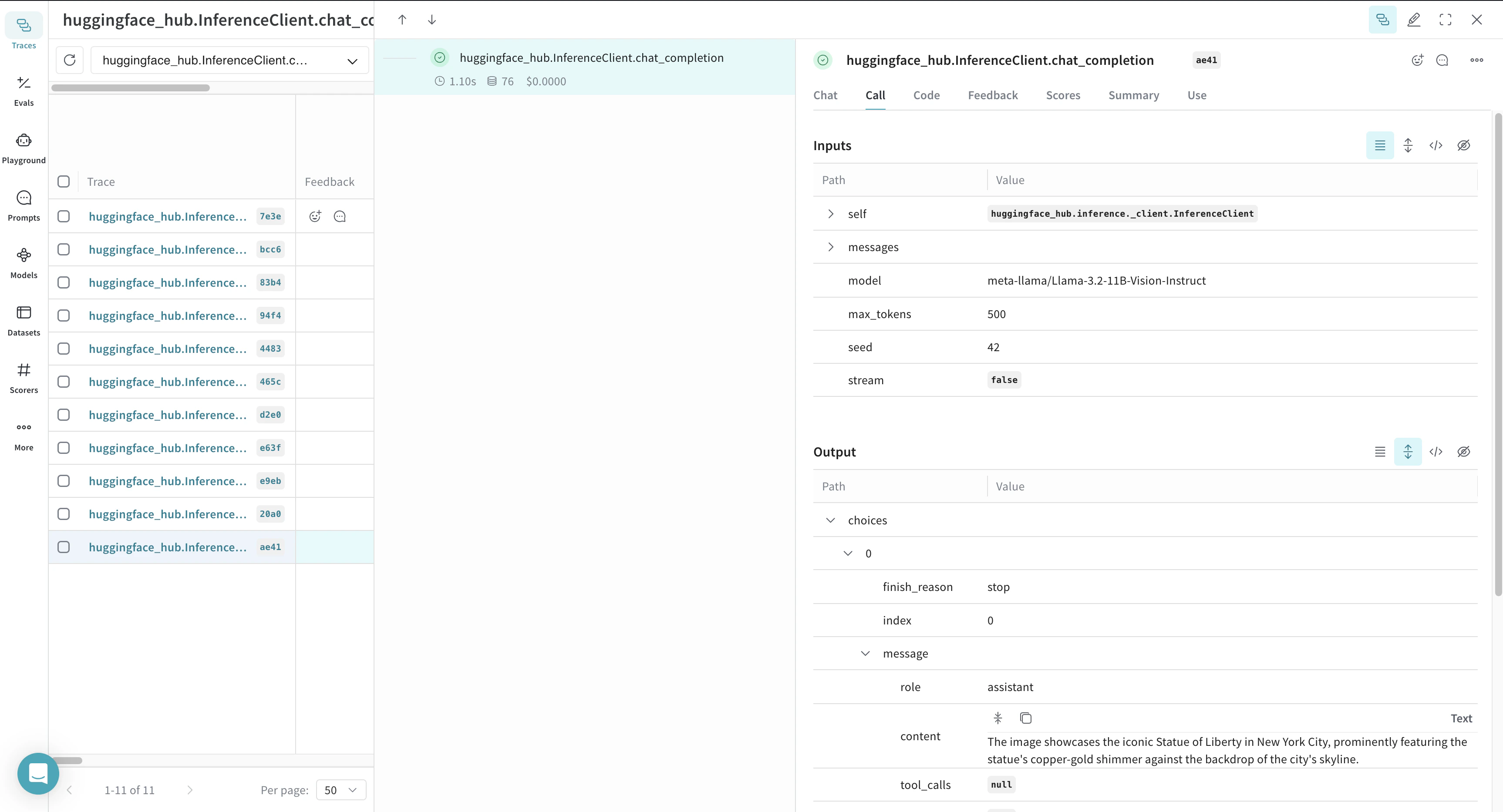
Tracer une fonction
@weave.op pour suivre les appels de fonction. Cela enregistre les entrées, les sorties et la logique d’exécution, ce qui facilite le débogage et l’analyse des performances.
En imbriquant plusieurs ops, vous pouvez créer une arborescence structurée de fonctions suivies. Weave versionne aussi automatiquement votre code, en conservant les états intermédiaires au fil de vos expérimentations, même avant que vous ne validiez vos modifications dans Git.
Pour commencer le suivi, ajoutez le décorateur @weave.op aux fonctions que vous souhaitez suivre.
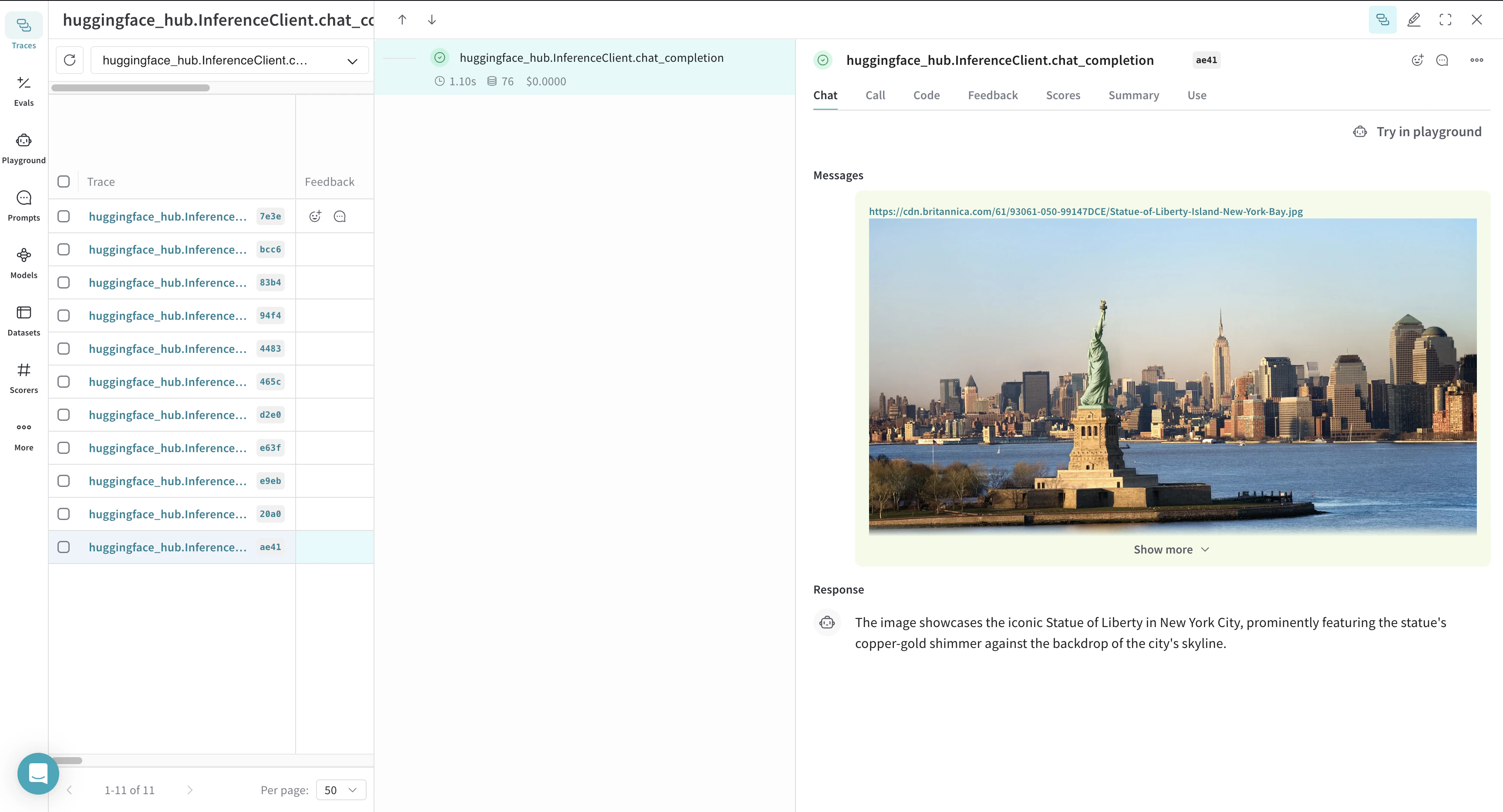
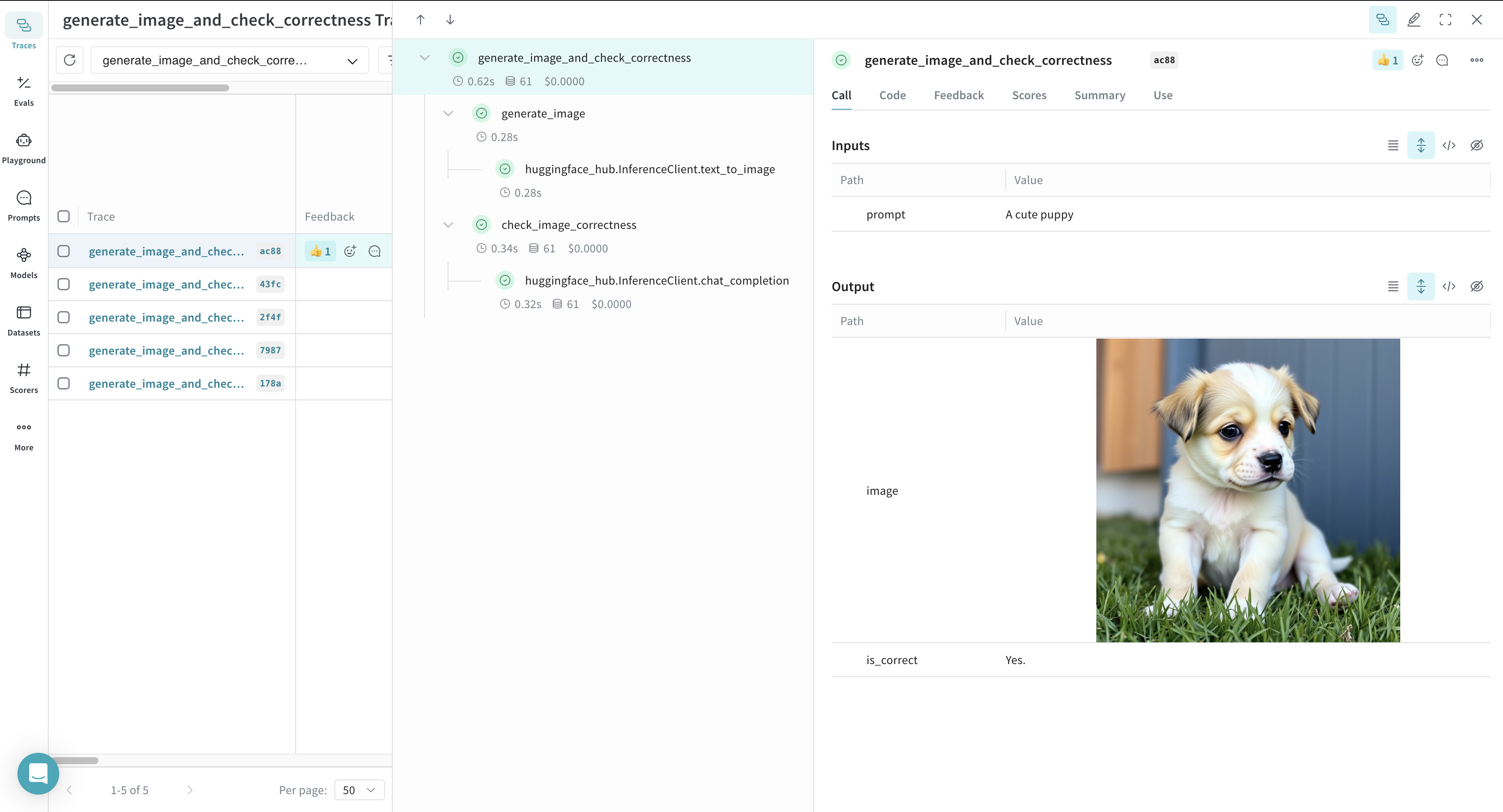
Dans l’exemple suivant, Weave suit trois fonctions : generate_image, check_image_correctness et generate_image_and_check_correctness. Ces fonctions génèrent une image et vérifient si elle correspond à un prompt donné.
@weave.op, ce qui vous permet d’analyser les détails d’exécution dans la Weave UI.
Utilisez des Models pour l’expérimentation
Model permet de capturer et d’organiser les détails expérimentaux, comme les prompts système et les configurations de modèle, vous permettant de comparer différentes itérations.
En plus de la gestion des versions du code et de la capture des entrées et des sorties, un Model stocke des paramètres structurés qui contrôlent le comportement de l’application. Cela vous aide à suivre quelles configurations ont produit les meilleurs résultats. Vous pouvez également intégrer un Model Weave à Weave Serve et aux Évaluations pour obtenir des informations supplémentaires.
L’exemple suivant définit un modèle CityVisitRecommender pour des recommandations de voyage. Chaque modification de ses paramètres génère une nouvelle version, favorisant une expérimentation itérative.