これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用できます。
Weave を使用する理由
- LLM パイプラインをトラッキングする: コード生成プロセスの入力、出力、中間 step をログします。
- LLM の出力を評価する: デバッグツールと可視化機能を使用して、生成したコードの評価を作成し、比較します。
環境を設定する
Weave は、inputs、outputs、メタデータを含む OpenAI API の Call を自動的にトラッキングします。OpenAI とのやり取りのために、追加でログ記録用のコードを書く必要はありません。Weave がバックグラウンドで処理します。
structured outputs と Pydantic モデル
- タイプ安全性: 期待する出力に対して Pydantic モデルを定義することで、生成されるコード、プログラムランナー、ユニットテストに厳密な構造を強制できます。
- パースのしやすさ: structured outputs モードを使うと、モデルのレスポンスを事前定義した Pydantic モデルに直接パースできるため、複雑な後処理の必要性を減らせます。
- 信頼性の向上: 期待する形式を明示することで、言語モデルから予期しない出力や形式が不正な出力が返される可能性を低減できます。
コードフォーマッターを実装する
CodeFormatterクラスを実装します。このフォーマッターは、生成されたコード、プログラムランナー、ユニットテストに対して、リンティングとスタイルのルールを適用します。
CodeFormatter クラスは、生成されたコードをクリーンアップして整形するための複数のオペレーションを提供します。
- エスケープされた改行を実際の改行に置き換える。
- 未使用の import 文や変数を削除する。
- import を並べ替える。
- PEP 8 に準拠した形式を適用する。
- 不足している import を追加する。
CodeGenerationPipeline を定義する
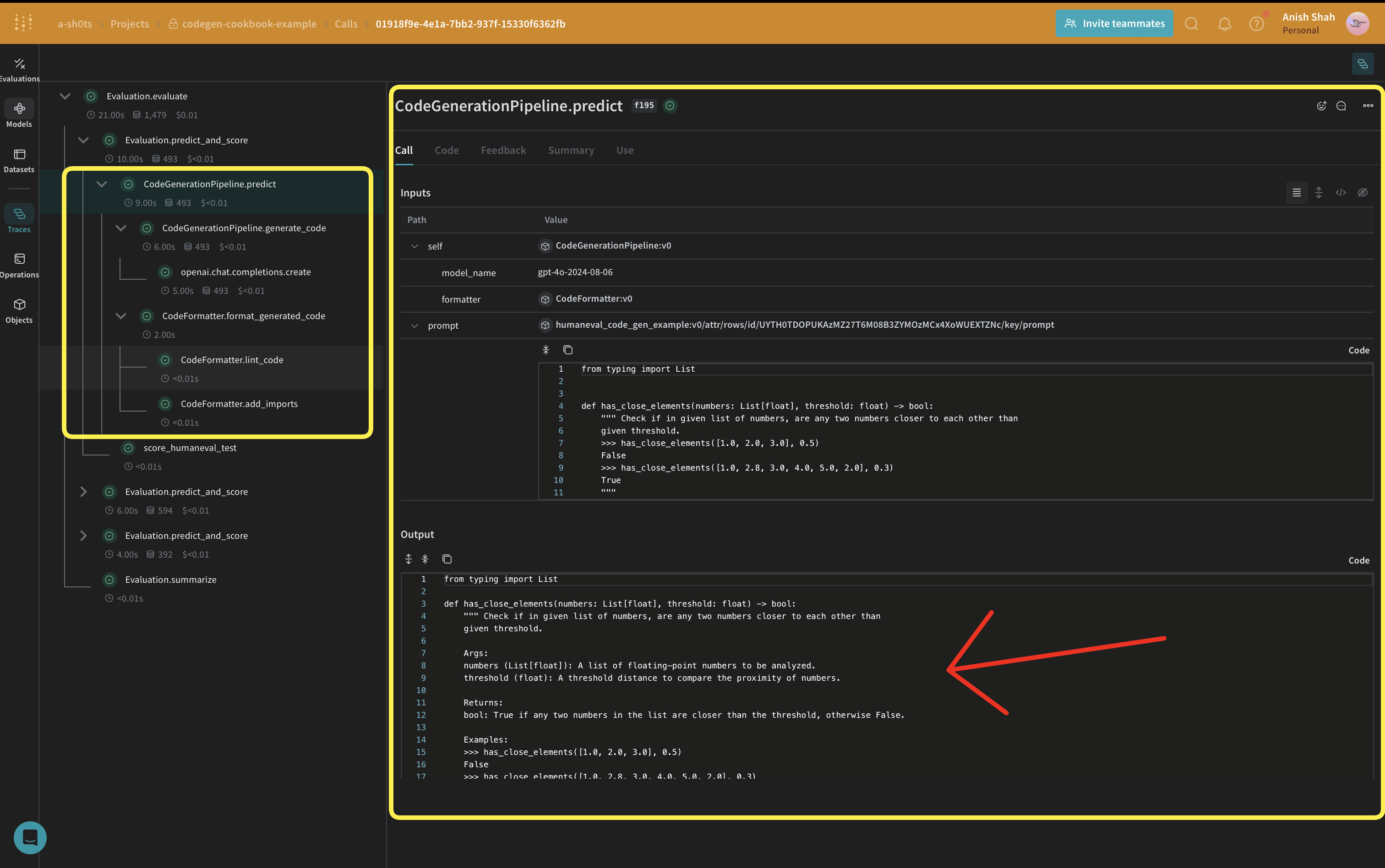
weave.Model を使用します。model_name は属性として保持されるため、これを使って試しながら、Weave で差分を確認して比較できます。関数呼び出しは @weave.op でトラッキングされるため、inputs と output がログされ、エラーのトラッキングやデバッグに役立ちます。
CodeGenerationPipeline クラスは、コード生成ロジックを Weave Model としてカプセル化し、次のような利点を提供します。
- 自動的な実験管理: Weave は、モデルの各 run について入力、出力、パラメーターを自動的に取得します。
- バージョン管理: モデルの属性やコードへの変更は自動的にバージョン管理されるため、コード生成パイプラインが時間の経過とともにどのように発展したかの履歴が作成されます。
- 再現性: バージョン管理とトラッキングにより、コード生成パイプラインの過去の結果や設定を再現できます。
- ハイパーパラメーター管理: モデルの属性 (
model_nameなど) は異なる run にまたがって定義・トラッキングされるため、実験を進めやすくなります。 - Weave エコシステムとのインテグレーション:
weave.Modelを使用すると、パイプラインを評価やサービング機能など、他の Weave ツールと連携できます。
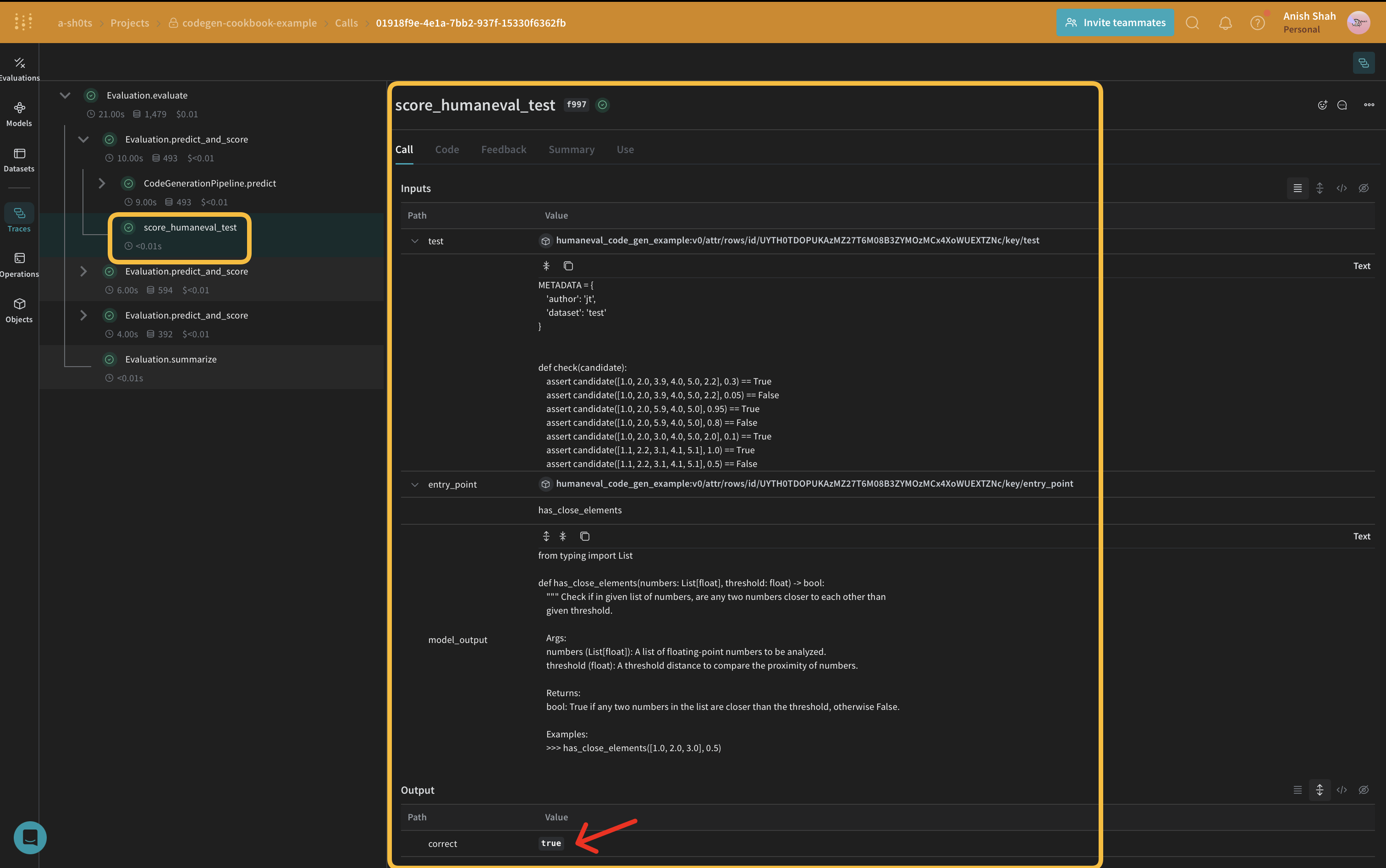
評価メトリクスを実装する
weave.Scorer のサブクラスを使用して評価メトリクスを実装します。これにより、データセット内のすべての model_output に対して score が実行されます。model_output は weave.Model の predict 関数の出力です。prompt は human-eval データセットから取得されます。
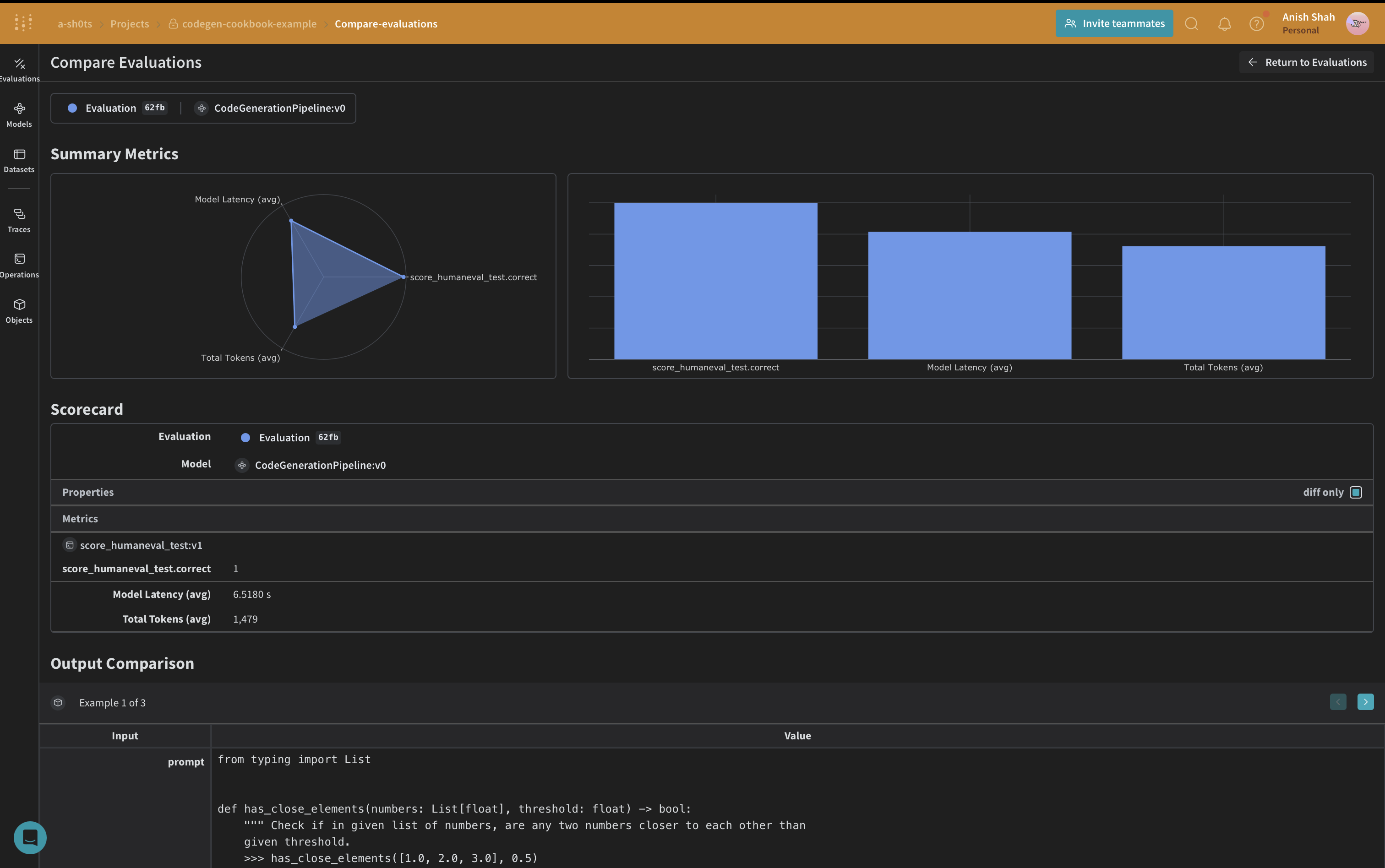
Weave データセットを作成して評価を実行する
結論
- コード生成プロセスの各 step に対応するオペレーションを作成する。
- トラッキングと評価を効率化できるよう、パイプラインを Weave Model でラップする。
- オペレーションを使ってカスタム評価メトリクスを実装する。
- データセットを作成し、パイプラインを評価する。