Trainer を W&B に接続する方法を説明します。これにより、トレーニング Runs のメトリクス、モデル チェックポイント、評価出力が一元管理ダッシュボードに自動的にログされます。最後には、Runs を比較し、モデル チェックポイントを W&B Artifacts に保存してそこから再読み込みし、独自のワークフローに合わせてログをカスタマイズできるようになります。このガイドでは、Hugging Face Transformers の Trainer を使用したモデルのトレーニングにすでに慣れていることを前提としています。
クイックスタート
すぐに使えるコードを見たい場合は、こちらのGoogle Colabをご覧ください。
はじめに: Experiments をトラッキングする
Trainer でのログの有効化について説明します。これにより、最初のトレーニング run が W&B Dashboard に表示されるようになります。
サインアップしてAPIキーを発行する
より手早く行うには、User Settings にアクセスしてAPIキーを作成してください。APIキーはすぐにコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上にあるユーザープロフィールアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリをインストールしてログインする
wandb ライブラリをローカルにインストールしてログインするには、以下の手順に従います。
- コマンドライン
- Python
- Python ノートブック
-
WANDB_API_KEY環境変数に APIキー を設定します。<>で囲まれた値は、ご自身の値に置き換えてください。 -
wandbライブラリをインストールし、ログインします。
プロジェクトに名前を付ける
WANDB_PROJECT 環境変数にプロジェクト名を設定します。WandbCallback はこの環境変数からプロジェクト名を取得し、run の設定時に使用します。
- コマンドライン
- Python
- Python ノートブック
Trainer を初期化する_前に_、必ずプロジェクト名を設定してください。huggingface になります。
トレーニング run を W&B にログする
Trainer のトレーニング引数を定義する際は、W&B でログすることを有効にするため、report_to を "wandb" に設定します。この設定がない場合、Trainer は W&B にデータを送信しません。
TrainingArguments の logging_steps 引数では、トレーニング中のメトリクスをどのくらいの頻度で W&B に送信するかを制御します。また、run_name 引数を使って、W&B 上のトレーニング run に名前を付けることもできます。
以上です。これで、モデルはトレーニング中に損失、評価メトリクス、モデルのトポロジー、勾配を W&B にログするようになります。
- コマンドライン
- Python
TensorFlow を使っていますか?PyTorch の
Trainer を TensorFlow の TFTrainer に置き換えるだけです。モデル チェックポイントを有効にする
WANDB_LOG_MODEL 環境変数を次のいずれか 1 つ に設定します。
checkpoint:TrainingArgumentsのargs.save_stepsごとにチェックポイントをアップロードします。end:load_best_model_at_endも設定されている場合、トレーニング終了時にモデルをアップロードします。false: モデルをアップロードしません。
- コマンドライン
- Python
- Python ノートブック
Trainer は、モデルを W&B のプロジェクトにアップロードします。ログしたモデル チェックポイントは Artifacts の UI で確認でき、完全なモデル リネージが含まれます。Artifacts UI でのモデル チェックポイントの例を参照してください。
デフォルトでは、
WANDB_LOG_MODEL が end に設定されている場合、モデルは W&B Artifacts に model-{run_id} として保存され、WANDB_LOG_MODEL が checkpoint に設定されている場合は checkpoint-{run_id} として保存されます。
ただし、TrainingArguments に run_name を渡すと、モデルは model-{run_name} または checkpoint-{run_name} として保存されます。W&B Registry
トレーニング中に評価出力を可視化する
W&B run を終了する (notebook のみ)
run.finish() を呼び出して、トレーニングが完了したことを W&B に伝えます。
結果を可視化する
Trainer はメトリクスを名前付きの project にログし、必要に応じてチェックポイントを Artifacts に保存し、評価の出力を W&B Dashboard で確認できるようにします。
高度な機能と FAQ
最良のモデルを保存する
Trainer に load_best_model_at_end=True を含む TrainingArguments を渡すと、W&B は最も性能の高いモデル チェックポイントを Artifacts に保存します。
モデル チェックポイントを Artifacts として保存した場合は、Registry に昇格できます。Registry では、次のことができます。
- ML タスクごとに最良のモデル バージョンを整理する。
- モデルを一元管理し、チームと共有する。
- モデルを本番向けにステージングしたり、追加の評価のためにブックマークしたりする。
- 後続の CI/CD プロセスをトリガーする。
保存したモデルを読み込む
WANDB_LOG_MODEL を使ってモデルを W&B Artifacts に保存している場合は、追加のトレーニングや推論のためにモデルの重みをダウンロードできます。あとは、それを以前使っていたのと同じ Hugging Face のアーキテクチャに読み込んでください。
チェックポイントからトレーニングを再開する
WANDB_LOG_MODEL='checkpoint' を設定した場合は、TrainingArguments で model_dir を model_name_or_path 引数として使用し、Trainer に resume_from_checkpoint=True を渡すことで、トレーニングを再開できます。
トレーニング中に評価サンプルをログして表示する
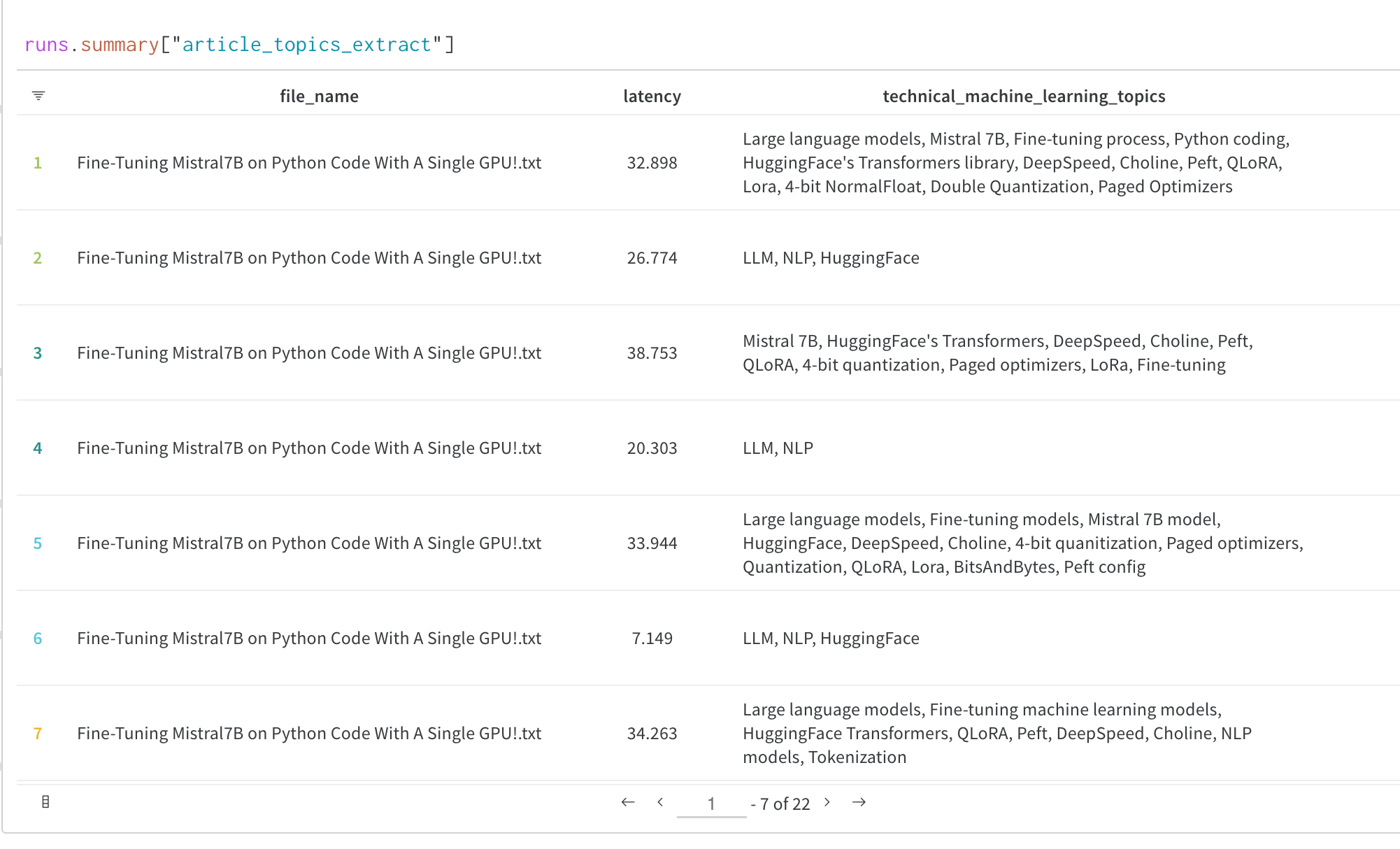
Trainer 経由で W&B にログする処理は、Transformers ライブラリの WandbCallback が担います。モデルの予測、混同行列、その他のカスタムデータをログするには、このコールバックをカスタマイズできます。そのためには、WandbCallback をサブクラス化し、Trainer クラスの追加のメソッドを使用する機能を加えます。
以下に、この新しいコールバックを Hugging Face Trainer に追加する一般的なパターンを示します。続いて、評価出力を W&B の表にログする完全なコード例を掲載します。
トレーニング中に評価サンプルを確認する
WandbCallback をカスタマイズして、トレーニング中にモデルの予測を実行し、評価サンプルを W&B 表 にログする方法を示します。これは、Trainer の コールバック の on_evaluate メソッドを使って、eval_steps ごとに実行されます。
decode_predictions function は、トークナイザーを使用してモデル出力から予測とラベルをデコードします。
次に、コードは予測とラベルから pandas DataFrame を作成し、DataFrame に epoch 列を追加します。
最後に、コードは DataFrame から wandb.Table を作成し、それを W&B にログします。freq エポックごとに予測をログすることで、ログする頻度を制御できます。
通常の
WandbCallback とは異なり、このカスタム コールバック は、Trainer の初期化時ではなく、Trainer をインスタンス化した後に trainer に追加する必要があります。これは、初期化時に Trainer インスタンスが コールバック に渡されるためです。追加の W&B 設定
Trainer でログする内容をさらに細かく設定できます。W&B の環境変数の完全な一覧については、環境変数リファレンスを参照してください。
- コマンドライン
- ノートブック
wandb.init() をカスタマイズする
Trainer が使用する WandbCallback は、Trainer の初期化時に内部で wandb.init() を呼び出します。代わりに、Trainer が初期化される前に wandb.init() を呼び出して、run を手動で設定することもできます。これにより、W&B の run 設定を完全に制御できます。
以下に、init に渡す内容の例を示します。wandb.init() の詳細については、wandb.init() referenceを参照してください。