これはインタラクティブ ノートブックです。ローカルで実行することも、以下のリンクを使用することもできます。
Chain of Density要約とは
- 最初の要約から始めます
- 重要な情報を維持したまま、要約を反復的に洗練して、より簡潔にします
- 反復のたびに、Entities と技術的な詳細の密度を高めます
Weave を使用する理由
- LLM パイプラインのトラッキング: Weave を使用して、要約プロセスの入力、出力、および中間ステップを自動的にログします。
- LLM 出力の評価: Weave の組み込みツールを使用して、要約の一貫した評価を作成します。
- コンポーザブルなオペレーションの構築: Weave のオペレーションを要約パイプラインのさまざまな部分で組み合わせて再利用します。
- 既存コードへの統合: 最小限のオーバーヘッドで既存の Python コードに Weave を追加します。
環境を設定する
AnthropicのAPIキーを取得するには、次の手順に従います。
- https://www.anthropic.com でアカウントを作成します。
- アカウント設定のAPIセクションにアクセスします。
- 新しいAPIキーを生成します。
- APIキーを
.envファイルに安全に保存します。
weave.init([PROJECT_NAME])を呼び出すと、要約タスク用の新しいWeave projectが設定されます。
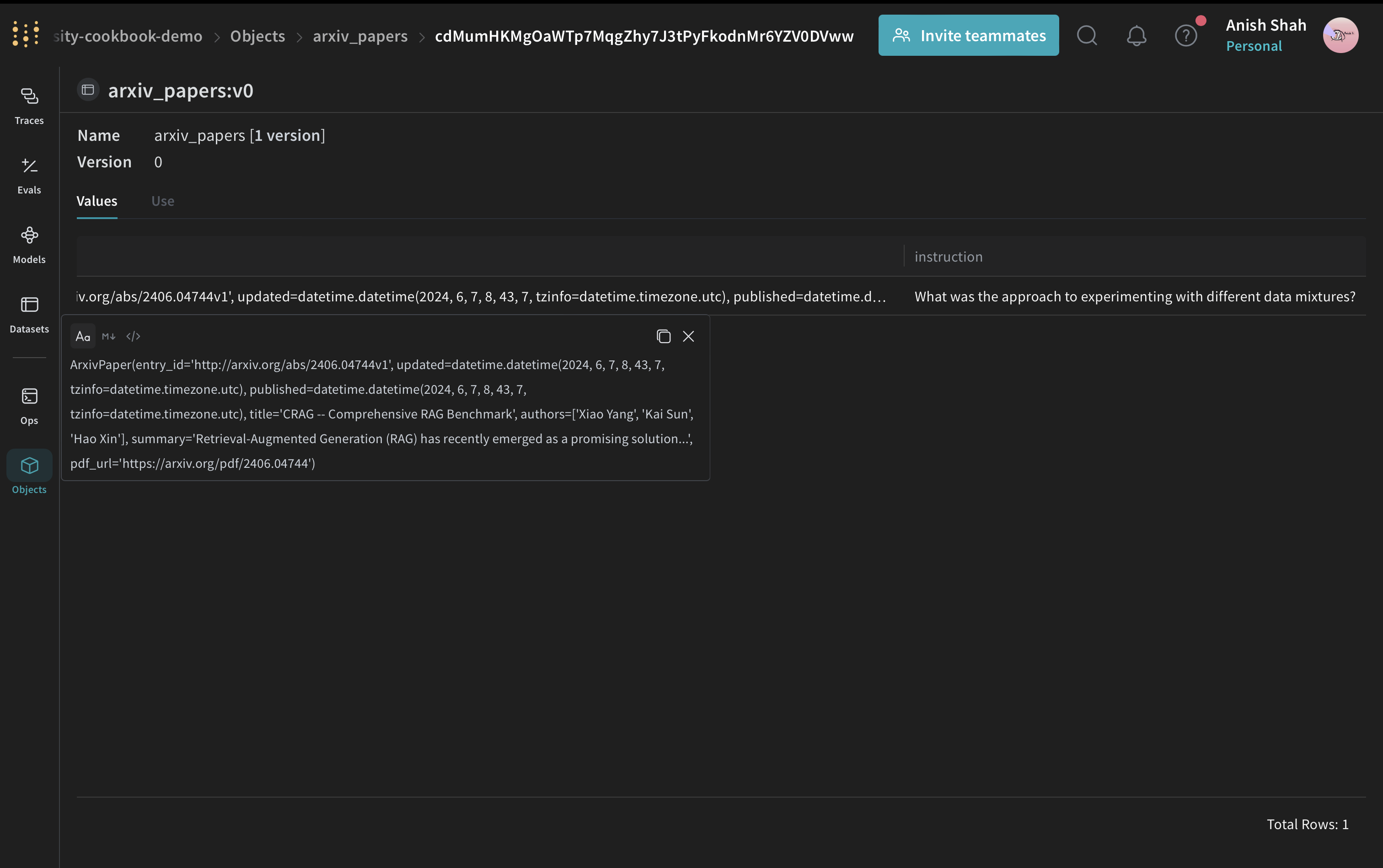
ArxivPaper モデルを定義する
ArxivPaper クラスを作成します。
PDF コンテンツを読み込む
ArxivPaper モデルにはメタデータと PDF の URL が含まれていますが、要約パイプラインでは論文の全文が必要です。論文の全文を扱うには、PDF からテキストを読み込んで抽出する関数を追加します。
Chain of Density要約を実装する
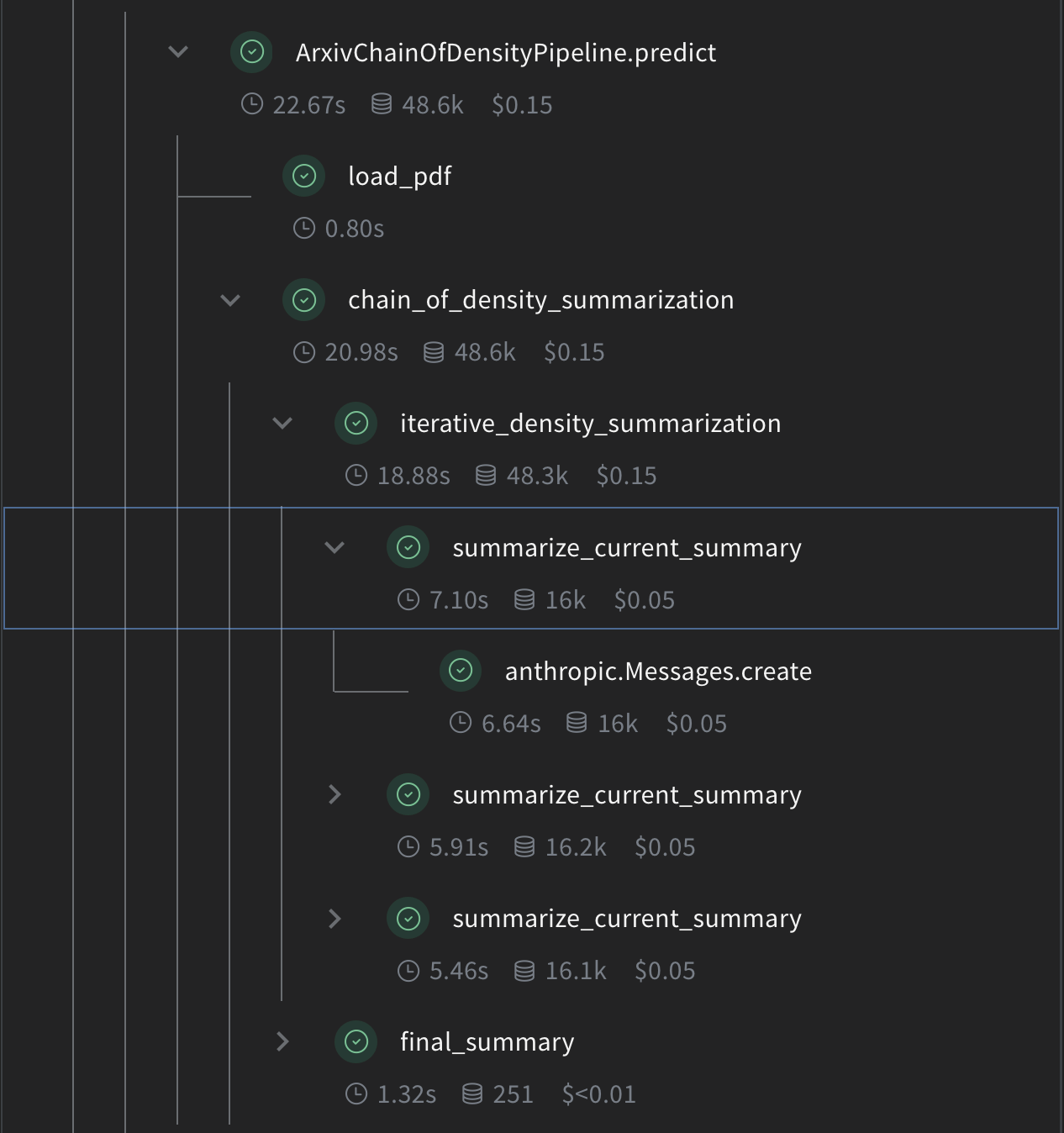
summarize_current_summary: 現在の状態に基づいて、要約の1回分の反復を生成します。iterative_density_summarization:summarize_current_summaryを複数回呼び出して CoD 手法を適用します。chain_of_density_summarization: 要約プロセス全体を統括し、結果を返します。
@weave.op() デコレータにより、Weave はこれらの関数の入力、出力、および実行をトラッキングします。
Weave Model を作成する
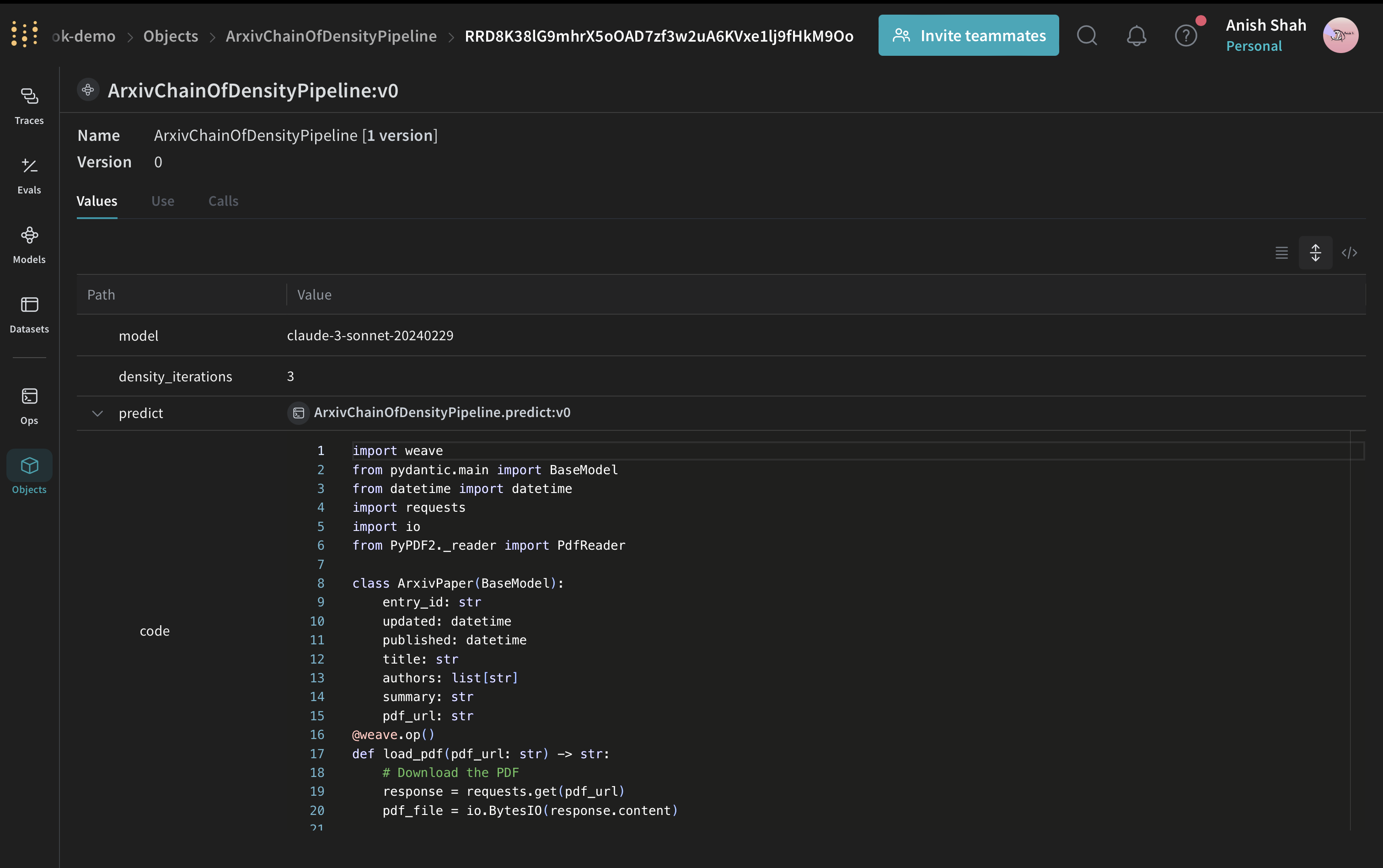
ArxivChainOfDensityPipeline クラスは、要約ロジックを Weave Model としてカプセル化しており、次のような主な利点があります。
- 自動的な実験管理: Weave は、モデルの各 run について 入力、出力、parameters を取得します。
- バージョン管理: モデルの属性やコードへの変更は自動的にバージョン管理されるため、要約パイプラインが時間とともにどのように変化したかを明確に追跡できます。
- 再現性: バージョン管理とトラッキングにより、要約パイプラインの過去の結果や設定を再現できます。
- ハイパーパラメーター管理: モデルの属性 (
modelやdensity_iterationsなど) は明確に定義され、異なる Runs 間でトラッキングされるため、実験を進めやすくなります。 - Weave エコシステムとのインテグレーション:
weave.Modelを使用すると、評価やサービング機能など、他の Weave ツールと連携できます。
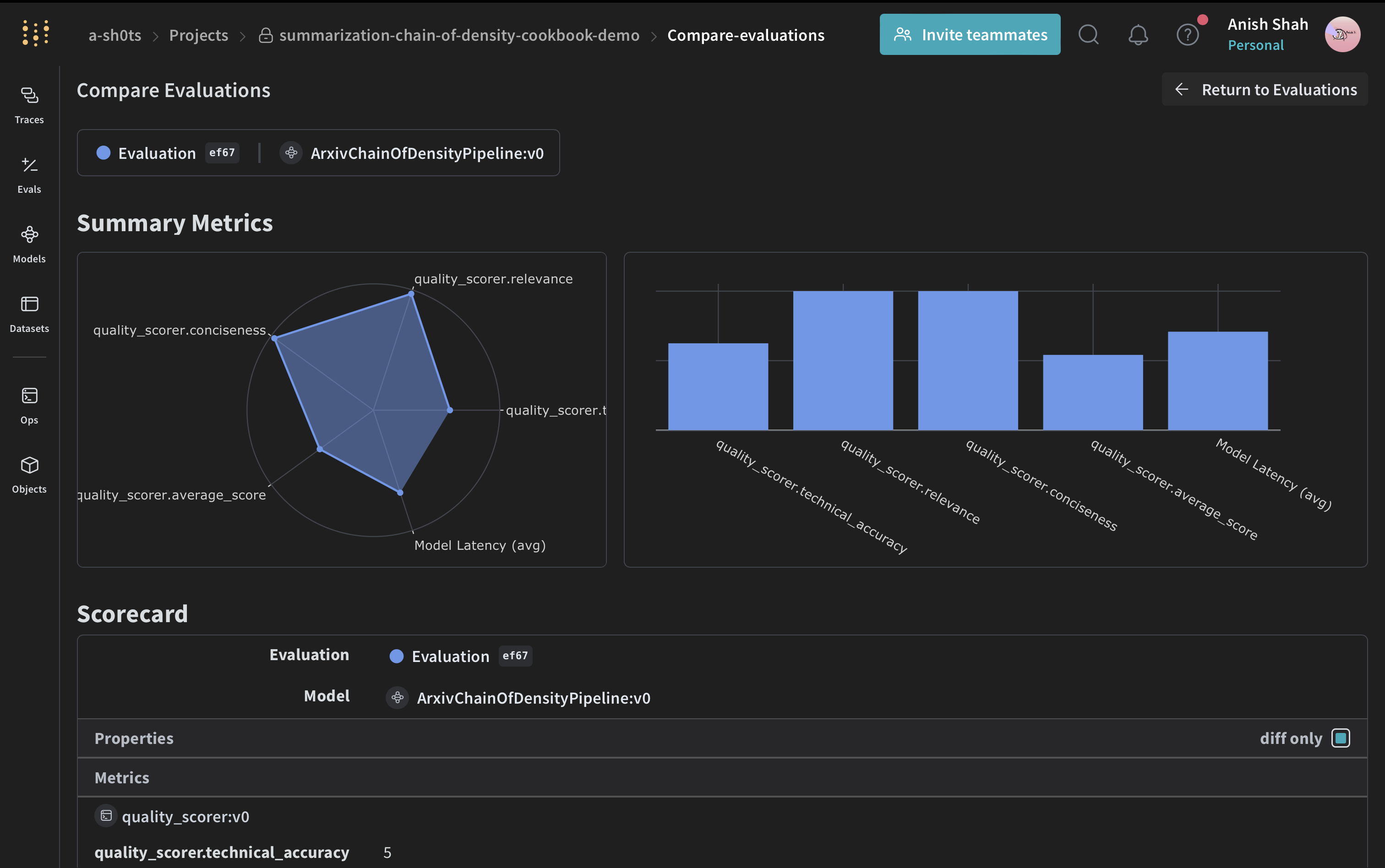
評価メトリクスを実装する
Weave データセットを作成して評価を実行する
結論
- 要約プロセスの各ステップに対応する Weave オペレーションを作成する
- トラッキングと評価のために、パイプラインを Weave Model でラップする
- Weave オペレーションを使用してカスタム評価メトリクスを実装する
- データセットを作成し、パイプラインの評価を実施する