データセットのCSVファイルをインポートしてログする
- まず、CSV ファイルをインポートします。次のコード スニペットでは、
iris.csvをご利用の CSV ファイル名に置き換えてください。
- CSV ファイルを W&B Table に変換して、W&B ダッシュボードで活用します。
- 次に、W&B Artifact を作成し、そこに表を追加します。
- 最後に、
wandb.init()を使用して W&B でトラッキングとログ記録を行うため、新しい W&B Run を開始します:
wandb.init() API は、Run にデータをログするための新しいバックグラウンドプロセスを起動し、 (デフォルトでは) データを wandb.ai と同期します。ライブの可視化は W&B Workspace ダッシュボードで確認できます。次の画像は、コードスニペットの実行結果を示しています。
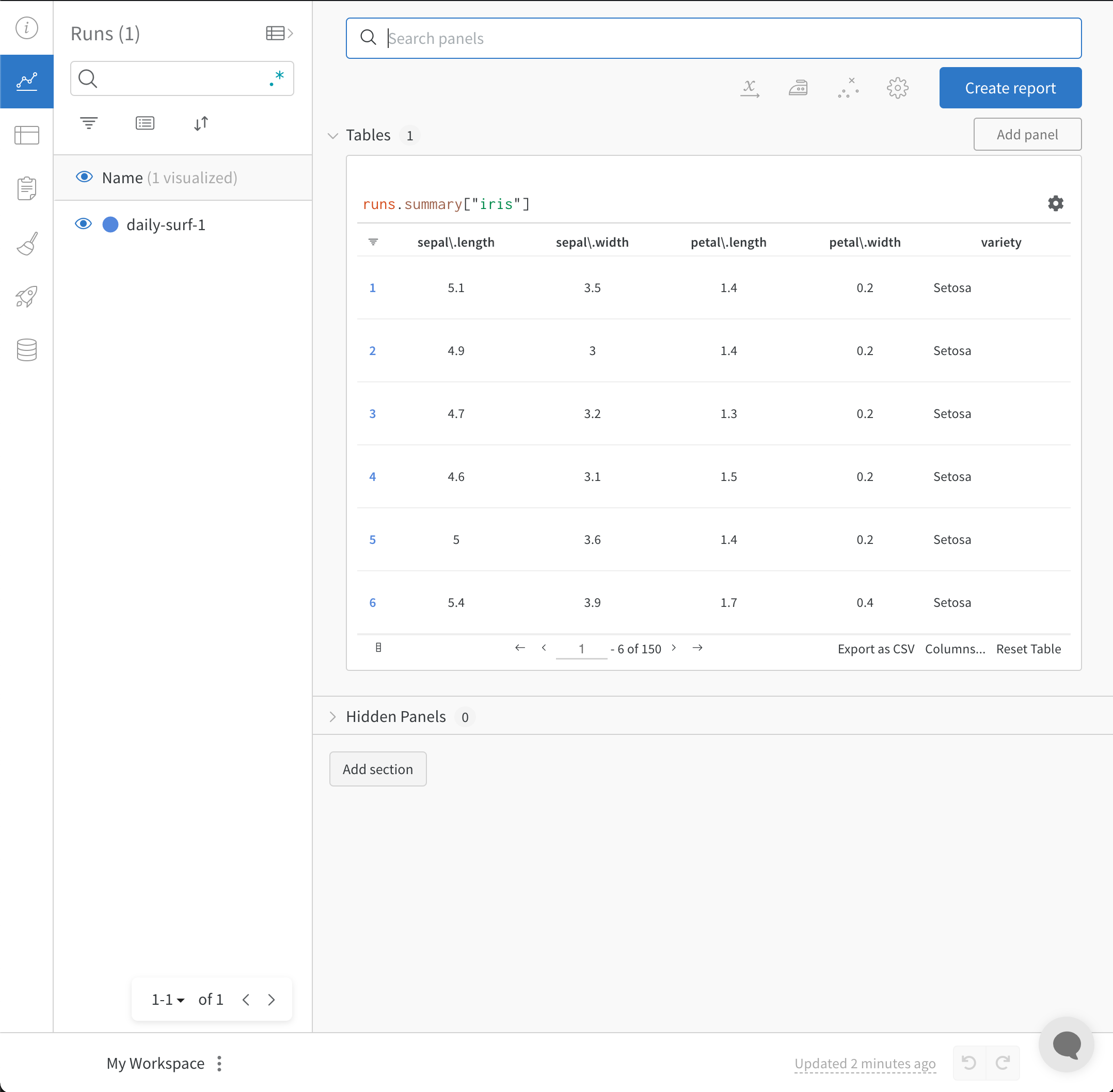
Experiments の CSV をインポートしてログする
- Experiment run の名
- 初期メモ
- Experiment を区別するためのTags
- Experiment に必要な設定 (Sweeps Hyperparameter Tuning を活用できるという利点もあります) 。
W&B では、Experiment の CSV ファイルを W&B Experiment Run に変換できます。次の code snippet とコードスクリプトでは、Experiment の CSV ファイルをインポートしてログする方法を示します。
- まず、CSV ファイルを読み込み、Pandas DataFrame に変換します。
"experiments.csv"は実際の CSV ファイル名に置き換えてください。
-
次に、新しい W&B Run を開始し、
wandb.init()を使用して W&B へのトラッキングとログを開始します。
run.log() コマンドを使用します。
define_metric API を使用すると、必要に応じて最終的な summary メトリクスをログし、run の結果を定義できます。この例では、run.summary.update() を使用して summary メトリクスを run に追加します。