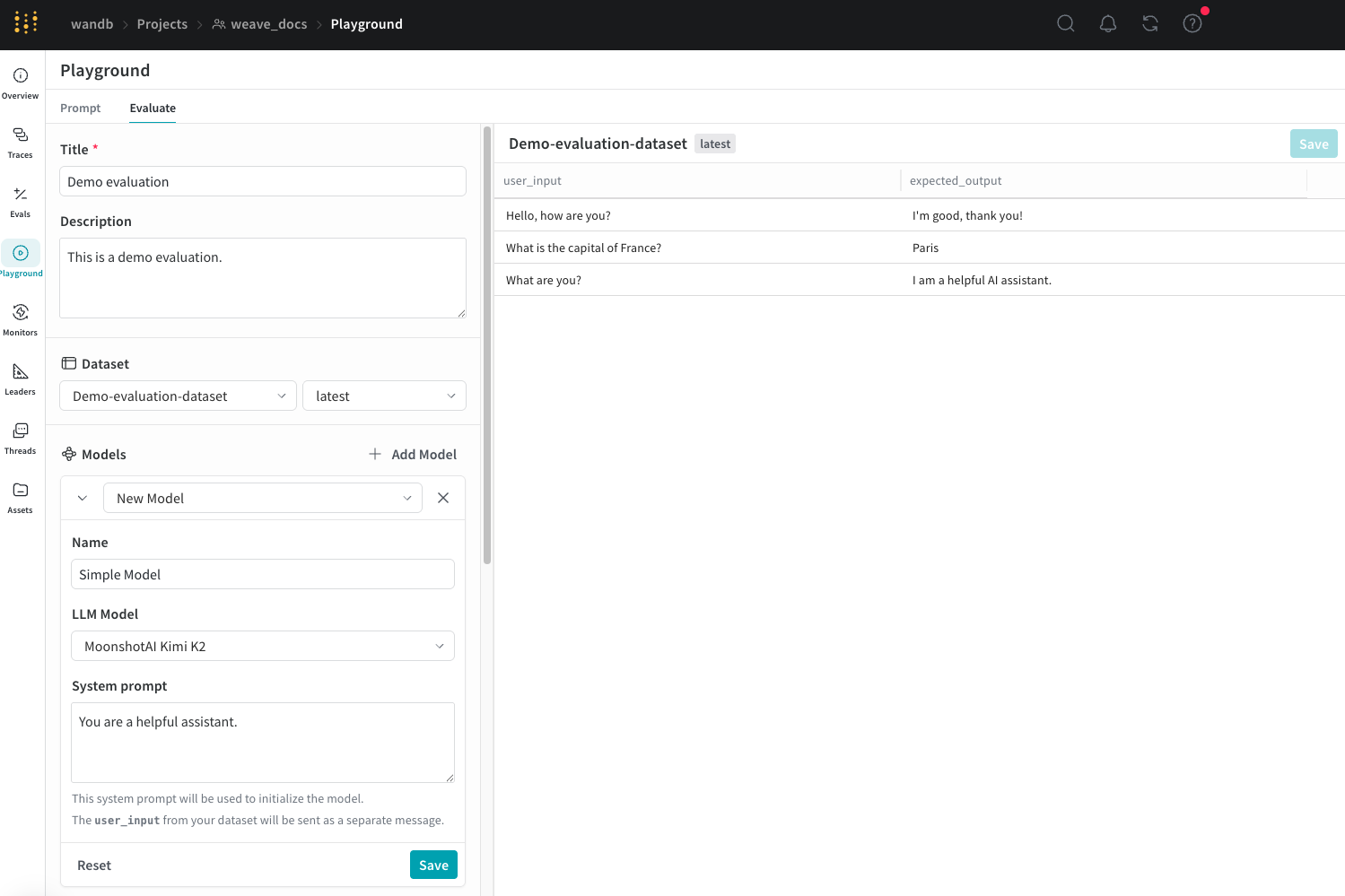
playground で評価を設定する
- Weave UI を開き、評価を実行するプロジェクトを開きます。Traces ページが開きます。
- Traces ページで左側メニューの Playground アイコンをクリックし、Playground ページで Evaluate タブを選択します。Evaluate ページでは、次のいずれかを実行できます。
- Load a demo example: 期待される出力に対して MoonshotAI Kimi K2 モデルを評価し、その正確性の判定に LLM judge を使用する、事前定義済みの設定を読み込みます。この設定を使って、インターフェースを試すことができます。
- Start from scratch: 構築のベースとなる空の設定を読み込みます。
- Start from scratch を選択した場合は、Title フィールドと Description フィールドに、評価のわかりやすいタイトルと説明を入力します。
データセットを追加する
.csv.tsv.json.jsonl
- ドロップダウンメニューをクリックし、次のいずれかを選択します。
- UI で新しいデータセットを作成する場合は Start from scratch。
- ローカルマシンからデータセットをアップロードする場合は Upload a file。
- プロジェクトにすでに保存されている既存のデータセット。
- 任意: 後で使用できるようにデータセットをプロジェクトに保存するには、Save をクリックします。
UI で編集できるのは、新しいデータセットのみです。また、Scorer がデータにアクセスできるように、データセット内の列名を
user_input と expected_output に設定することも重要です。モデルを追加する
- Add Model をクリックし、New Model を選択するか、ドロップダウンメニューから既存のモデルを選択します。
-
New Model を選択した場合は、次のフィールドを設定します。
- Name: 新しいモデルにわかりやすい名前を付けます。
- LLM Model: OpenAI の GPT-4 など、新しいモデルのベースとなる 基盤モデル を選択します。すでにアクセスを設定している 基盤モデル の一覧から選択することも、Add AI provider を選択してモデルを選び、基盤モデル へのアクセスを追加することもできます。provider を追加すると、その provider のアクセス認証情報の入力が求められます。APIキー、エンドポイント、および Weave からモデルにアクセスするために必要な追加の設定情報の確認方法については、provider のドキュメントを参照してください。
- System Prompt: たとえば
You are a helpful assistant specializing in Python programming.のように、モデルの振る舞いに関する指示を指定します。データセット内のuser_inputは後続のメッセージで送信されるため、system prompt に含める必要はありません。
- 任意: Save をクリックして、後で使用できるようにモデルをプロジェクトに保存します。
- 任意: 複数のモデルを同時に評価するには、Add Model を再度クリックし、必要に応じてほかのモデルを追加します。
Scorer を追加する
-
Add Scorer をクリックし、次のフィールドを設定します。
- Name: Scorer にわかりやすい名前を付けます。
-
Type: スコアの出力形式として、boolean または数値を選択します。Boolean Scorer は、モデルの出力が設定した判定基準を満たしているかどうかに応じて、
TrueまたはFalseの二値を返します。数値 Scorer は0から1の間のスコアを出力し、モデルの出力が判定基準をどの程度満たしているかを総合的に評価します。 - LLM-as-a-judge-model: Scorer の judge として使用する基盤モデルを選択します。Models セクションの LLM Model フィールドと同様に、すでにアクセスを設定済みの基盤モデルから選択することも、新たに基盤モデルへのアクセスを設定することもできます。
-
Scoring Prompt: 出力を評価するための LLM judge パラメーターを指定します。たとえば、ハルシネーションを確認するには、次のようなスコアリングプロンプトを入力します。
スコアリングプロンプトでは、
{user_input}、{expected_output}、{output}など、データセットや応答のフィールドを変数として使用できます。使用可能な変数の一覧を確認するには、UI で Insert variable をクリックします。
- 任意: Save をクリックして、後で使用できるように Scorer をプロジェクトに保存します。
評価を実行する
- Evaluation Playground で評価を実行するには、Run eval をクリックします。
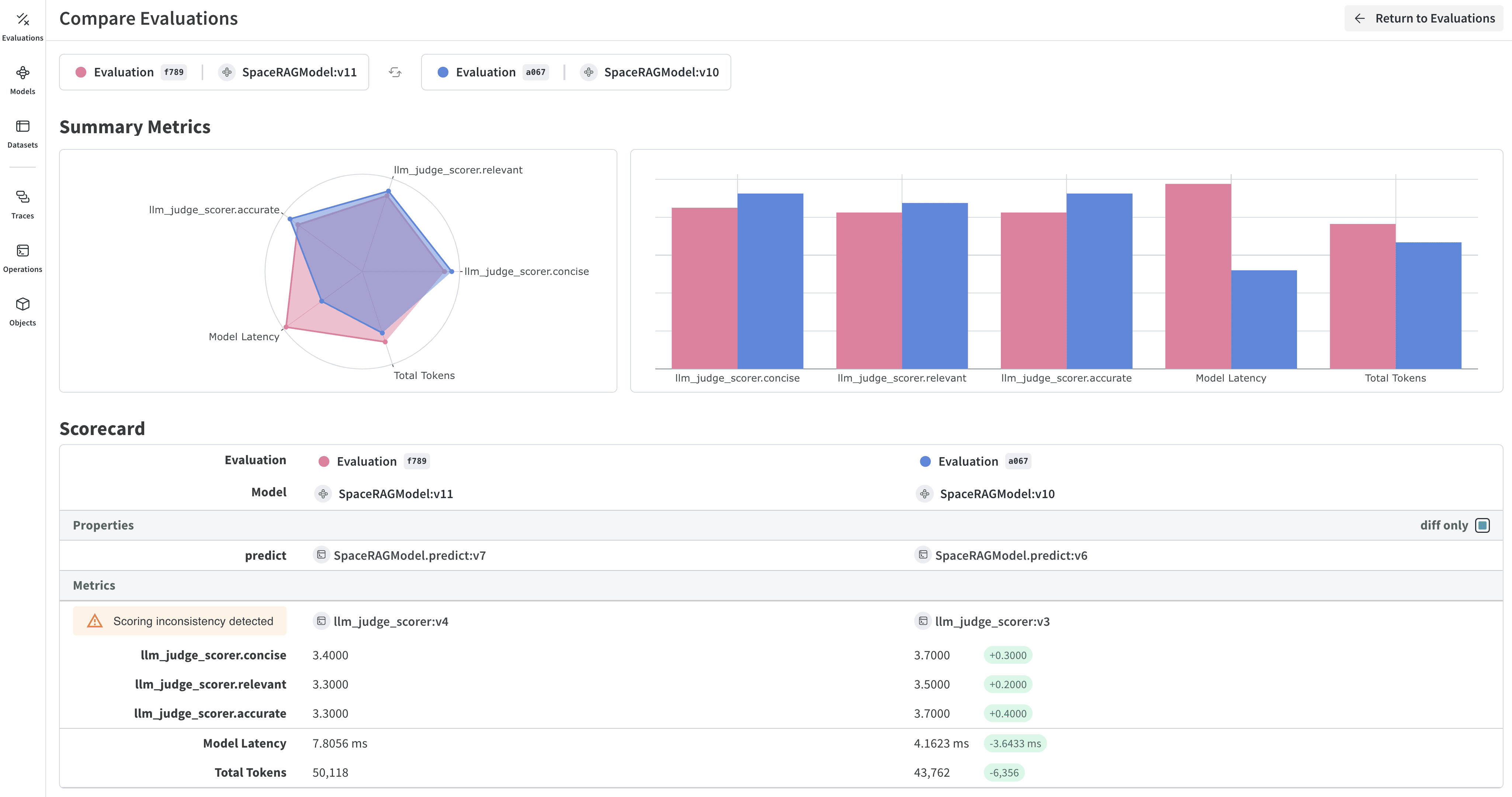
評価結果を確認する