wandb)를 사용하면 몇 줄의 코드만으로 scikit-learn 모델 성능을 시각화하고 비교할 수 있습니다. 예시 사용해보기.
시작하기
가입하고 API 키 생성하기
더 간편하게 하려면 User Settings로 이동해 API 키를 생성하세요. API 키는 즉시 복사해 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단의 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
wandb 라이브러리 설치 및 로그인
wandb 라이브러리를 설치하고 로그인하려면 다음 단계를 따르세요.
- 명령줄
- Python
- Python notebook
-
WANDB_API_KEY환경 변수를 API 키로 설정합니다.<>로 묶인 값은 사용자 환경에 맞게 바꾸세요. -
wandb라이브러리를 설치하고 로그인합니다.
메트릭 로깅
플롯 만들기
wandb를 임포트하고 새 run을 초기화하기
플롯 시각화
개별 플롯
모든 플롯
plot_classifier처럼 관련 플롯 여러 개를 그려 주는 함수가 있습니다:
기존 Matplotlib 플롯
plotly를 설치해야 합니다.
지원되는 플롯
wandb.sklearn이 생성할 수 있는 각 플롯 유형별 함수 시그니처와 인수를 설명합니다. 개별 플롯 함수를 호출하거나 plot_classifier, plot_regressor, plot_clusterer의 출력을 해석할 때 레퍼런스로 활용하세요.
학습 곡선
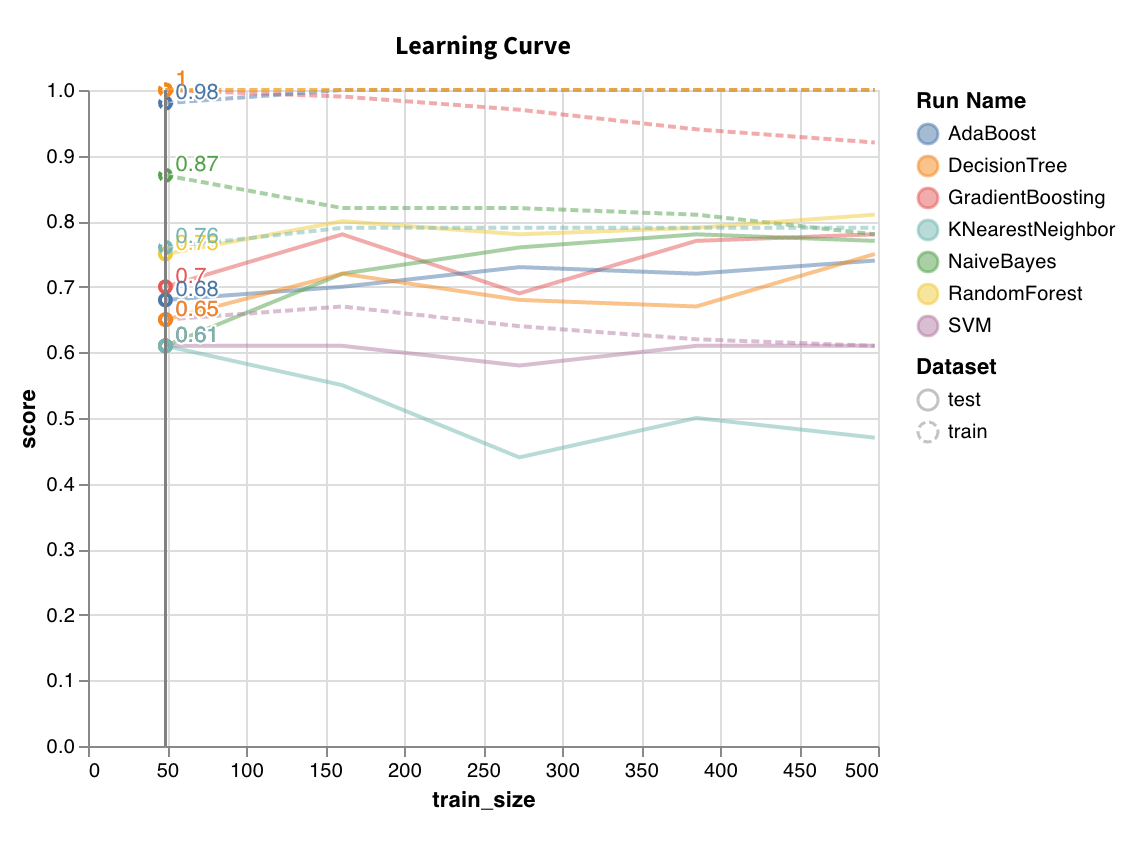
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf or reg): 학습이 완료된 회귀 모델 또는 분류기를 입력받습니다.
- X (arr): 데이터셋 특성.
- y (arr): 데이터셋 레이블.
ROC
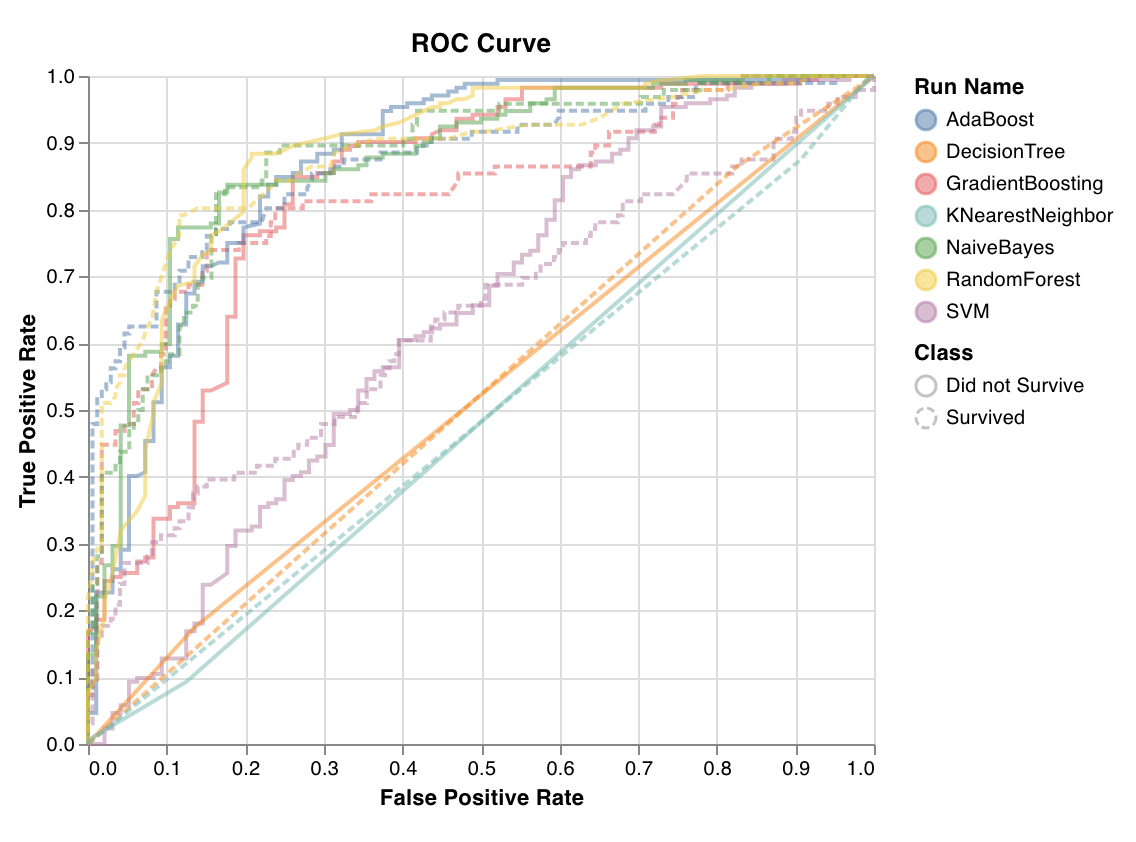
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): 테스트 세트 레이블.
- y_probas (arr): 테스트 세트의 예측 확률.
- labels (list): 타깃 변수(y)의 레이블 이름 목록.
클래스 비율
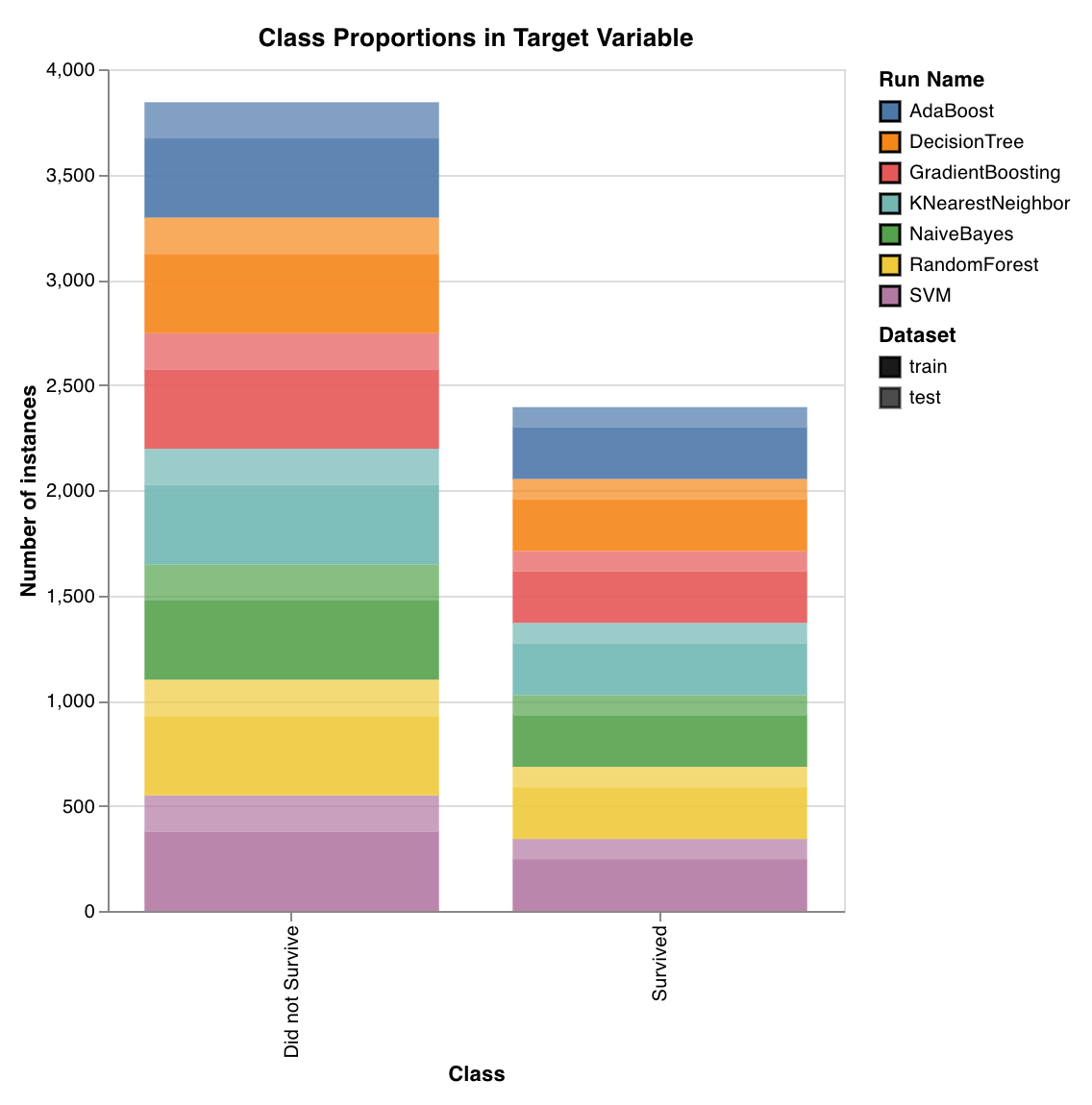
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): 트레이닝 세트 레이블
- y_test (arr): 테스트 세트 레이블
- labels (list): 타깃 변수(y)의 이름이 지정된 레이블
정밀도-재현율 곡선
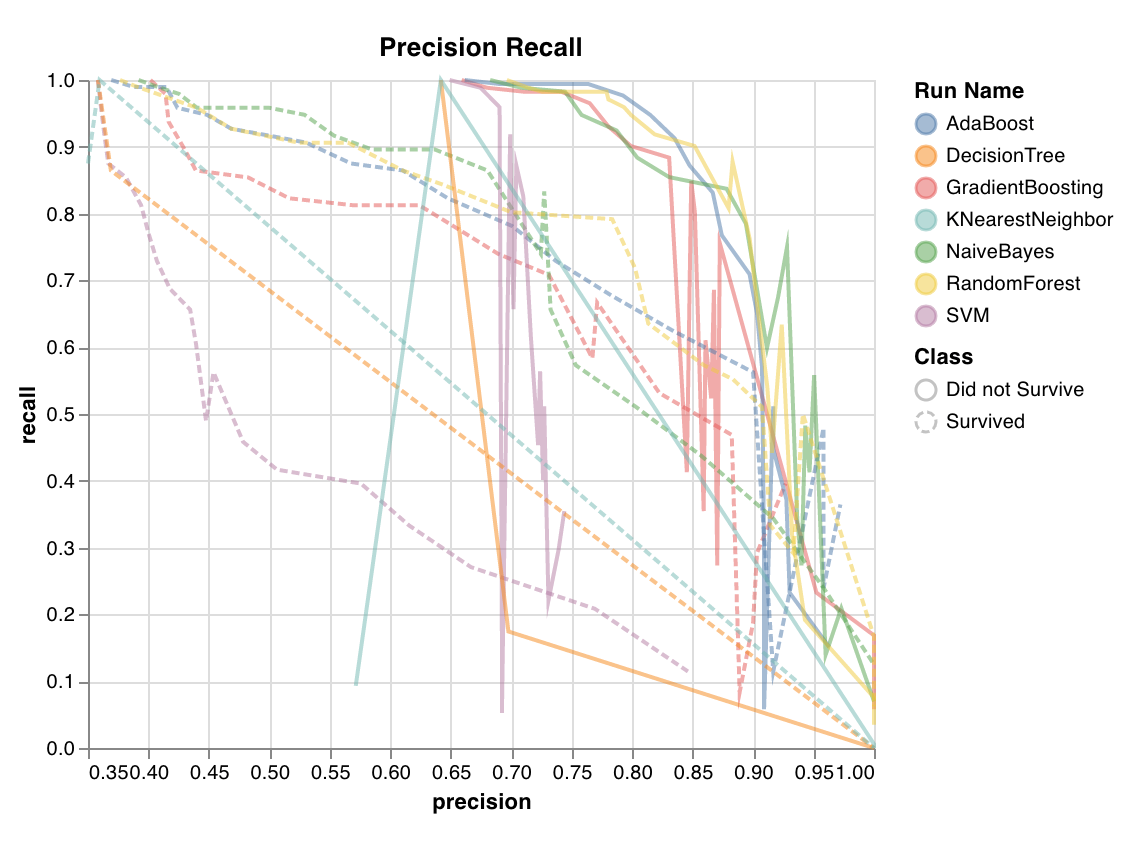
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): 테스트 세트 레이블입니다.
- y_probas (arr): 테스트 세트의 예측 확률입니다.
- labels (list): 타깃 변수(y)의 레이블 이름 목록입니다.
특성 중요도
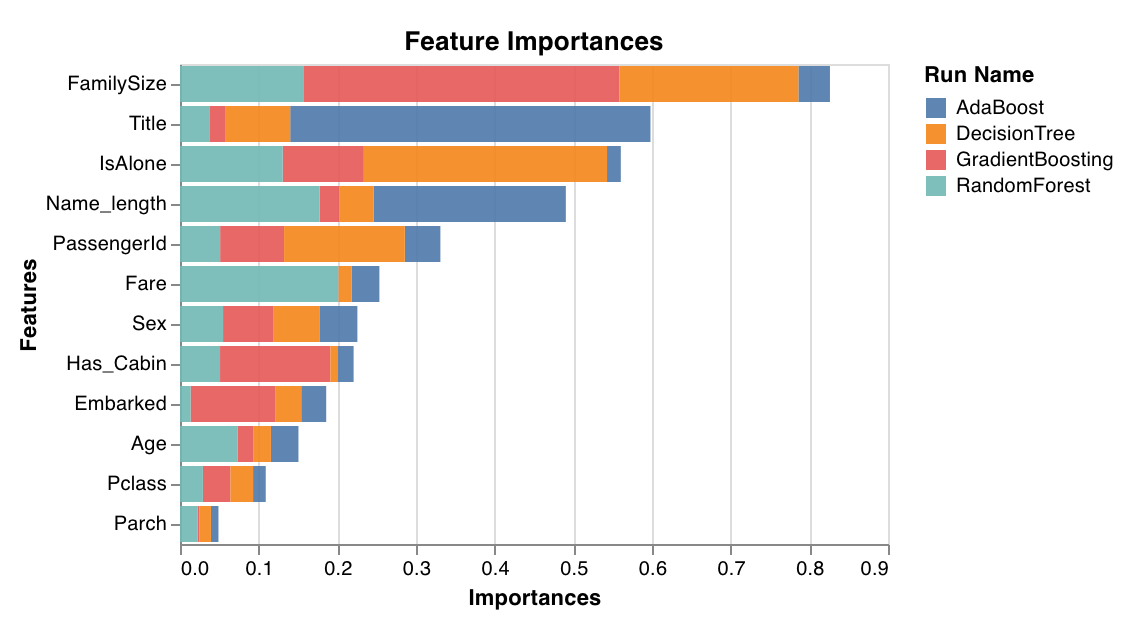
feature_importances_ 속성이 있는 분류기에서만 작동합니다.
wandb.sklearn.plot_feature_importances(model, ['width', 'height', 'length'])
- model (clf): 학습이 완료된 분류기를 입력으로 받습니다.
- feature_names (list): 특성 이름입니다. 특성 인덱스를 해당 이름으로 바꿔 플롯을 더 쉽게 읽을 수 있게 합니다.
보정 곡선
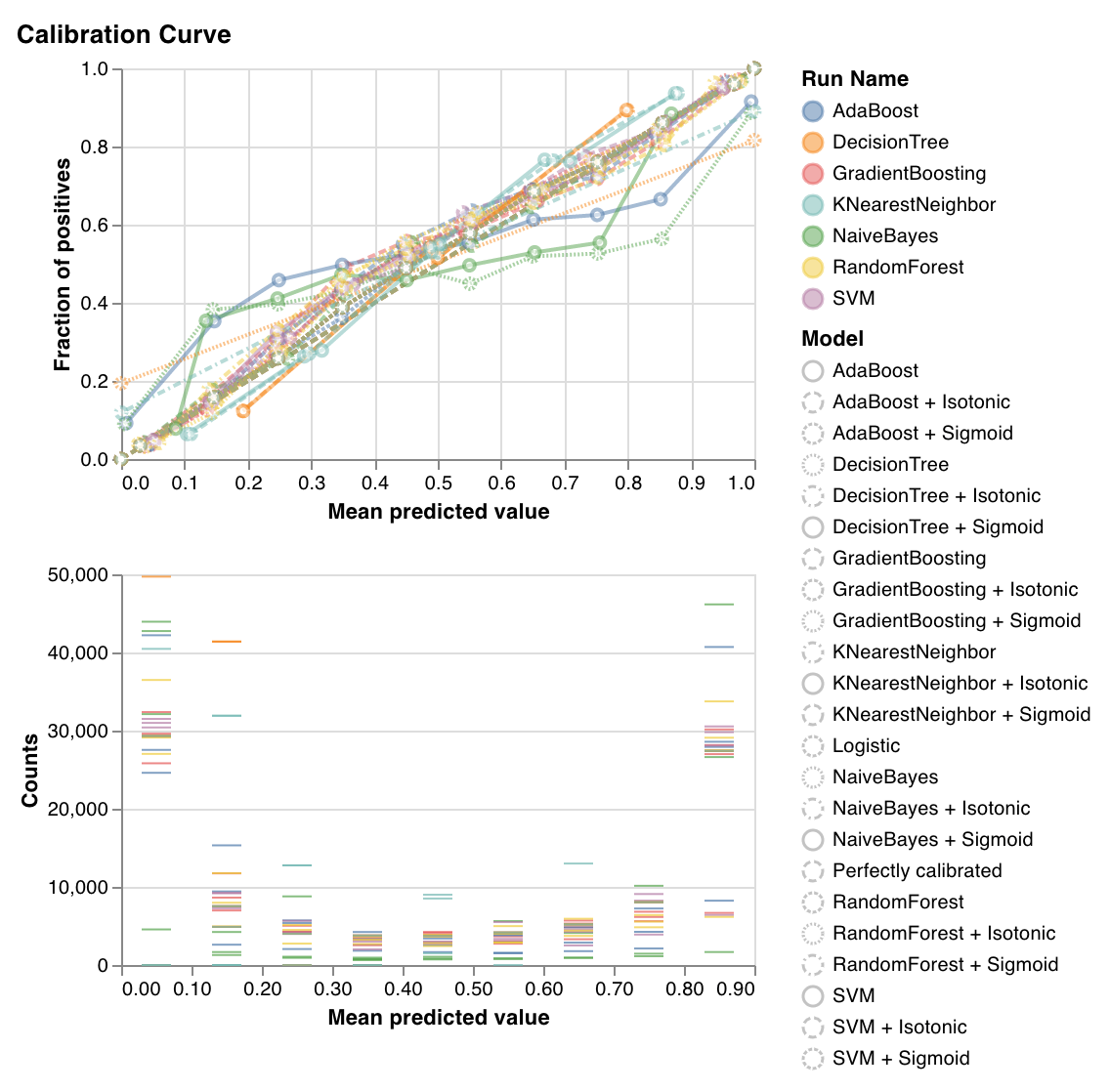
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): 학습이 완료된 분류기를 입력받습니다.
- X (arr): 트레이닝 세트 특성.
- y (arr): 트레이닝 세트 레이블.
- model_name (str): 모델 이름입니다. 기본값은
"Classifier"입니다.
혼동 행렬
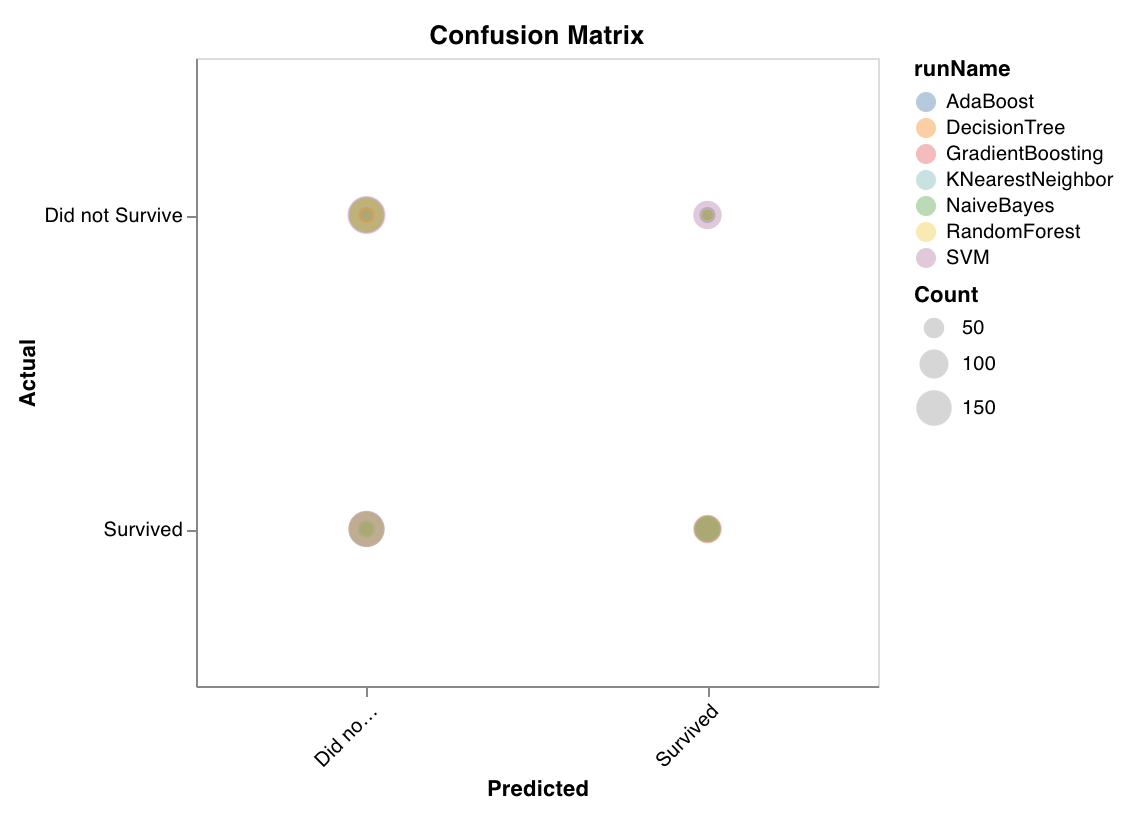
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): 테스트 세트 레이블
- y_pred (arr): 테스트 세트 예측 레이블
- labels (목록): 타깃 변수(y)의 레이블 이름 목록
요약 메트릭
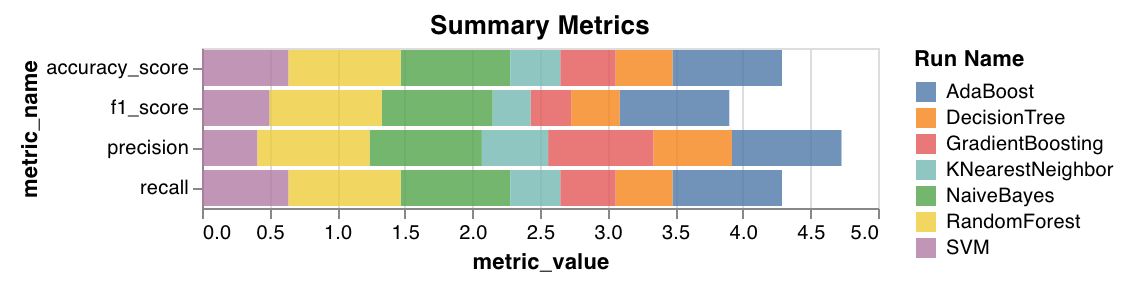
mse,mae,r2score와 같은 분류 요약 메트릭을 계산합니다.f1, accuracy, precision, recall과 같은 회귀 요약 메트릭을 계산합니다.
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf or reg): 학습이 완료된 회귀 모델 또는 분류기를 입력으로 받습니다.
- X (arr): 트레이닝 세트 특성입니다.
- y (arr): 트레이닝 세트 레이블입니다.
- X_test (arr): 테스트 세트 특성입니다.
- y_test (arr): 테스트 세트 레이블입니다.
엘보 플롯
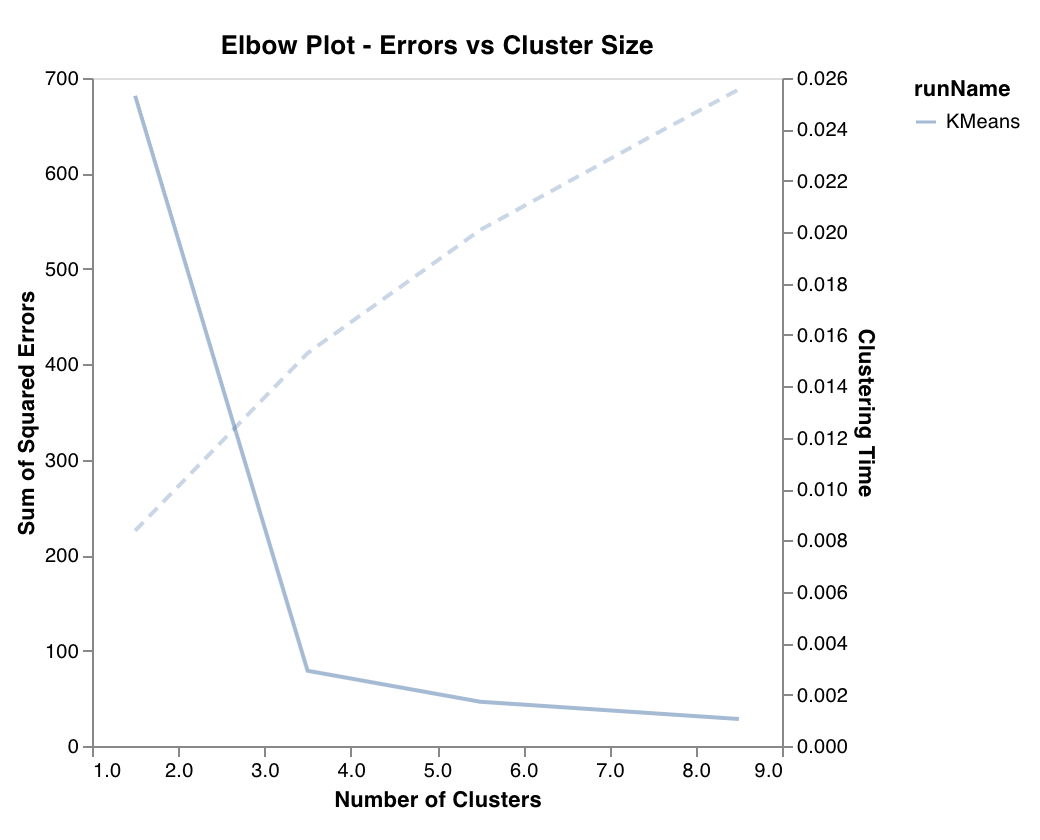
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): 학습이 완료된 클러스터러를 받습니다.
- X (arr): 트레이닝 세트 특성.
실루엣 플롯
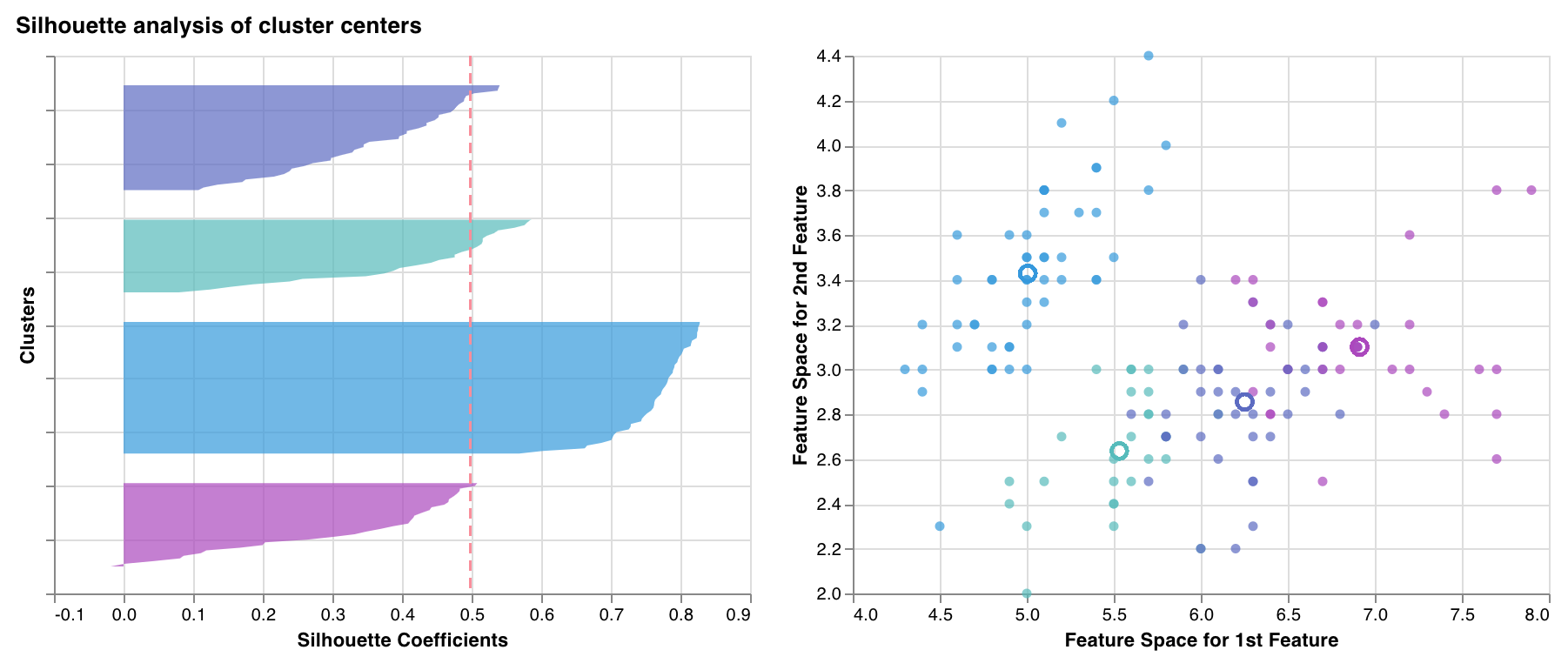
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (클러스터러): 학습이 완료된 클러스터러를 입력으로 받습니다.
- X (arr): 트레이닝 세트 특성.
- cluster_labels (list): 클러스터 레이블 이름입니다. 클러스터 인덱스를 해당 이름으로 바꿔 표시해 플롯을 더 읽기 쉽게 만듭니다.
이상치 후보 플롯
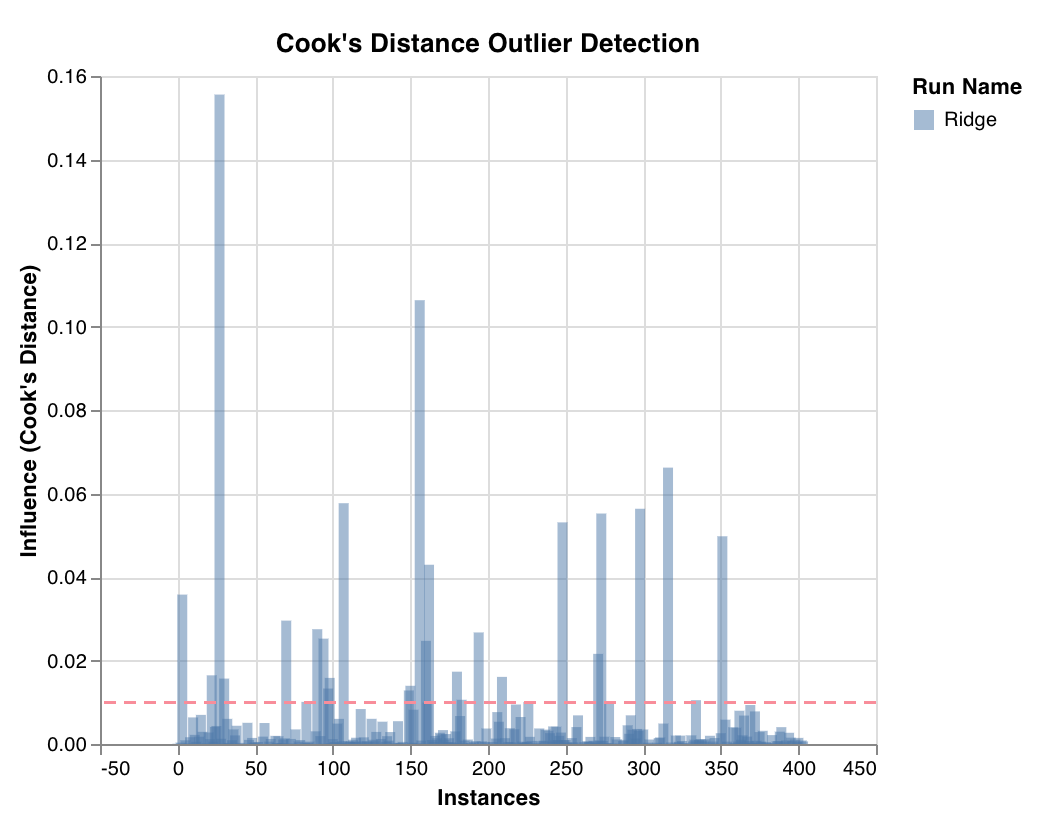
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): 학습이 완료된 회귀 모델을 입력으로 받습니다.
- X (arr): 트레이닝 세트 특성.
- y (arr): 트레이닝 세트 레이블.
잔차 플롯
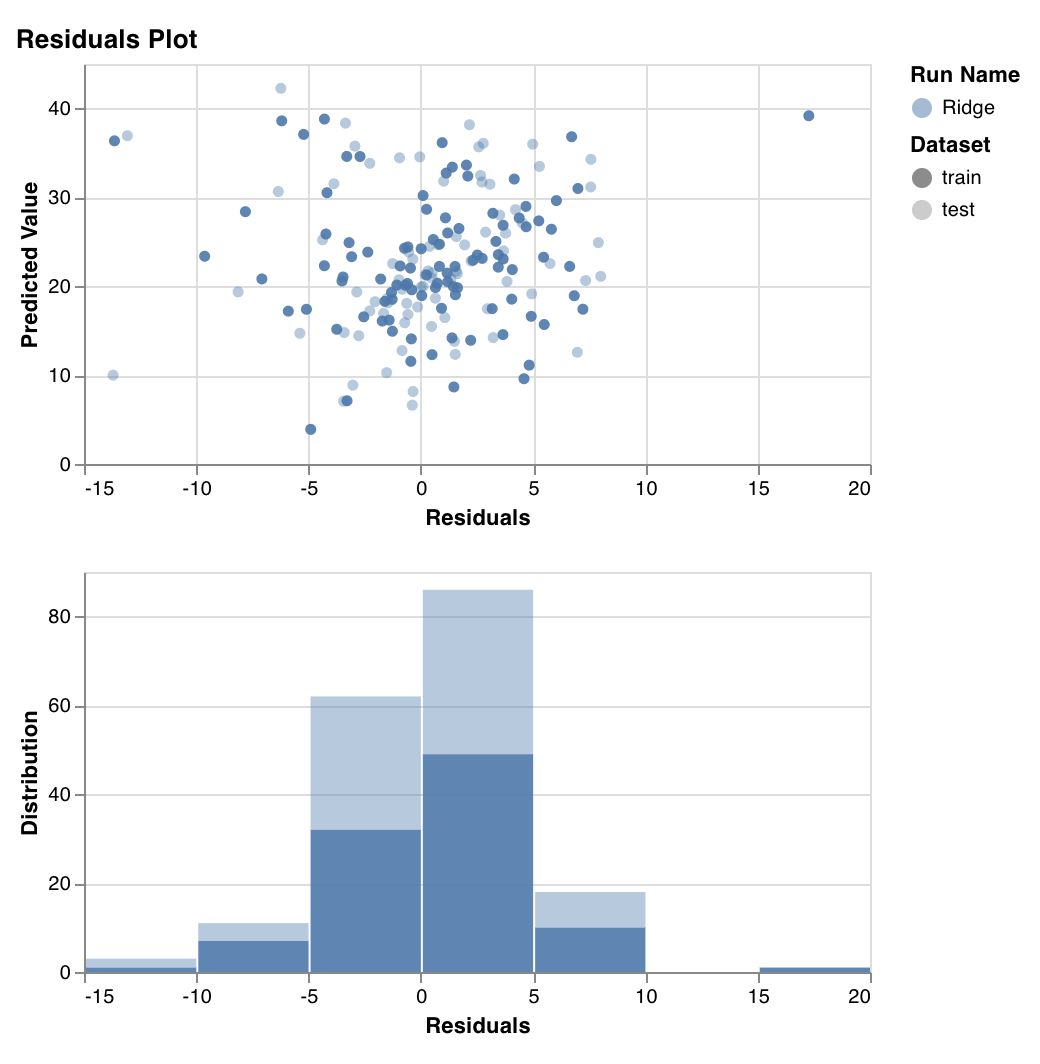
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): 학습이 완료된 회귀 모델을 입력으로 받습니다.
- X (arr): 트레이닝 세트 특성.
- y (arr): 트레이닝 세트 레이블.