これはインタラクティブなノートブックです。ローカルで実行することも、以下のリンクを使用することもできます。
- PII データを特定してマスクするための正規表現。
- Python ベースのデータ保護 SDK である Microsoft の Presidio。このツールでは、マスキングと置換の機能を利用できます。
- 偽データを生成する Python ライブラリ Faker。Presidio と組み合わせることで、PII データを匿名化できます。
weave.op input/output logging customization と autopatch_settings の使い方も学びます。詳細は、Customize logged inputs and outputsを参照してください。
開始するには、以下の手順に従ってください。
- 概要 セクションを確認します。
- prerequisites を完了します。
- PII データの特定、マスキング、匿名化に使用できる available methods を確認します。
- Apply the methods to Weave calls を確認します。
概要
weave.op を使用した入出力のロギングの概要と、Weave で PII データを扱う際のベストプラクティスを紹介します。
weave.op を使用して入出力のロギングをカスタマイズする
weave.op() の引数として渡します。
PII データで Weave を使用する際のベストプラクティス
テスト時
- PII の検出を確認するため、匿名化したデータをログする。
- Weave トレースで PII の処理プロセスをトラッキングする。
- 実際の PII を露出させずに、匿名化のパフォーマンスを測定する。
本番環境では
- 未加工のPIIは絶対にログしない。
- ログする前に機微なフィールドを暗号化する。
暗号化のポイント
- 後で復号する必要があるデータには、可逆暗号化を使用します。
- 元に戻す必要のない一意の ID には、一方向ハッシュを使用します。
- 暗号化したまま分析する必要があるデータには、専用の暗号化方式の利用を検討します。
事前準備
- まず、必要なパッケージをインストールします。
- 次の場所でAPIキーを作成します。
- Weave プロジェクトを初期化します。
- 10 個のテキストブロックを含むデモ用の PII データセットを読み込みます。
マスキング方法の概要
- 正規表現を使用して PII データを特定し、マスクします。
- Microsoft Presidio。マスキングと置換の機能を備えた、Python ベースのデータ保護 SDK です。
- Faker。偽データを生成するための Python ライブラリです。
方法 1: 正規表現を使用してフィルタリングする
方法 2: Microsoft Presidio を使用してマスクする
"My name is Alex" 内の Alex を <PERSON> に置き換えます。
Presidio では、一般的なエンティティ が標準でサポートされています。以下の例では、PHONE_NUMBER、PERSON、LOCATION、EMAIL_ADDRESS、US_SSN のいずれかに該当するすべてのエンティティをマスクします。Presidio による処理は関数にまとめられています。
方法 3: Faker と Presidio を使用して置換で匿名化する
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
Presidio と Faker でデータを処理すると、次のようになる場合があります。
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio と Faker を一緒に使用するには、custom operator への参照を指定する必要があります。これらの operator は、PII をダミーデータに置き換える Faker の function を Presidio が使用するように指定するものです。
Method 4: autopatch_settings を使用する
autopatch_settings を使用すると、サポートされる1つ以上のLLMインテグレーションについて、初期化時にPII処理を直接設定できます。W&Bでは、特定のインテグレーションのすべてのCallにわたってPII処理を一元化したい場合、この方法を推奨しています。この方法の利点は次のとおりです。
- PII処理ロジックを初期化時に一元化して適用できるため、各所に分散したカスタムロジックの必要性を減らせます。
- PII処理のワークフローは、特定のインテグレーションごとにカスタマイズしたり、完全に無効化したりできます。
autopatch_settings を使用してPII処理を設定するには、サポートされるLLMインテグレーションのいずれかについて、op_settings で postprocess_inputs または postprocess_output を定義します。
Weave Call にメソッドを適用する
Regex による方法
Presidio を使用したマスキング方法
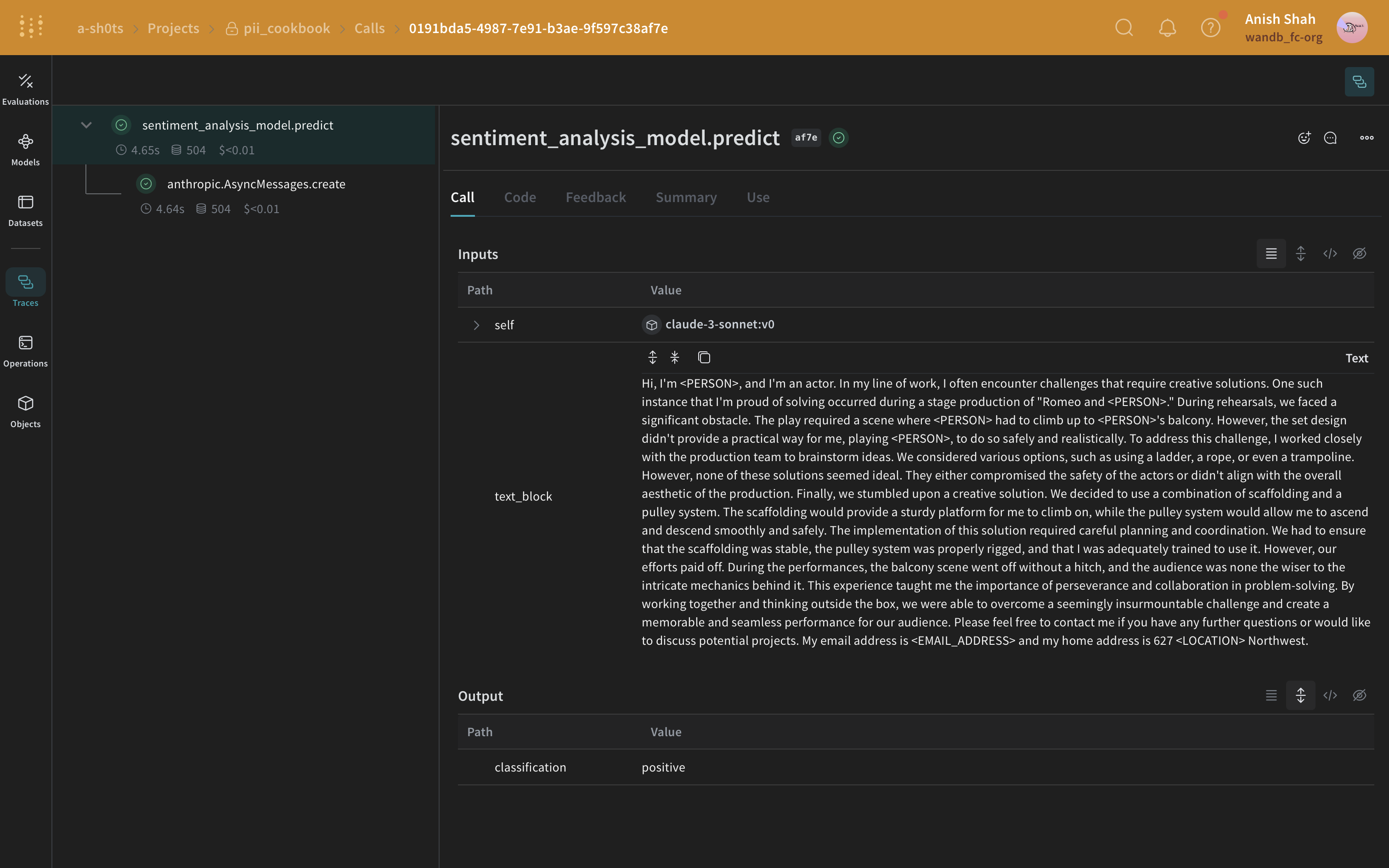
Faker と Presidio の置換方法
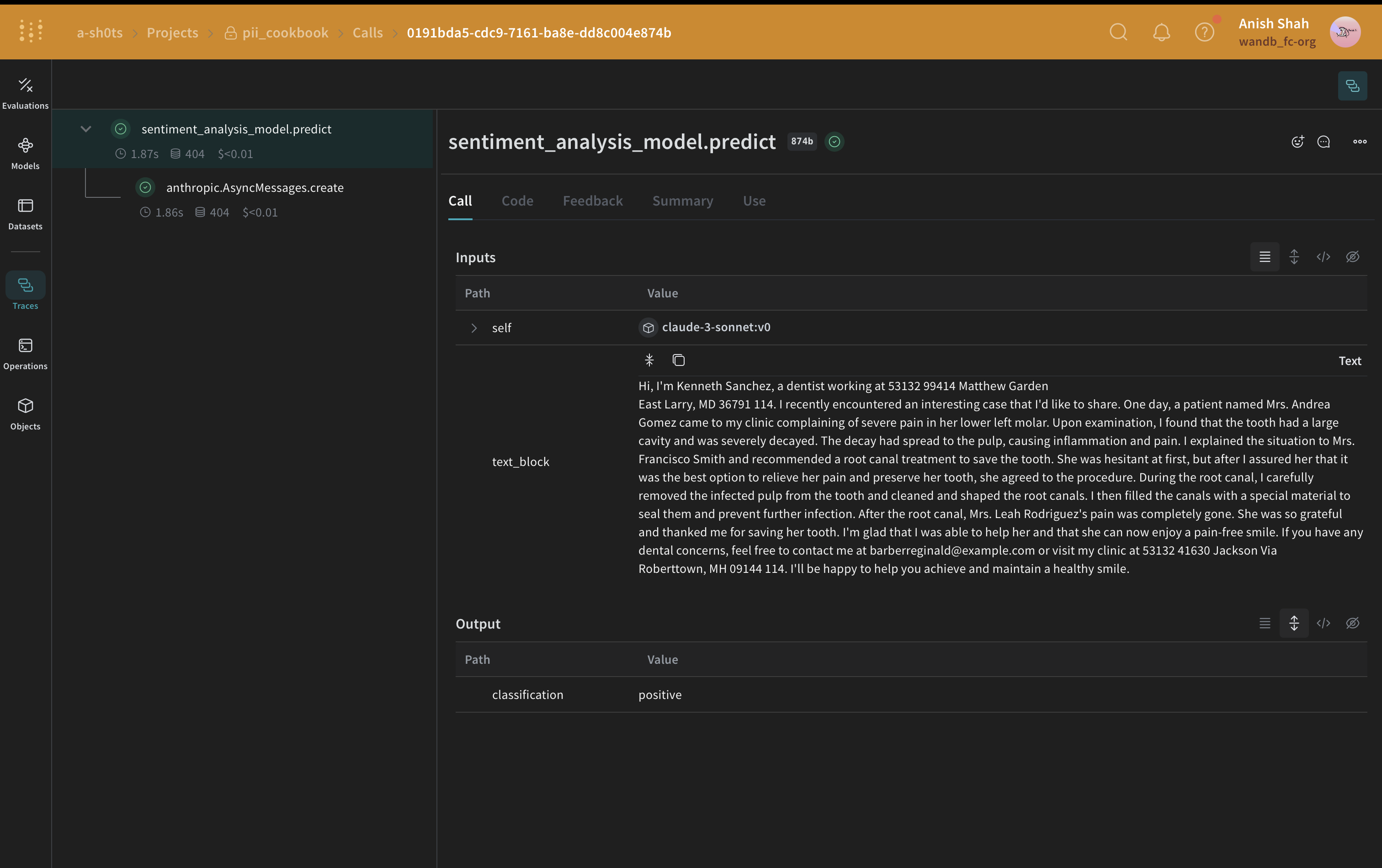
autopatch_settings メソッド
anthropic の postprocess_inputs を postprocess_inputs_regex() 関数に設定しています。postprocess_inputs_regex 関数は、方法 1: 正規表現を使用したフィルター で定義した redact_with_regex メソッドを適用します。その結果、すべての anthropic モデルへの入力に redact_with_regex が適用されます。
オプション: データを暗号化する
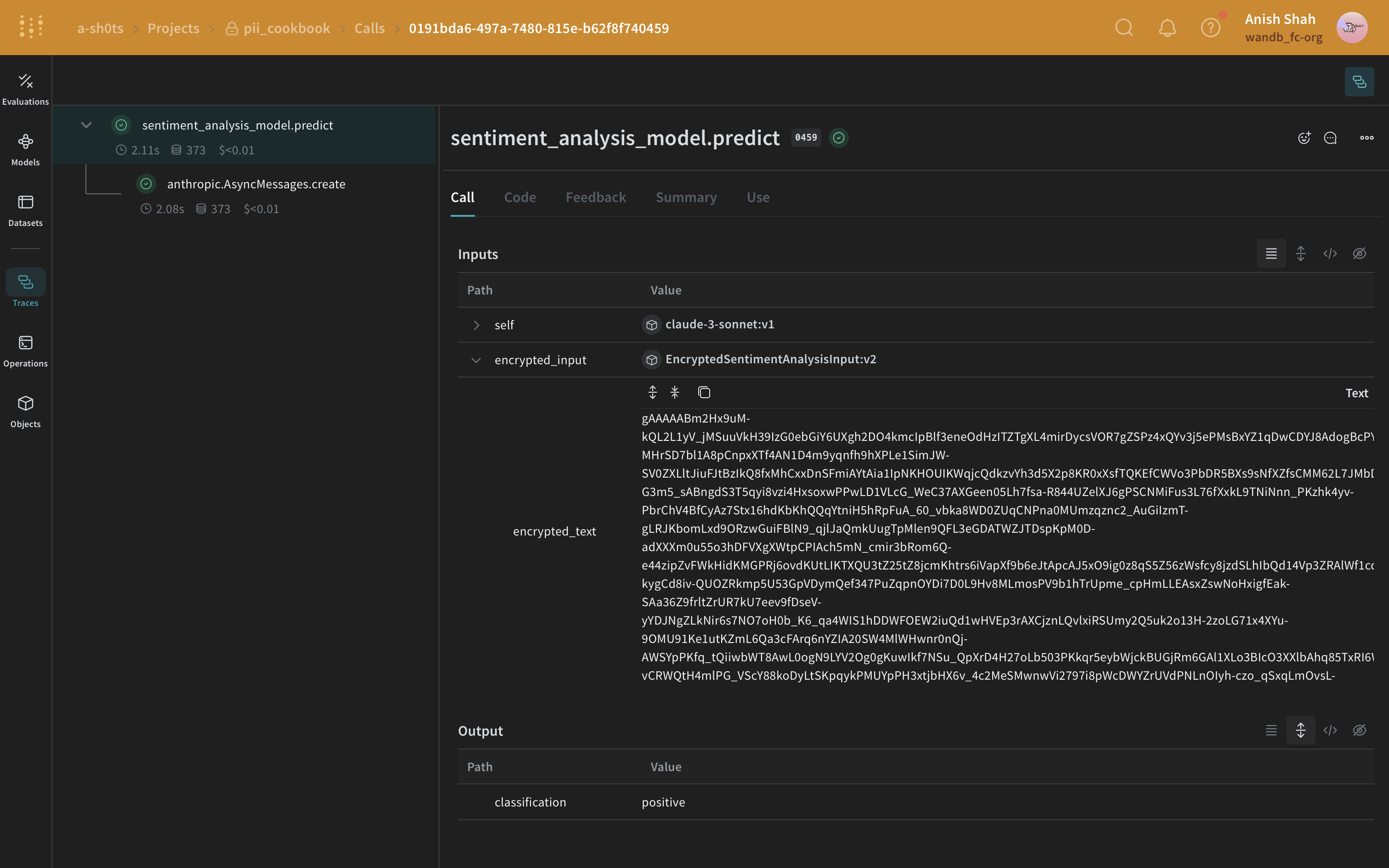
predict メソッド内で復号する方法を示します。