weave.init() appelé. Ce guide montre aux développeurs Python utilisant ChatNVIDIA comment capturer les traces, encapsuler leurs propres fonctions sous forme d’Ops et organiser des expériences avec la classe Model de Weave afin de déboguer, d’itérer et de comparer plus efficacement des applications LLM.
Tracing
- Python
- TypeScript
Weave peut automatiquement capturer les traces de la bibliothèque Python ChatNVIDIA.Commencez à capturer les traces en appelant Après avoir exécuté ce code, Weave capture l’appel ChatNVIDIA sous le nom de projet que vous avez indiqué, où vous pouvez inspecter les entrées, les sorties et les métadonnées.
weave.init([PROJECT-NAME]) avec le nom de projet de votre choix.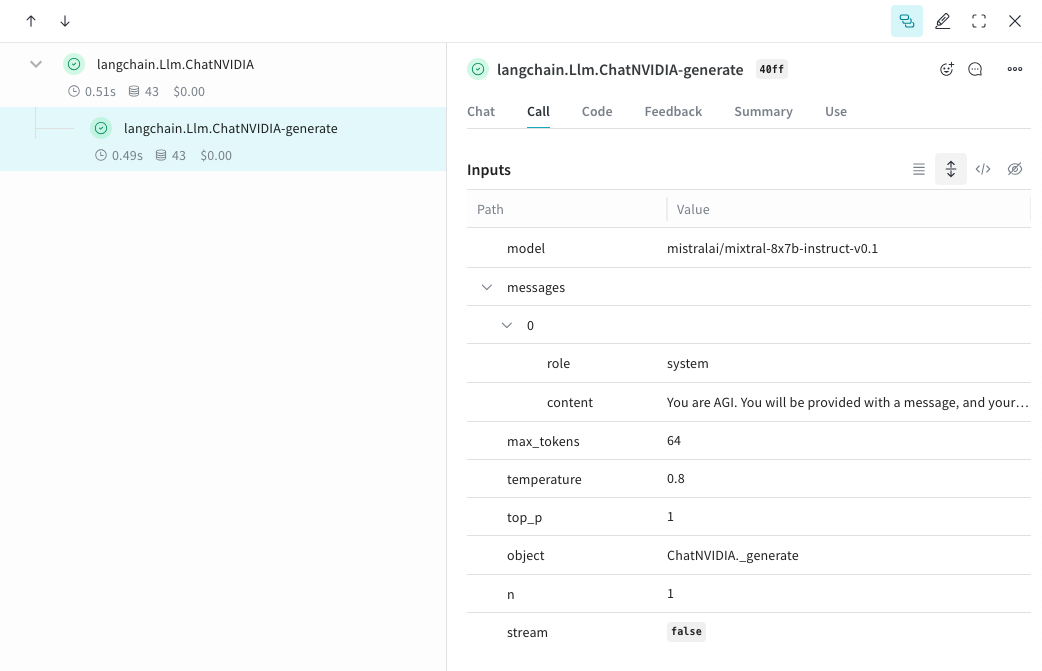
Suivez vos propres ops
- Python
- TypeScript
En encapsulant une fonction avec Accédez à Weave et cliquez sur
@weave.op, vous commencez à capturer les entrées, les sorties et la logique de l’application afin de pouvoir déboguer la façon dont les données circulent dans votre application. Vous pouvez imbriquer des ops en profondeur et créer un arbre de fonctions que vous souhaitez suivre. Cela active également la gestion automatique des versions du code pendant vos expérimentations afin de capturer des détails ad hoc que vous n’avez pas encore validés dans Git.Créez une fonction décorée avec @weave.op qui appelle la bibliothèque Python ChatNVIDIA.Dans l’exemple suivant, deux fonctions sont encapsulées avec op. Cela montre comment des étapes intermédiaires, comme l’étape de récupération dans une application RAG, influencent le comportement de votre application.get_pokemon_data dans l’interface utilisateur pour voir les entrées et les sorties de cette étape.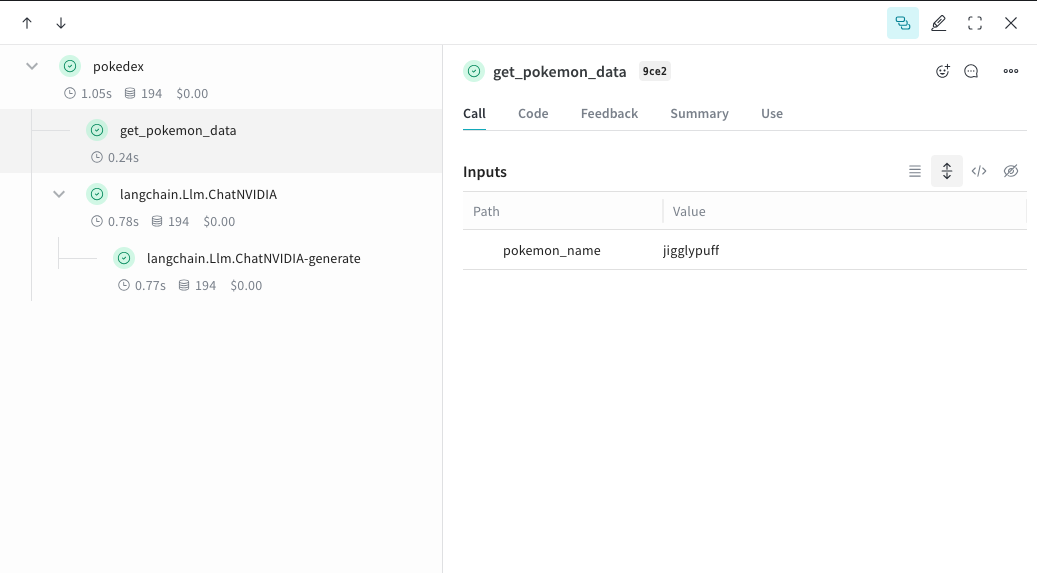
Créer un Model pour expérimenter plus facilement
- Python
- TypeScript
Il est difficile d’organiser une expérimentation lorsqu’il y a de nombreux éléments à prendre en compte. En utilisant la classe
Model, vous pouvez capturer et organiser les détails expérimentaux de votre application, comme le prompt système ou le modèle que vous utilisez. Cela vous aide à structurer et comparer les différentes itérations de votre application.En plus de la gestion des versions du code et de la capture des entrées et des sorties, les Model capturent des paramètres structurés qui contrôlent le comportement de votre application, ce qui permet d’identifier facilement les paramètres les plus efficaces. Vous pouvez également utiliser les Weave Models avec serve et les Evaluation.Dans l’exemple suivant, vous pouvez expérimenter avec model et system_message. Chaque fois que vous en modifiez un, vous obtenez une nouvelle version de GrammarCorrectorModel.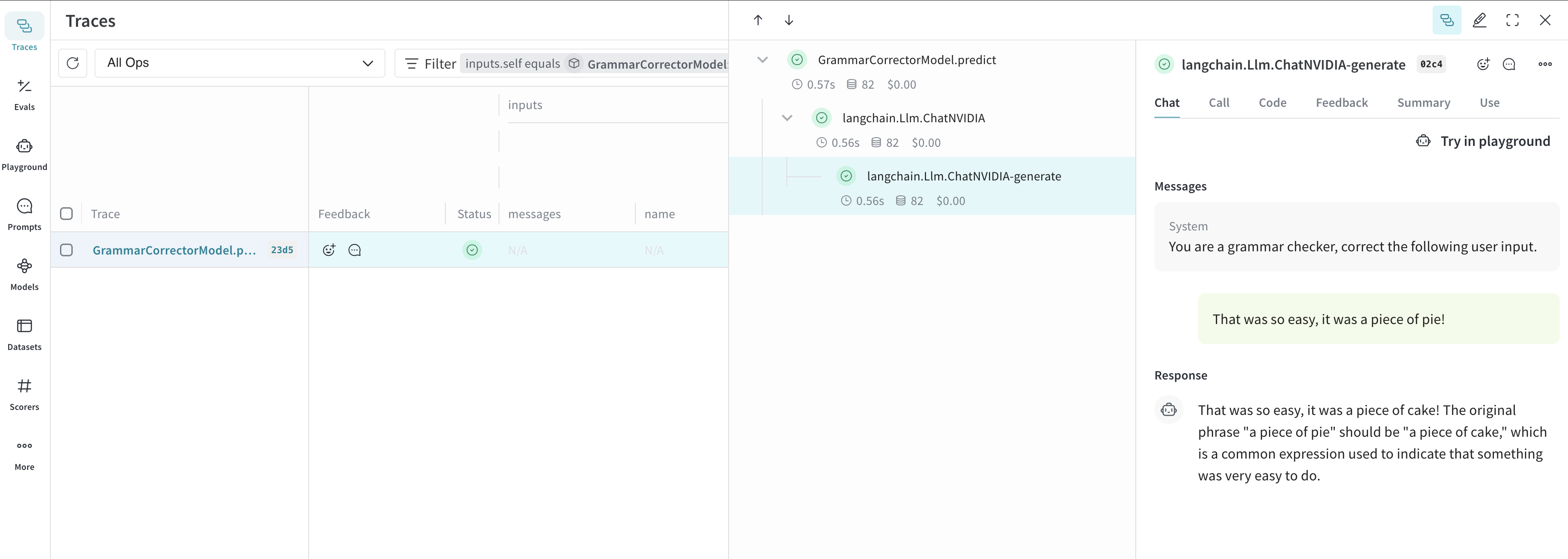
Informations d’utilisation
invoke, stream et leurs variantes asynchrones. Elle prend également en charge l’utilisation d’outils.
Comme ChatNVIDIA est conçu pour être utilisé avec de nombreux types de modèles, il ne prend pas en charge les appels de fonction.