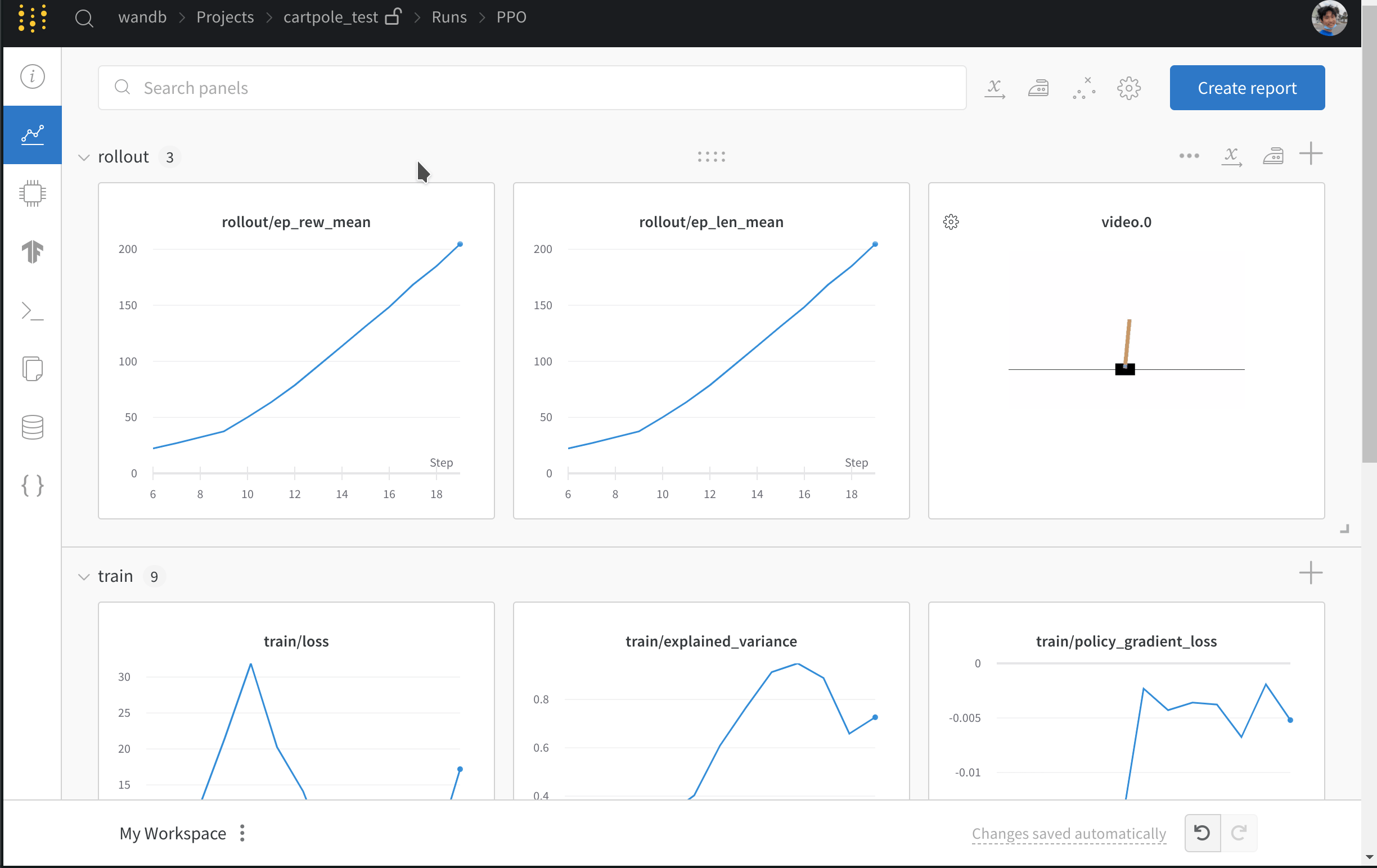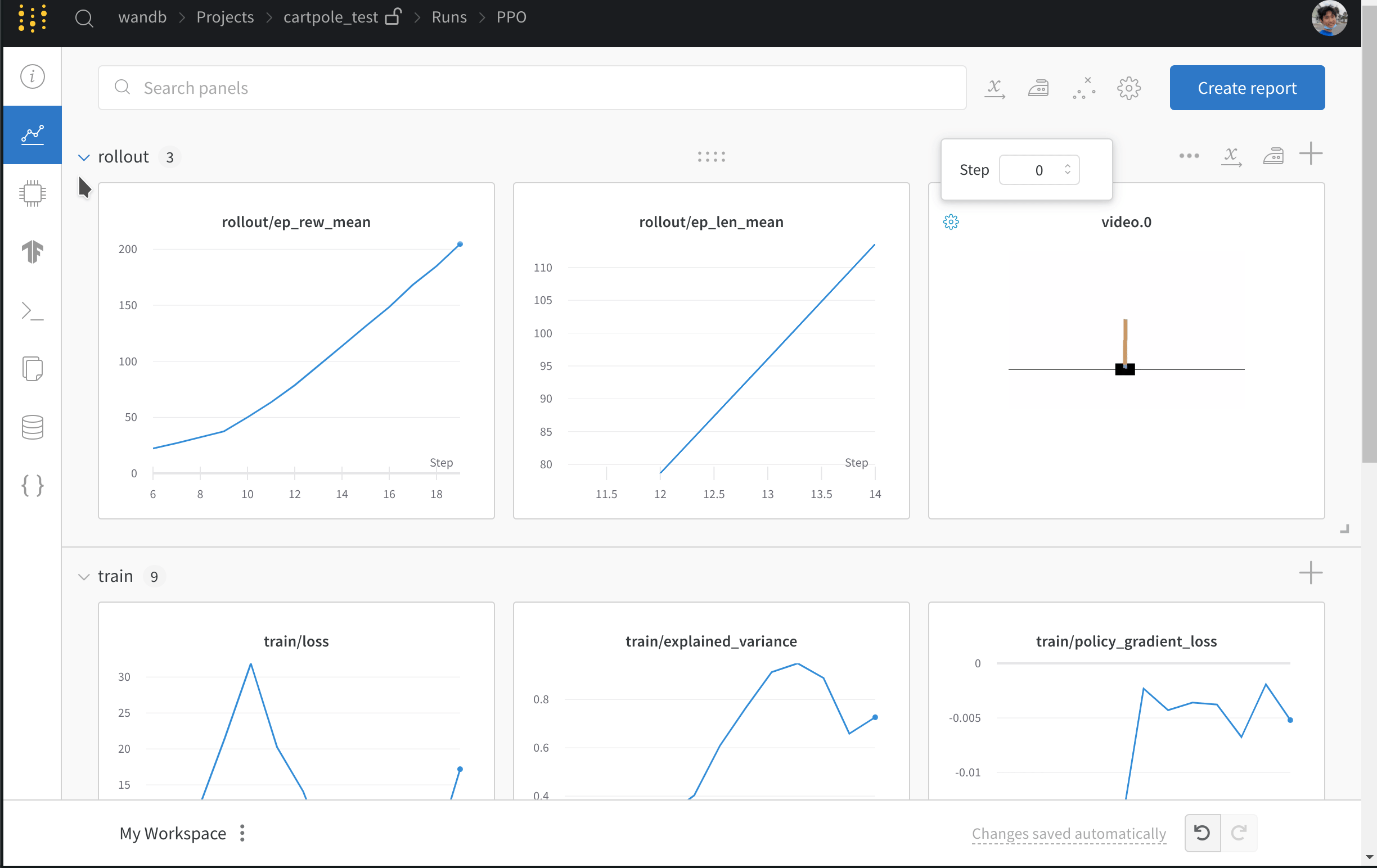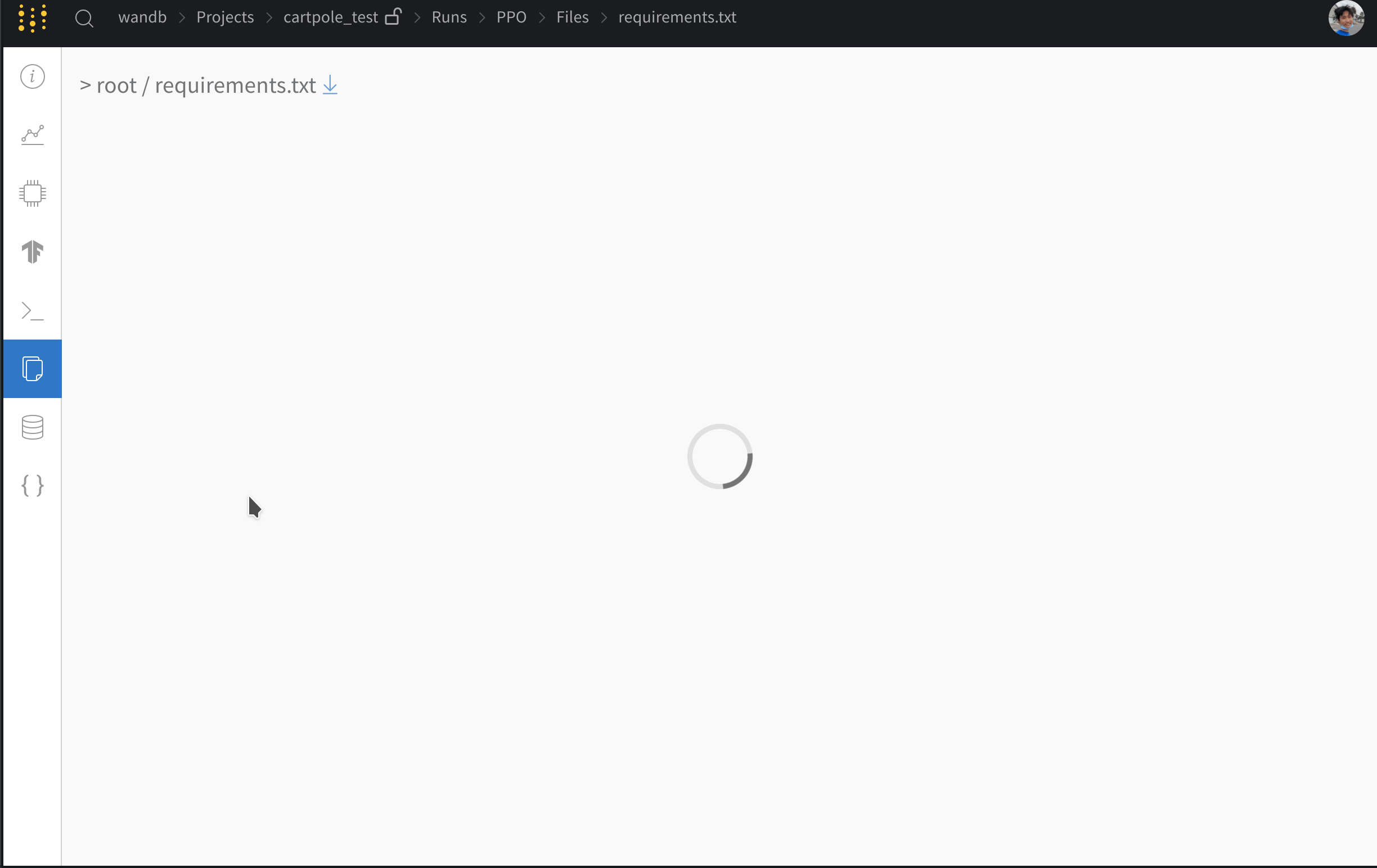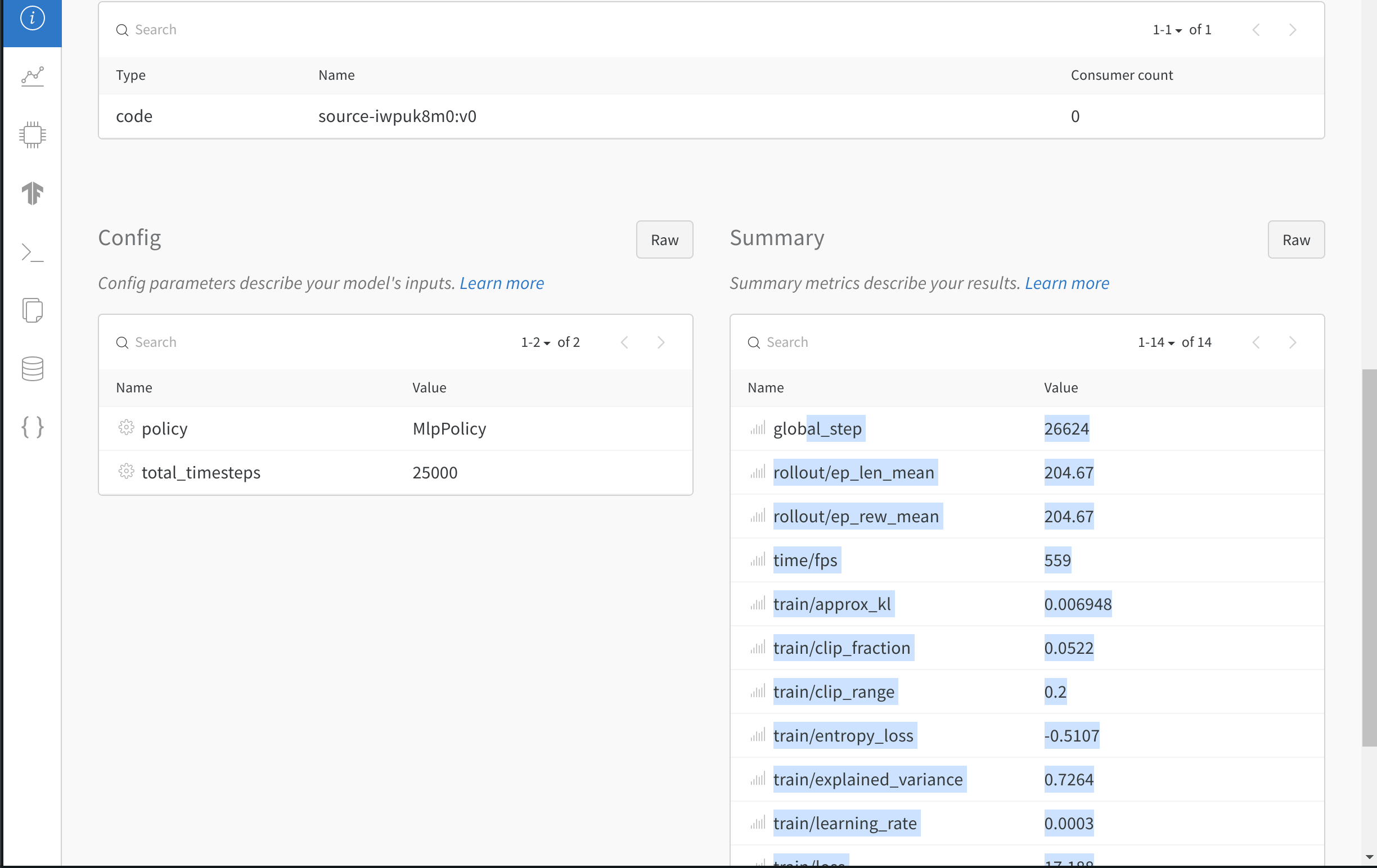
- loss 및 에피소드 반환값과 같은 메트릭을 로깅합니다.
- 에이전트가 게임을 플레이하는 비디오를 업로드합니다.
- 트레이닝된 모델을 저장합니다.
- 모델의 하이퍼파라미터를 로깅합니다.
- 모델 그라디언트 히스토그램을 로깅합니다.
SB3 실험 로깅하기
learn 메서드에 WandbCallback을 전달하세요:
WandbCallback 인수
WandbCallback에 전달할 수 있는 인수를 설명합니다:
강화 학습 실험을 추적하고 트레이닝 성능을 로깅하도록 W&B를 Stable Baselines3와 통합합니다.
learn 메서드에 WandbCallback을 전달하세요:
WandbCallback 인수WandbCallback에 전달할 수 있는 인수를 설명합니다: