これはインタラクティブなノートブックです。ローカルで実行するか、次のリンクを使用できます:
プロンプトのルーティング
カスタムルーティング
- LLM プロンプトのセット: プロンプトは strings である必要があり、アプリケーションで使用するプロンプトを適切に反映している必要があります。
- LLM の応答: 各入力に対する候補 LLM からの応答です。候補 LLM には、サポートされる LLM と独自のカスタムモデルの両方を含めることができます。
- 候補 LLM から各入力への応答に対する評価スコア: スコアは数値であり、ニーズに合った任意のメトリクスを使用できます。
トレーニングデータを設定する
EvaluationResults にパースします。このトレーニングデータとテストデータの分割は、後続のセクションでルーターのトレーニングと未知データに対するパフォーマンスの評価に使用します。
カスタムルーターをトレーニングする
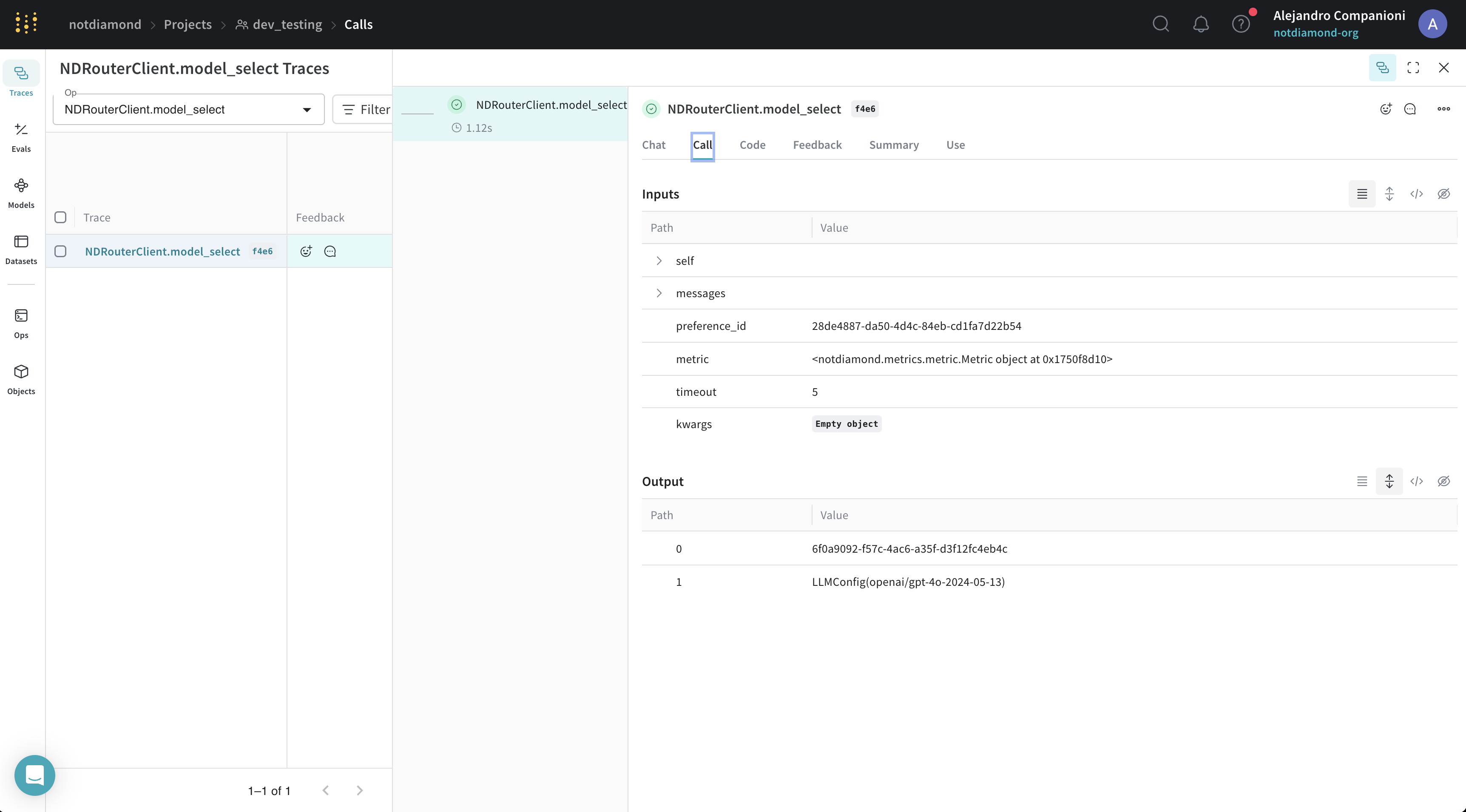
EvaluationResults の準備ができたら、それらを Not Diamond に送信してカスタムルーターをトレーニングできます。まず、アカウントを作成 し、
APIキーを生成してから、次のコードに APIキーを入力してください。APIキーはトレーニングリクエストの認証に使用されます。
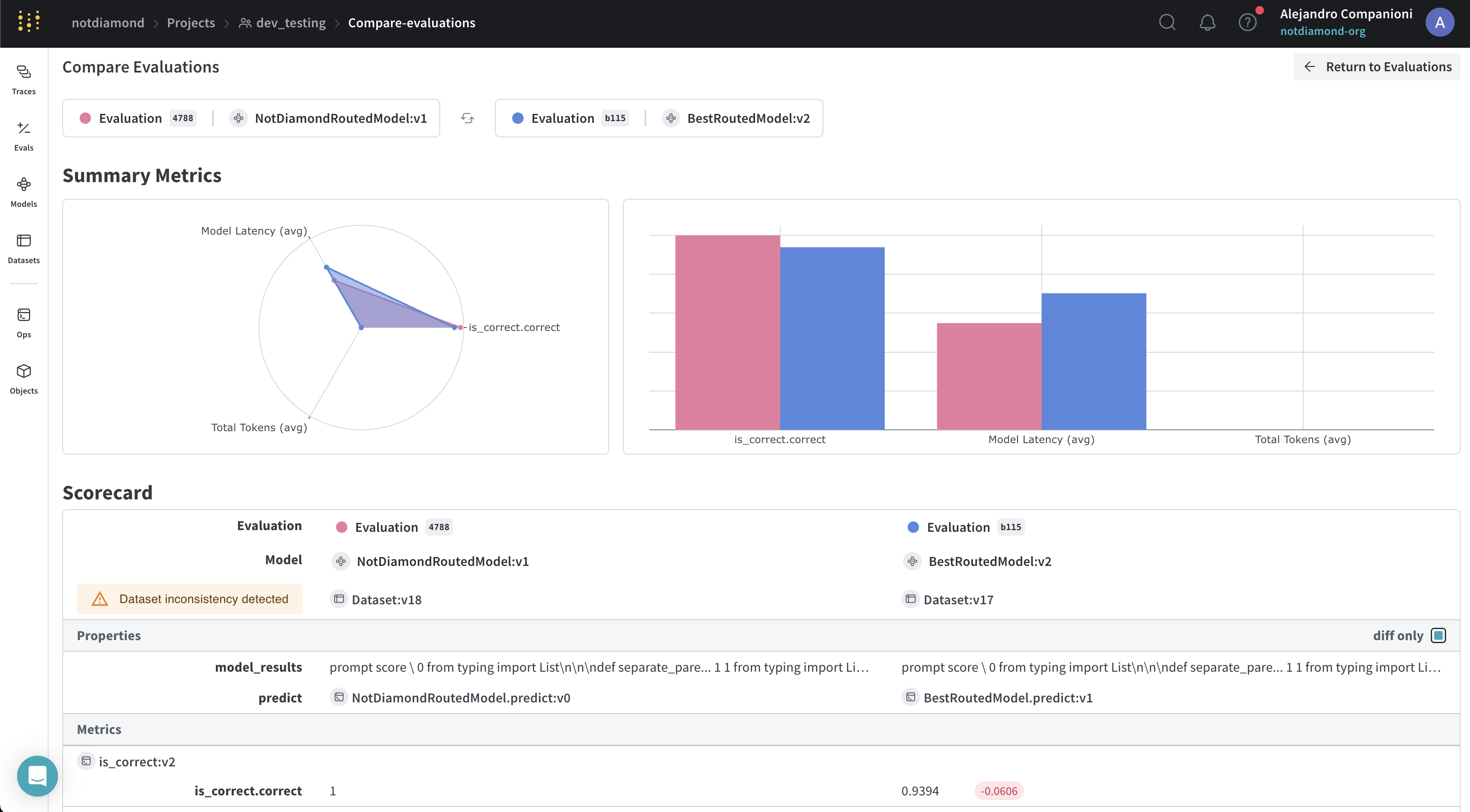
カスタムルーターを評価する
- トレーニング用のプロンプトを送信して、インサンプルのパフォーマンスを評価します。
- 新しいプロンプトまたはホールドアウトしたプロンプトを送信して、アウトオブサンプルのパフォーマンスを評価します。