Trainer를 W&B에 연결하는 방법을 보여줍니다. 그러면 트레이닝 run의 메트릭, 모델 체크포인트, 평가 출력이 중앙 집중식 대시보드에 자동으로 로깅됩니다. 이 가이드를 끝내면 run을 비교하고, W&B Artifacts에서 모델 체크포인트를 저장하고 다시 불러오며, 자신의 워크플로에 맞게 로깅을 사용자 지정할 수 있습니다. 이 가이드는 Hugging Face Transformers Trainer를 사용한 모델 트레이닝에 이미 익숙하다고 가정합니다.
빠른 시작
바로 실행해 볼 수 있는 코드부터 보고 싶다면, 이 Google Colab을 확인하세요.
시작하기: 실험 추적
Trainer에서 로깅을 활성화하는 방법을 설명합니다.
가입하고 API 키 생성하기
더 간편하게 하려면 User Settings로 이동해 API 키를 생성하세요. API 키는 즉시 복사해 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단의 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션이 나올 때까지 아래로 스크롤합니다.
wandb 라이브러리 설치 및 로그인
wandb 라이브러리를 설치하고 로그인하려면 다음 단계를 따르세요.
- 명령줄
- Python
- Python notebook
-
WANDB_API_KEY환경 변수를 API 키로 설정합니다.<>로 묶인 값은 사용자 환경에 맞게 바꾸세요. -
wandb라이브러리를 설치하고 로그인합니다.
프로젝트 이름 지정하기
WANDB_PROJECT 환경 변수를 프로젝트 이름으로 설정하세요. WandbCallback은 이 프로젝트 이름 환경 변수를 읽어 run을 설정할 때 사용합니다.
- 명령줄
- Python
- Python notebook
Trainer를 초기화하기 전에 프로젝트 이름을 설정해야 합니다.huggingface입니다.
트레이닝 run을 W&B에 로깅하기
Trainer의 트레이닝 인수를 정의할 때는 W&B 로깅을 활성화하려면 report_to를 "wandb"로 설정하세요. 이 설정이 없으면 Trainer는 어떤 데이터도 W&B로 전송하지 않습니다.
TrainingArguments의 logging_steps 인수는 트레이닝 중 트레이닝 메트릭이 W&B에 얼마나 자주 전송되는지를 제어합니다. run_name 인수를 사용해 W&B에서 트레이닝 run의 이름을 지정할 수도 있습니다.
이제 끝입니다. 이제 모델이 트레이닝되는 동안 loss, 평가 메트릭, 모델 토폴로지, 그라디언트를 W&B에 로깅합니다.
- 명령줄
- Python
TensorFlow를 사용하시나요? PyTorch
Trainer를 TensorFlow TFTrainer로 바꾸세요.모델 체크포인트 저장 사용 설정
WANDB_LOG_MODEL 환경 변수를 다음 값 중 하나 로 설정하세요.
checkpoint:TrainingArguments의args.save_steps마다 체크포인트를 업로드합니다.end:load_best_model_at_end도 설정된 경우 트레이닝이 끝날 때 모델을 업로드합니다.false: 모델을 업로드하지 않습니다.
- 명령줄
- Python
- Python 노트북
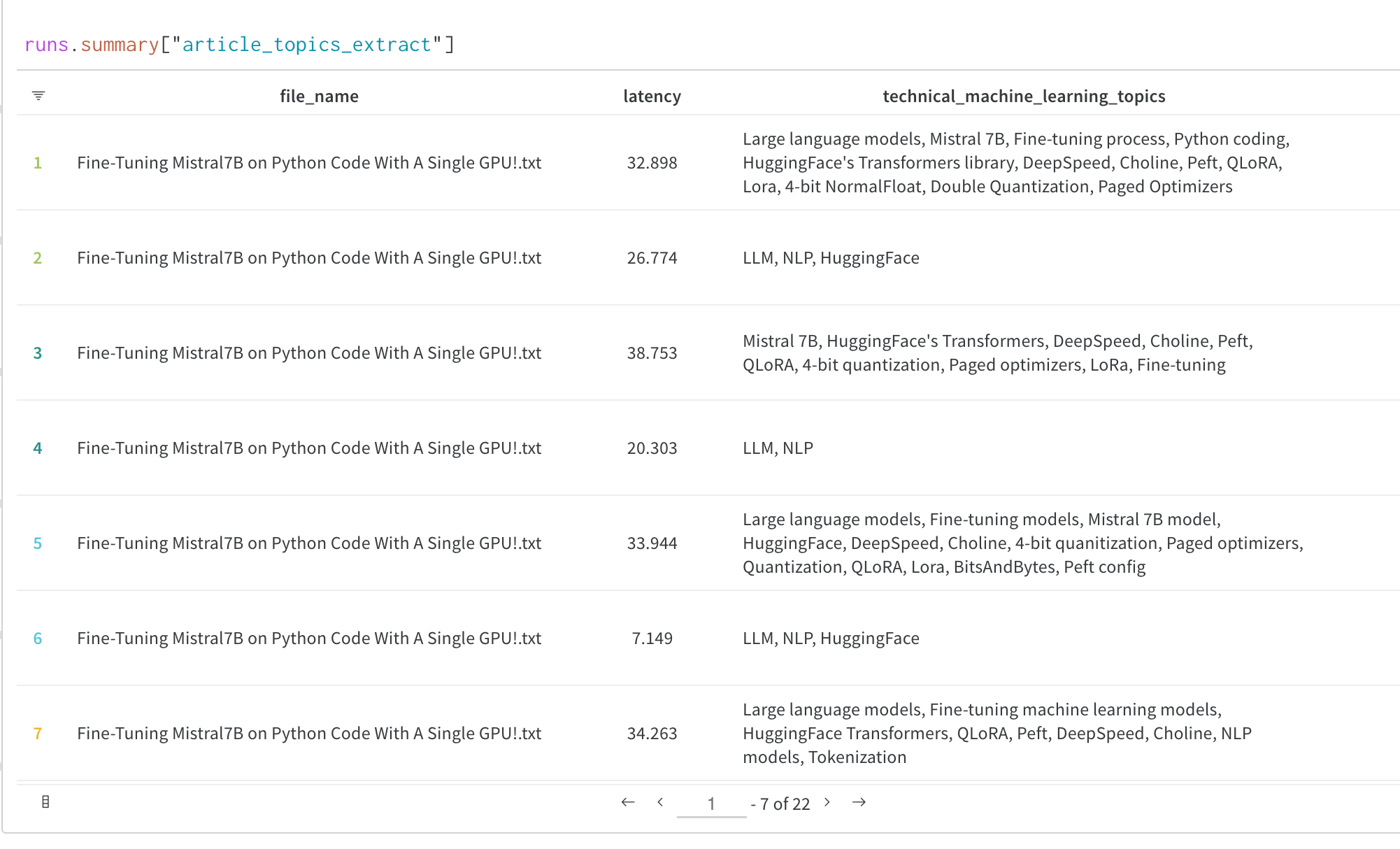
Trainer는 모델을 W&B 프로젝트에 업로드합니다. 로그한 모델 체크포인트는 Artifacts UI에서 확인할 수 있으며, 전체 모델 리니지도 포함됩니다. Artifacts UI의 모델 체크포인트 예시를 참조하세요.
기본적으로
WANDB_LOG_MODEL이 end로 설정되면 모델은 W&B Artifacts에 model-{run_id}로 저장되고, WANDB_LOG_MODEL이 checkpoint로 설정되면 checkpoint-{run_id}로 저장됩니다.
하지만 TrainingArguments에 run_name을 전달하면 모델은 model-{run_name} 또는 checkpoint-{run_name}로 저장됩니다.W&B Registry
트레이닝 중 평가 출력 시각화하기
W&B run 종료하기(노트북 전용)
run.finish()를 호출하세요.
결과 시각화
Trainer는 메트릭을 지정한 이름의 프로젝트에 기록하고, 선택적으로 체크포인트를 Artifacts에 저장하며, 평가 출력을 W&B 대시보드에 표시합니다.
고급 기능 및 자주 묻는 질문
최고 성능 모델 저장
Trainer에 load_best_model_at_end=True가 포함된 TrainingArguments를 전달하면, W&B가 성능이 가장 좋은 모델 체크포인트를 Artifacts에 저장합니다.
모델 체크포인트를 Artifacts로 저장하면 레지스트리로 승격할 수 있습니다. 레지스트리에서는 다음과 같은 작업을 할 수 있습니다:
- ML 작업별로 가장 성능이 좋은 모델 버전을 구성합니다.
- 모델을 중앙에서 관리하고 팀과 공유합니다.
- 모델을 프로덕션에 맞게 스테이징하거나 추가 평가을 위해 북마크합니다.
- 다운스트림 CI/CD 프로세스를 트리거합니다.
저장한 모델 불러오기
WANDB_LOG_MODEL을 사용해 모델을 W&B Artifacts에 저장했다면, 추가 트레이닝을 하거나 Inference를 실행하기 위해 모델 가중치를 다운로드할 수 있습니다. 이전에 사용한 것과 동일한 Hugging Face 아키텍처에 다시 로드하세요.
체크포인트에서 트레이닝 재개
WANDB_LOG_MODEL='checkpoint'를 설정한 경우, TrainingArguments에서 model_dir를 model_name_or_path 인수로 사용하고 Trainer에 resume_from_checkpoint=True를 전달해 트레이닝을 재개할 수 있습니다.
트레이닝 중 평가 샘플을 로깅하고 확인하기
Trainer를 통해 W&B에 로깅하는 작업은 Transformers 라이브러리의 WandbCallback에서 처리합니다. 이 callback을 사용자 지정해 모델 예측, 혼동 행렬 또는 기타 맞춤형 데이터를 로깅할 수 있습니다. 이렇게 하려면 WandbCallback을 서브클래싱하고 Trainer 클래스의 추가 메서드를 사용하는 기능을 추가하세요.
다음은 이 새 callback을 Hugging Face Trainer에 추가하는 일반적인 패턴이며, 이어서 평가 출력을 W&B Table에 로깅하는 전체 코드 예제가 나옵니다:
트레이닝 중 평가 샘플 보기
WandbCallback을 사용자 지정하는 방법을 보여줍니다. 이는 Trainer callback의 on_evaluate 방법을 사용하여 eval_steps마다 실행됩니다.
decode_predictions 함수는 tokenizer를 사용해 모델 출력의 예측과 레이블을 디코딩합니다.
그런 다음 코드는 예측과 레이블로 pandas 데이터프레임을 만들고, 데이터프레임에 epoch column을 추가합니다.
마지막으로 코드는 데이터프레임으로 wandb.Table을 생성하고 이를 W&B에 로깅합니다. freq 에포크마다 예측을 로깅하여 로깅 빈도를 제어할 수 있습니다.
일반
WandbCallback과 달리, 이 맞춤형 callback은 Trainer 초기화 중이 아니라 Trainer가 인스턴스화된 후에 trainer에 추가해야 합니다. 이는 초기화 시 Trainer 인스턴스가 callback에 전달되기 때문입니다.추가 W&B 설정
Trainer에서 무엇을 로깅할지 더 세부적으로 설정할 수 있습니다. W&B 환경 변수의 전체 목록은 환경 변수 레퍼런스를 참조하세요.
- 명령줄
- 노트북
wandb.init() 사용자 지정
Trainer가 사용하는 WandbCallback은 Trainer가 초기화되면 내부적으로 wandb.init()를 호출합니다. 또는 Trainer를 초기화하기 전에 wandb.init()를 호출해 run을 수동으로 설정할 수도 있습니다. 이렇게 하면 W&B run 설정을 완전히 제어할 수 있습니다.
다음은 init에 전달할 수 있는 항목의 예시입니다. wandb.init()의 자세한 내용은 wandb.init() 레퍼런스를 참조하세요.