これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクをご利用ください。
- DSPy:LLMワークフローの構築と最適化に使用します。
- Weave:LLMワークフローをトラッキングし、プロンプト戦略を評価するために使用します。
- datasets:HuggingFace Hub から BIG-Bench Hard データセットにアクセスするために使用します。
このチュートリアルでは、LLMベンダーとして OpenAI API を使用するため、OpenAI APIキーも必要です。ご自身のAPIキーを取得するには、OpenAIプラットフォームで サインアップ してください。
このセクションでは Weave を設定し、このチュートリアルで以降に行う DSPy の Call が自動的にトレースされ、Weave UI で確認できるようにします。
Weave は DSPy と統合されています。コードの先頭で weave.init を呼び出すと、DSPy の関数が自動的にトレースされ、その内容を Weave UI で確認できます。詳しくは、DSPy 向け Weave インテグレーションのドキュメント を参照してください。
このチュートリアルでは、メタデータの管理に、weave.Object を継承したメタデータクラスを使用します。
オブジェクトのバージョン管理: Metadata オブジェクトは、それらを利用する関数がトレースされると、自動的にバージョン管理され、あわせてトレースされます。
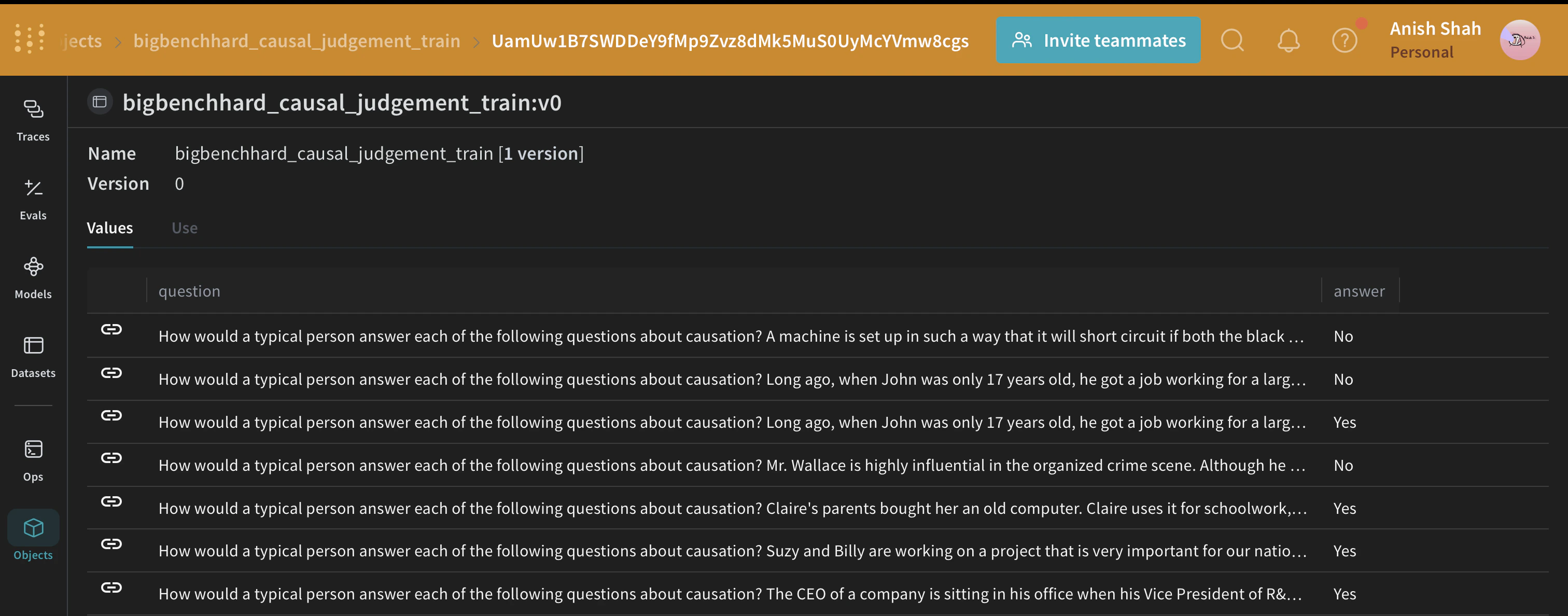
BIG-Bench Hardデータセットを読み込む
weave.Evaluationを使用してプロンプト戦略を評価することもできます。
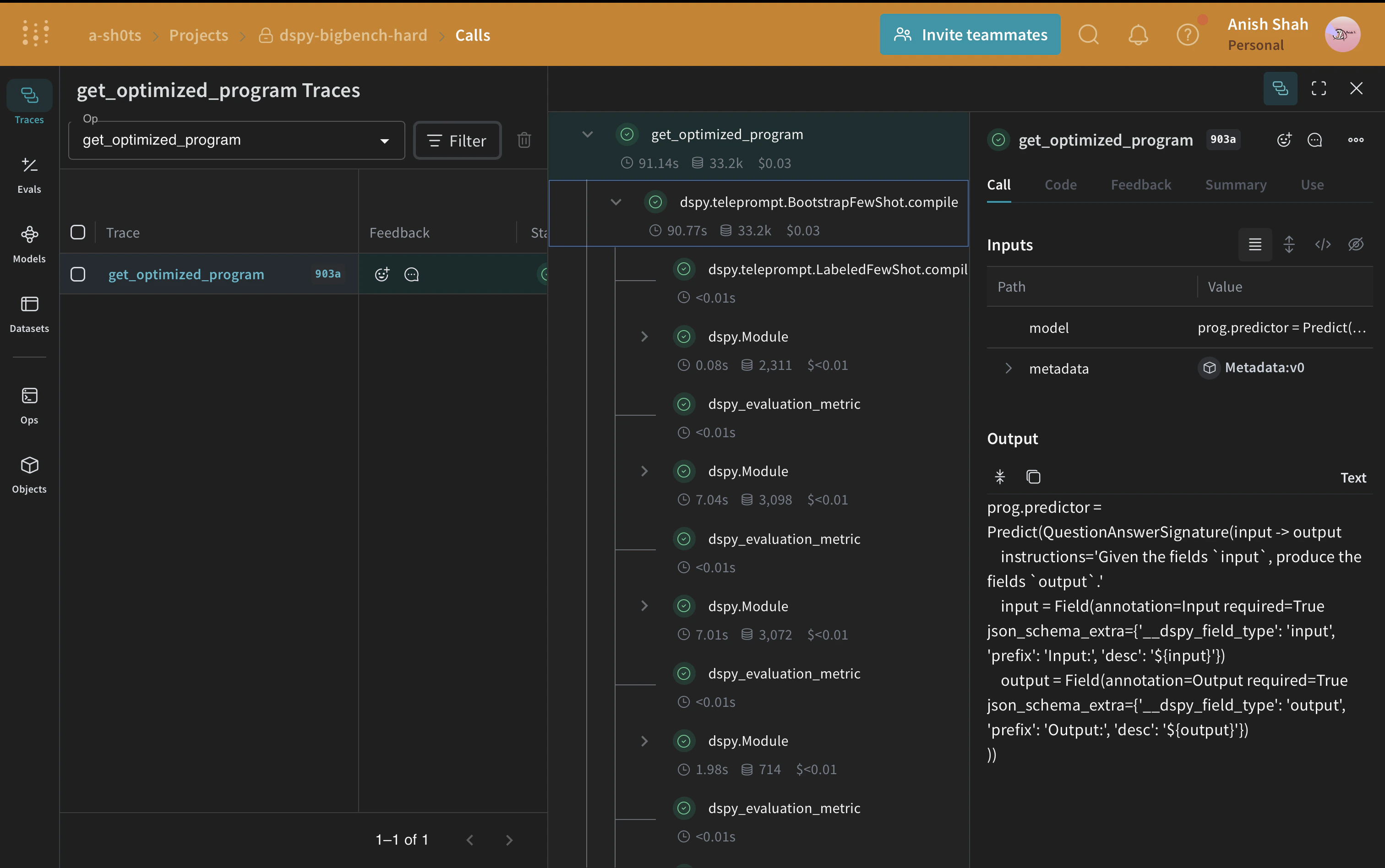
データセットを Weave に公開したので、次に、後で評価および最適化するベースラインの DSPy プログラムを定義できます。
DSPy は、新しい LM パイプラインの構築を、自由記述の文字列を操作するやり方から、プログラミング (モジュール化されたオペレーターを組み合わせてテキスト変換グラフを構成すること) へと近づけるフレームワークです。これにより、コンパイラがプログラムから最適化された LM 呼び出し戦略とプロンプトを自動生成します。
言語モデルの設定には dspy.LM を使用し、それをデフォルトに設定するには dspy.configure を使用します。
signature とは、DSPy module の入出力の動作を宣言的に定義するものです。DSPy modules は、ニューラルネットワークの層に似たタスク適応型のコンポーネントで、特定のテキスト変換を抽象化します。
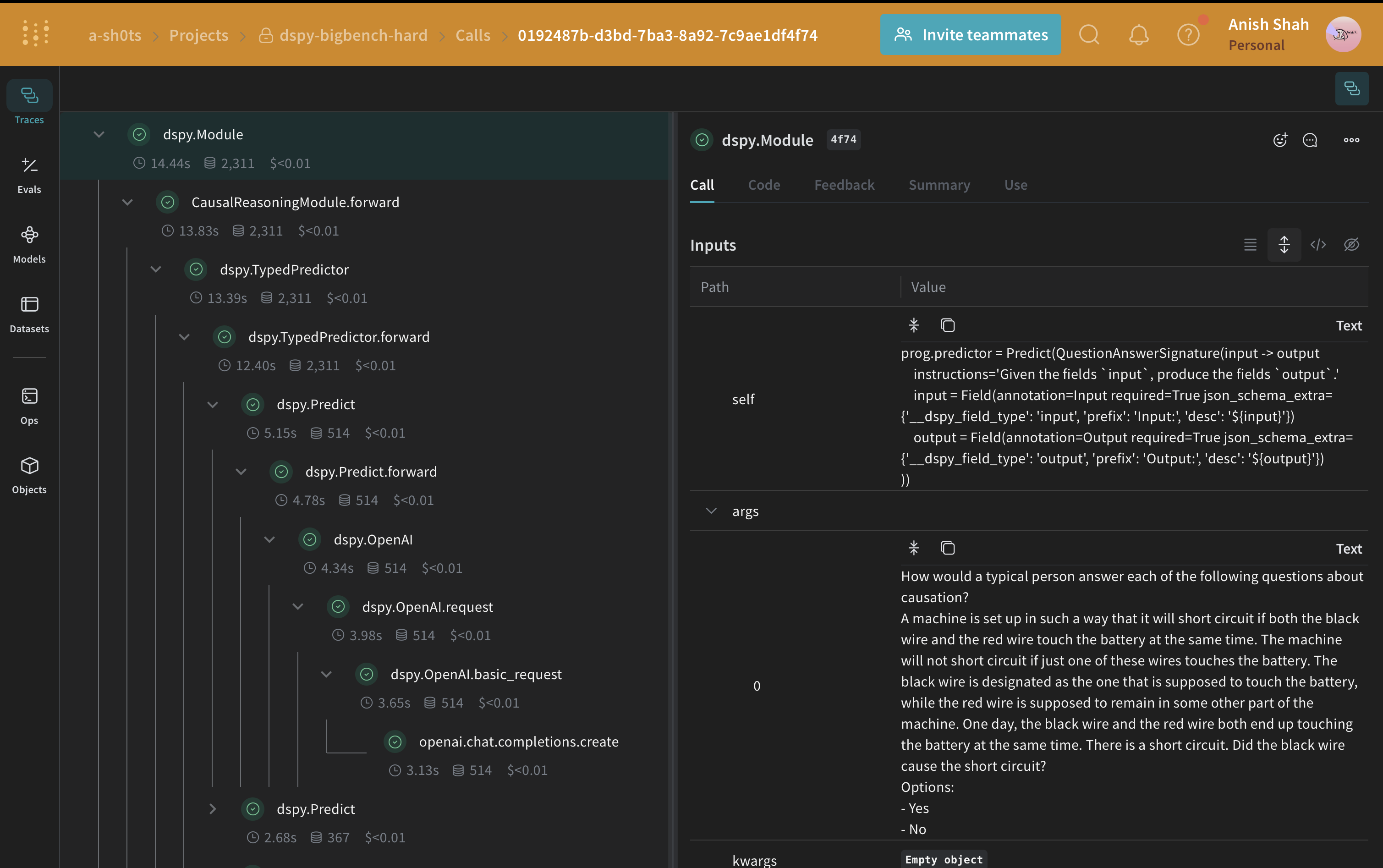
BIG-Bench Hard の因果推論サブセットの例を使って、LLMワークフロー、つまり CausalReasoningModule をテストします。
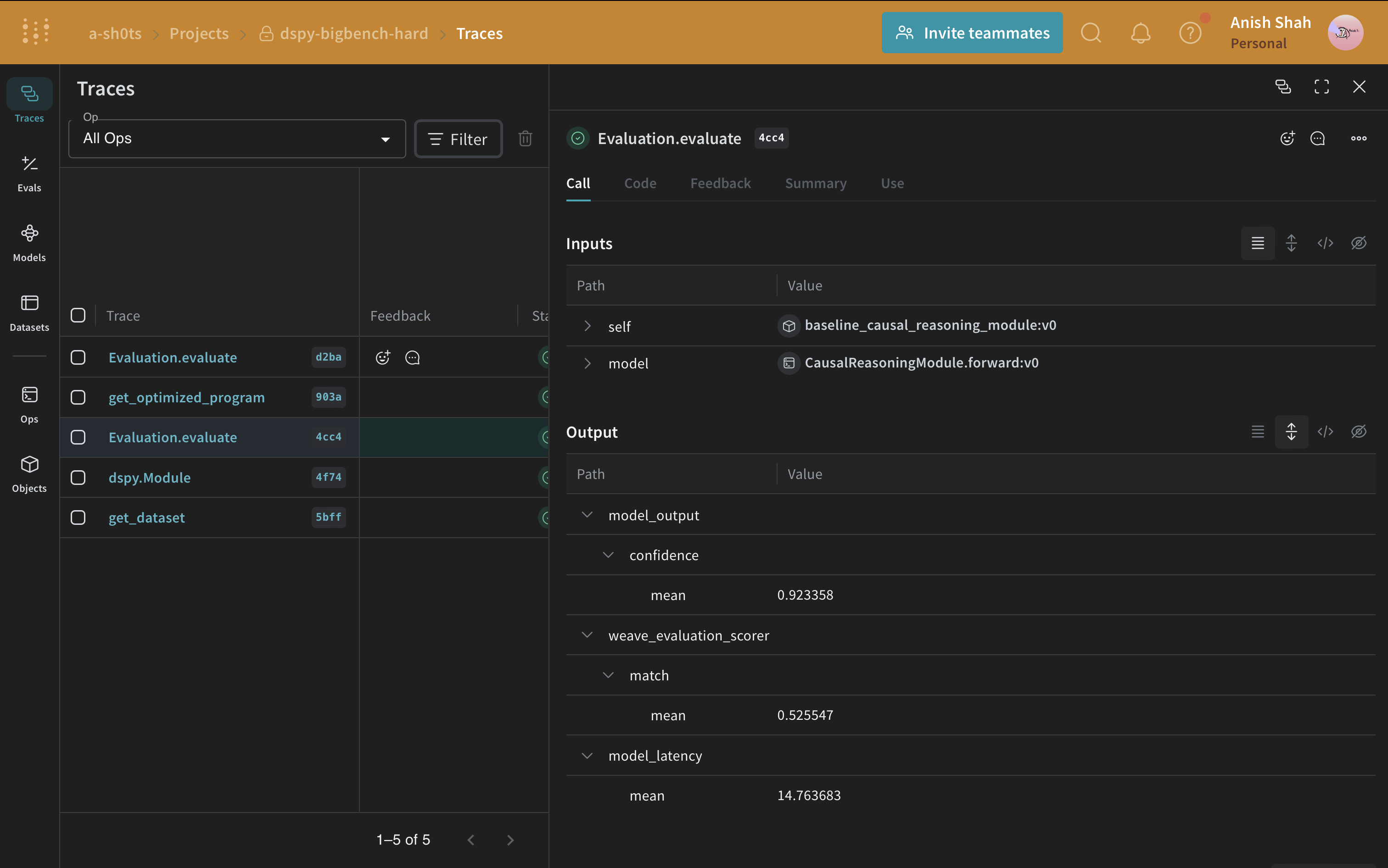
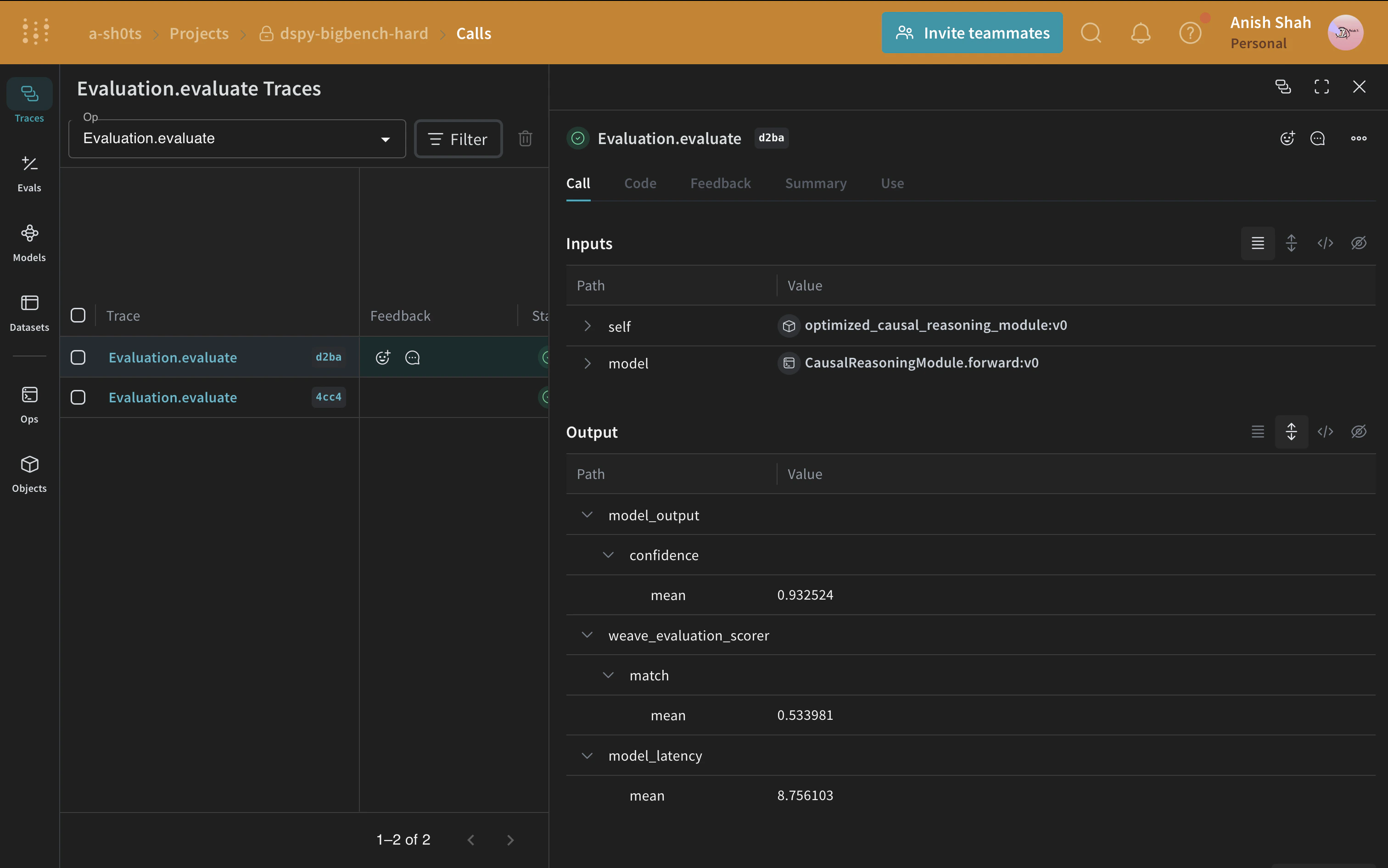
ベースラインのプロンプト戦略ができたので、予測した回答と正解を照合するメトリクスを使って、weave.Evaluation で検証セットを評価します。Weave は各例をアプリケーションに渡し、複数のカスタムスコアリング関数で出力を採点します。これにより、アプリケーションのパフォーマンスを把握できるほか、個々の出力やスコアを詳しく確認できる充実した UI も利用できます。
まず、予測した回答が正解と一致するかどうかを判定するスコアリング関数を作成します。Weave のスコアリング関数は、モデルの戻り値を output として受け取り、さらにデータセット例内の一致するキーを追加の引数として受け取ります。ここでは、answer はデータセットから取得され、output は CausalReasoningModule.forward が返す dict です。
次に、weave.Evaluation から呼び出せるように、モジュールをトレース対象の関数でラップします。ラッパーの引数名は、モデルが受け取るデータセットの列名と一致している必要があります。
ここで、評価を定義して実行します。
Python スクリプトから実行している場合は、次のコードを使用して評価を実行できます。 因果推論データセットで評価を実行するには、OpenAI クレジットが約 $0.24 かかります。
因果推論の評価用データセットを実行すると、OpenAI クレジットが約 $0.04 かかります。