W&B를 사용하는 이유

- 통합 대시보드: 모든 모델 메트릭과 예측을 한곳에서 관리할 수 있습니다.
- 경량: Hugging Face와 통합하는 데 코드 변경이 필요하지 않습니다.
- 접근성: 개인과 학술 팀은 무료로 사용할 수 있습니다.
- 보안: 모든 프로젝트는 기본적으로 비공개입니다.
- 신뢰성: OpenAI, Toyota, Lyft 등 여러 머신 러닝 팀에서 사용합니다.
설치, 임포트 및 로그인
- Hugging Face Transformers: 자연어 모델 및 데이터셋.
- W&B: 실험 추적 및 시각화.
- GLUE dataset: 언어 이해 벤치마크 데이터셋.
- GLUE script: 시퀀스 분류용 모델 트레이닝 스크립트.
API 키 추가
WANDB_WATCH=all로 설정하면 그라디언트와 파라미터를 모두 기록할 수 있습니다. 전체 옵션 목록은 Hugging Face 인테그레이션 가이드를 참조하세요.
모델 학습
run_glue.py를 실행하면 학습 과정이 자동으로 W&B 대시보드에 기록되는 것을 확인할 수 있습니다. 이 스크립트는 BERT를 Microsoft Research Paraphrase Corpus(두 문장이 의미적으로 동등한지 여부를 사람이 주석으로 표시해 둔 문장 쌍 데이터셋)로 파인튜닝합니다.
대시보드에서 결과 시각화하기
모델 성능 시각화
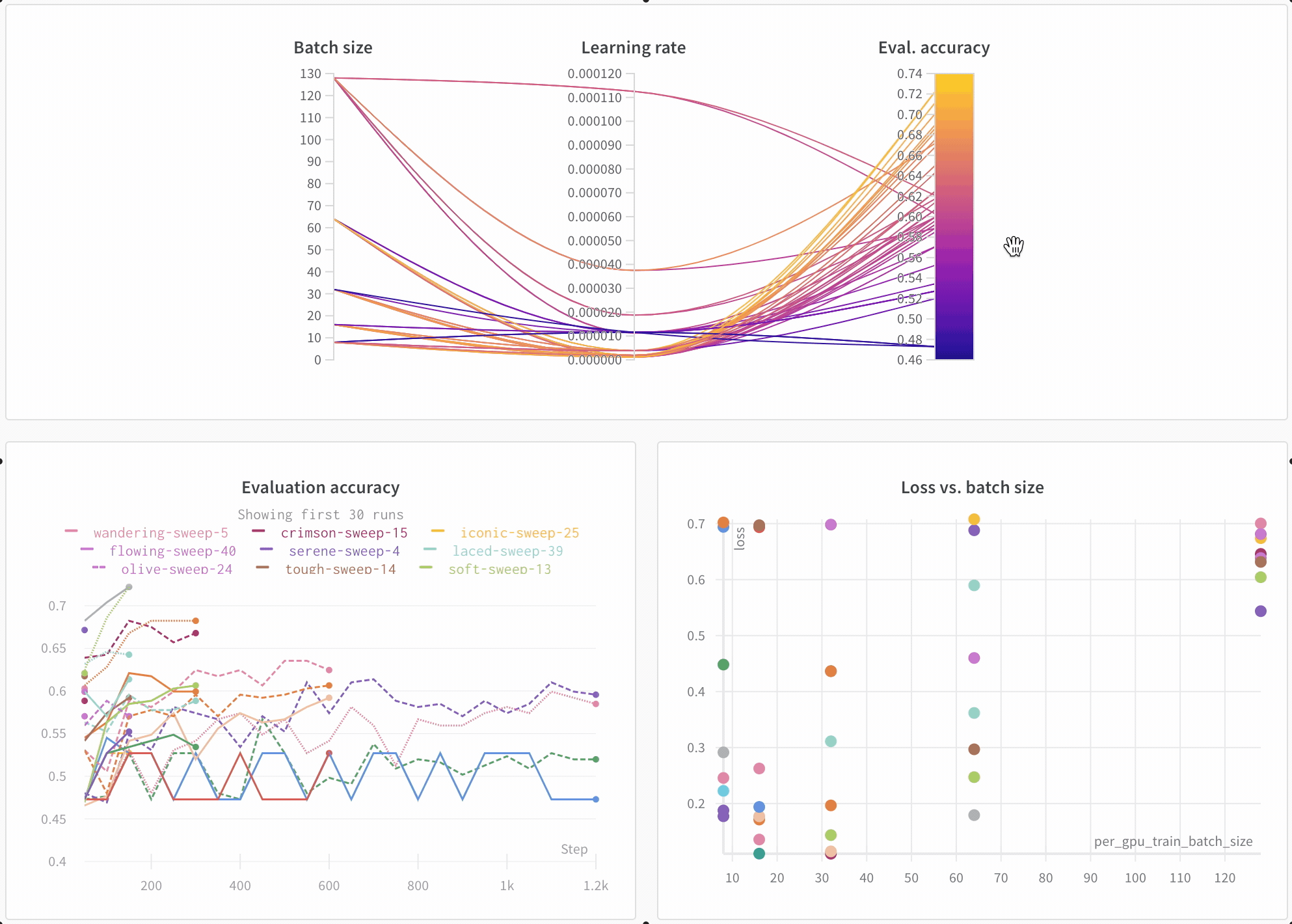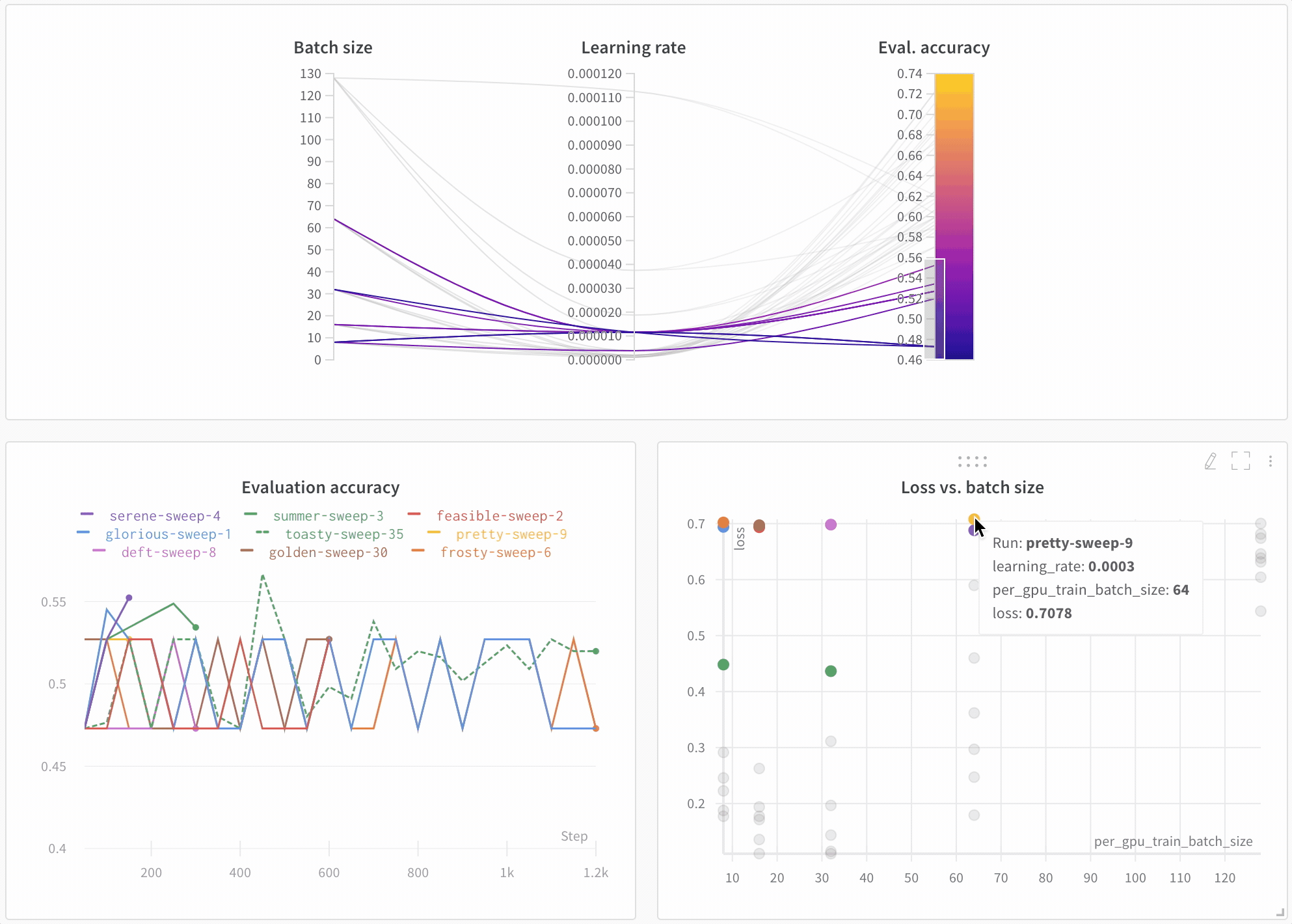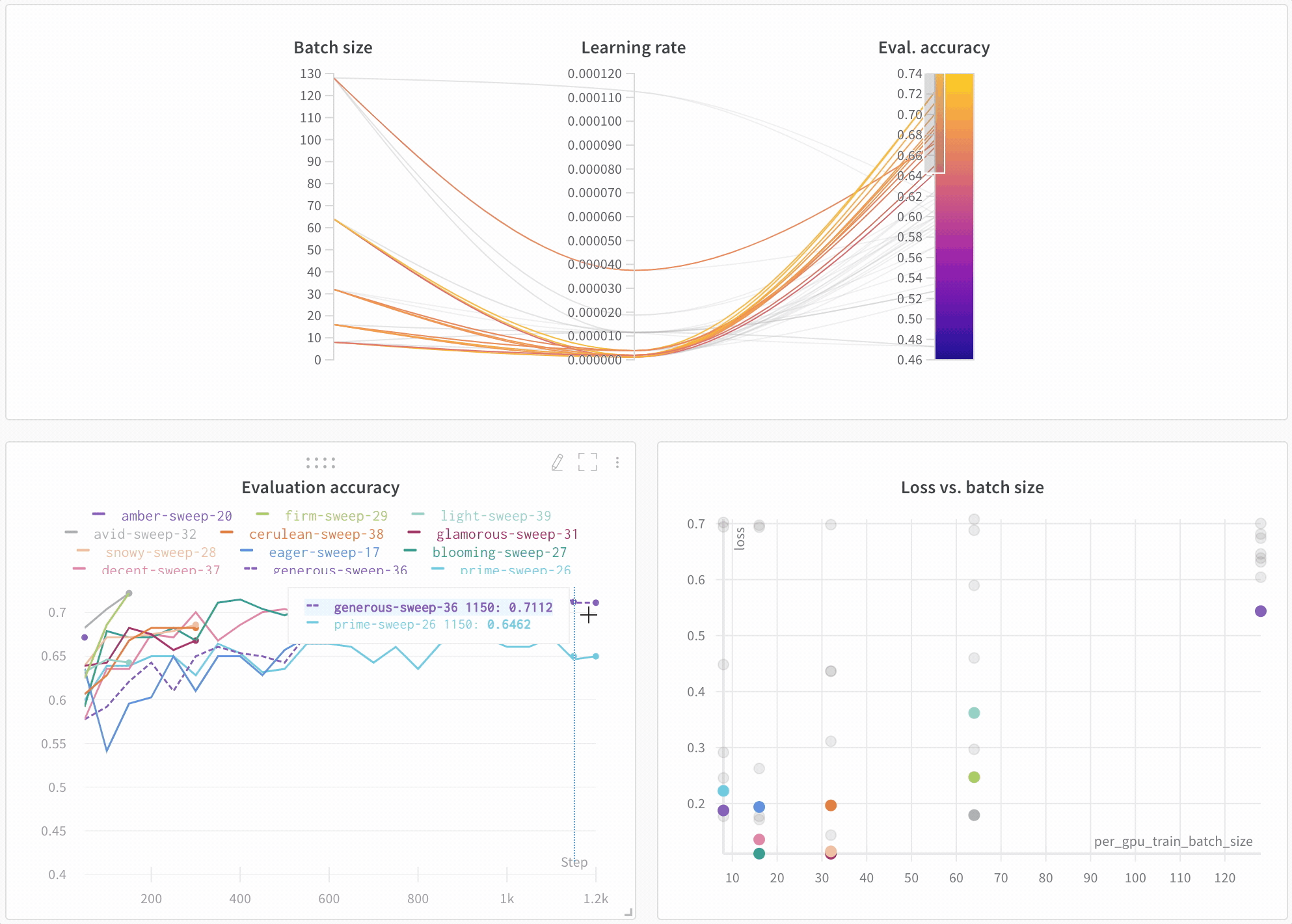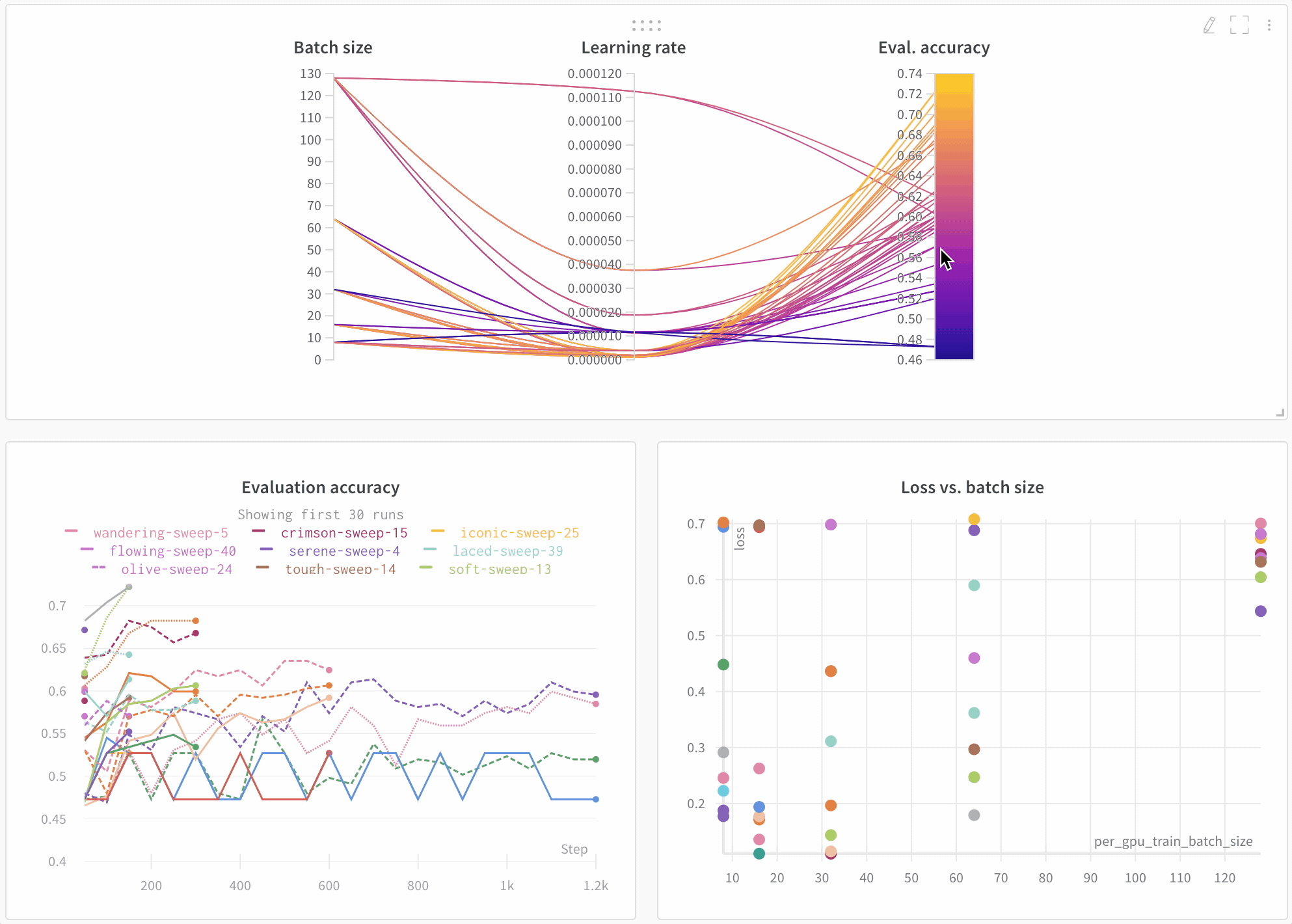
아키텍처 비교
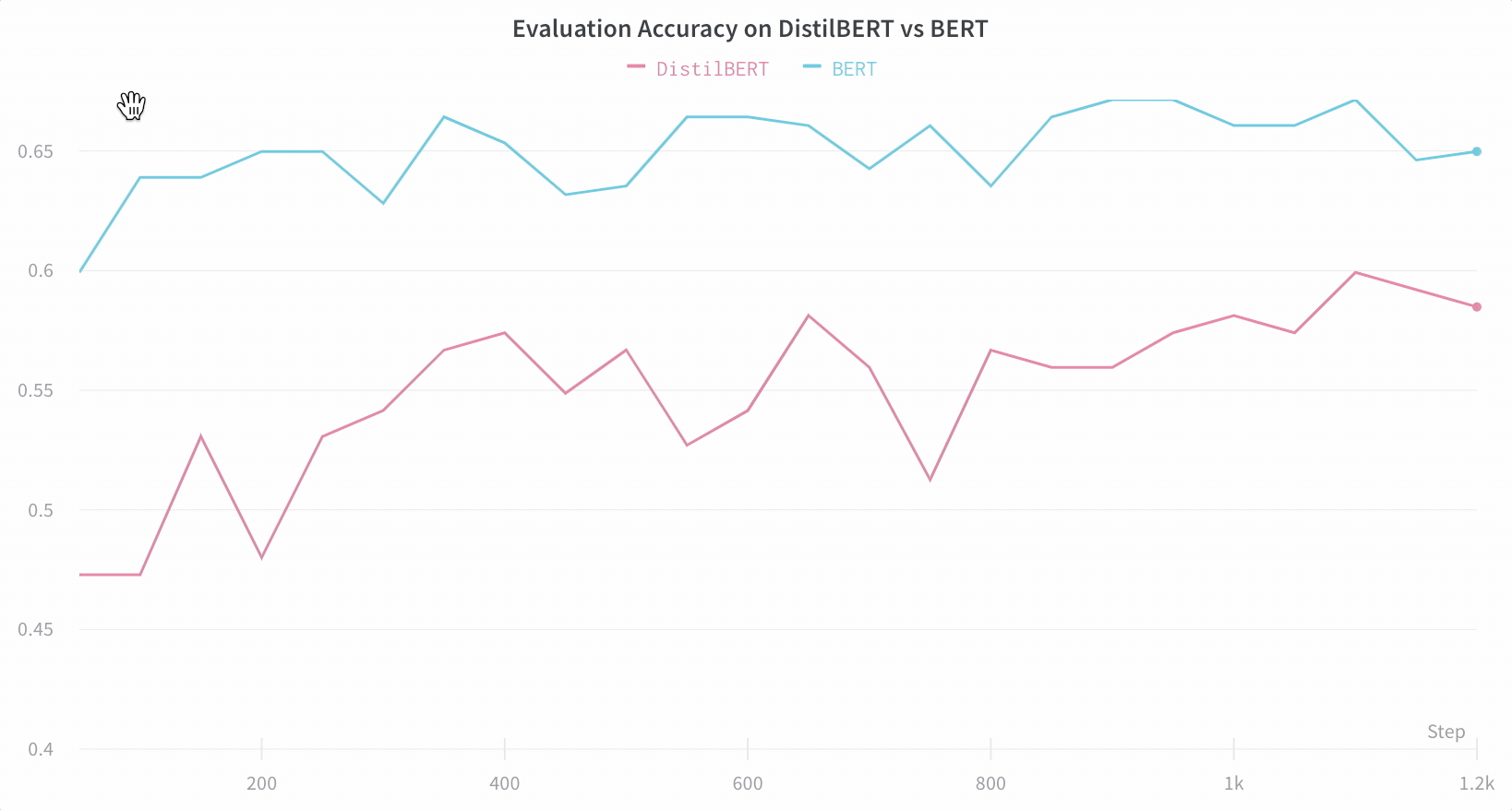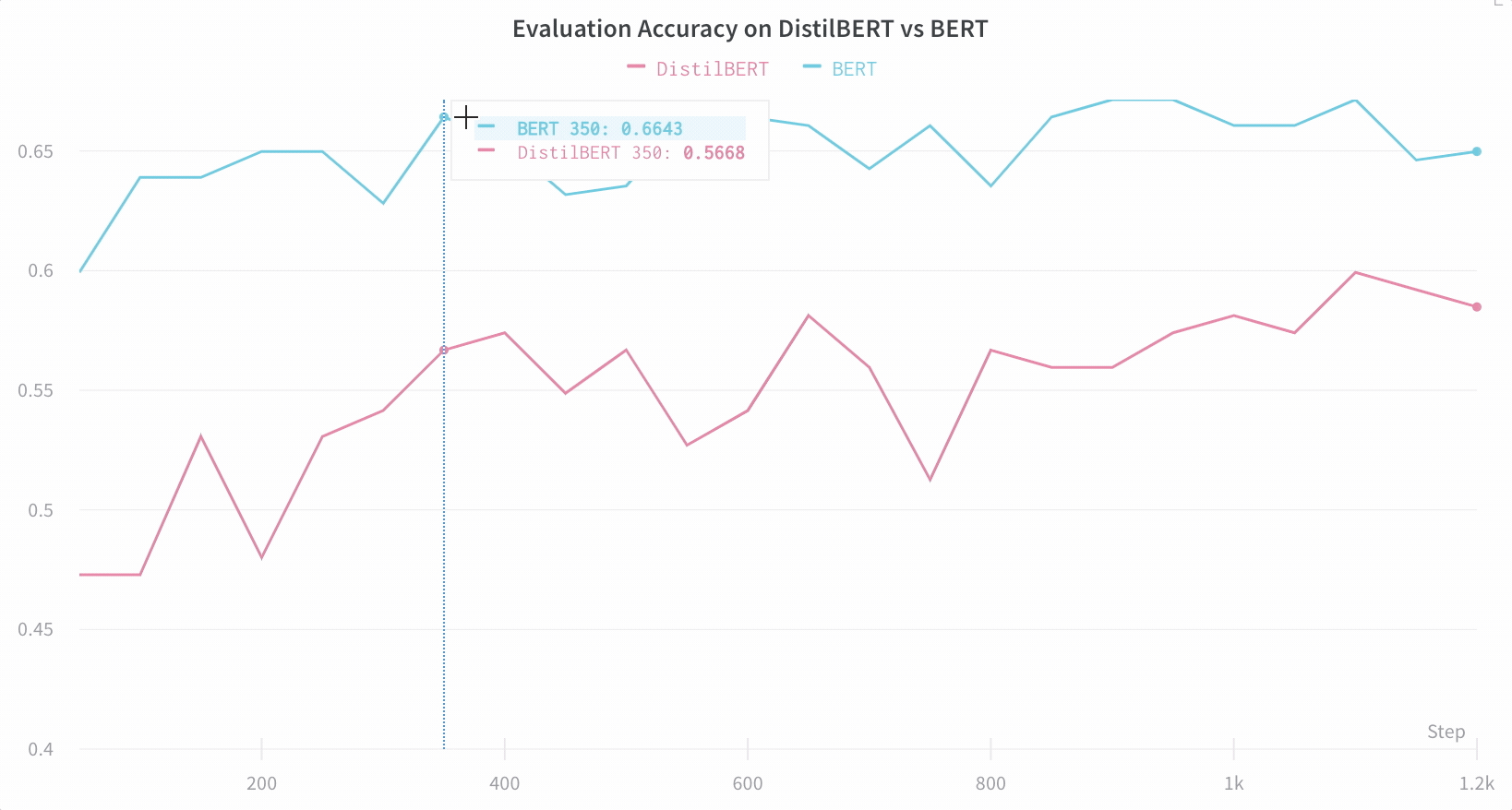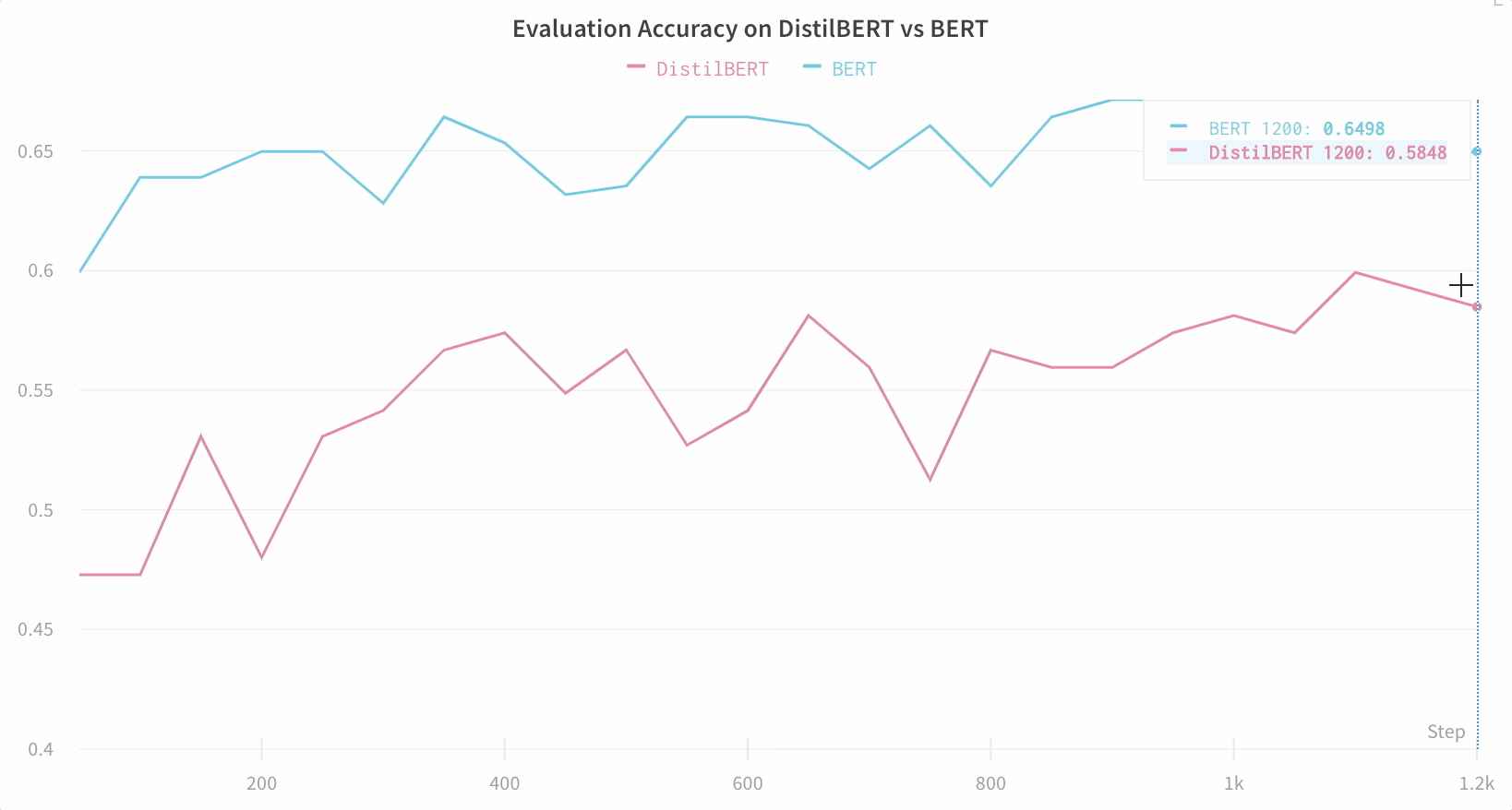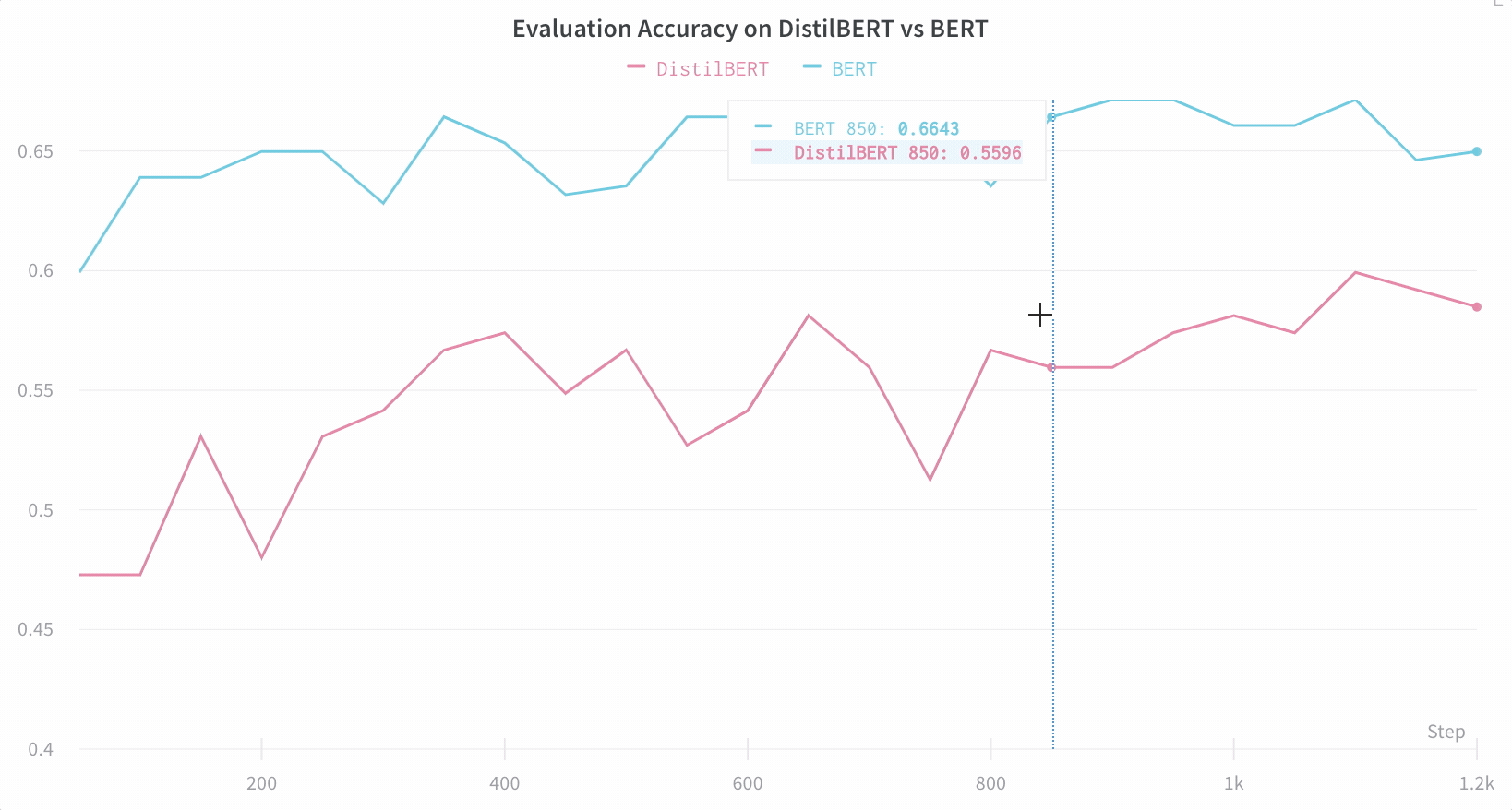
기본적으로 주요 정보를 추적합니다
- 하이퍼파라미터: W&B는 모델의 설정을 Config에 저장합니다.
- 모델 메트릭: W&B는 Log로 스트리밍되는 메트릭의 시계열 데이터를 저장합니다.
- 터미널 로그: W&B는 명령줄 출력을 저장하고 탭에서 확인할 수 있게 합니다.
- 시스템 메트릭: GPU 및 CPU 사용량, 메모리, 온도.