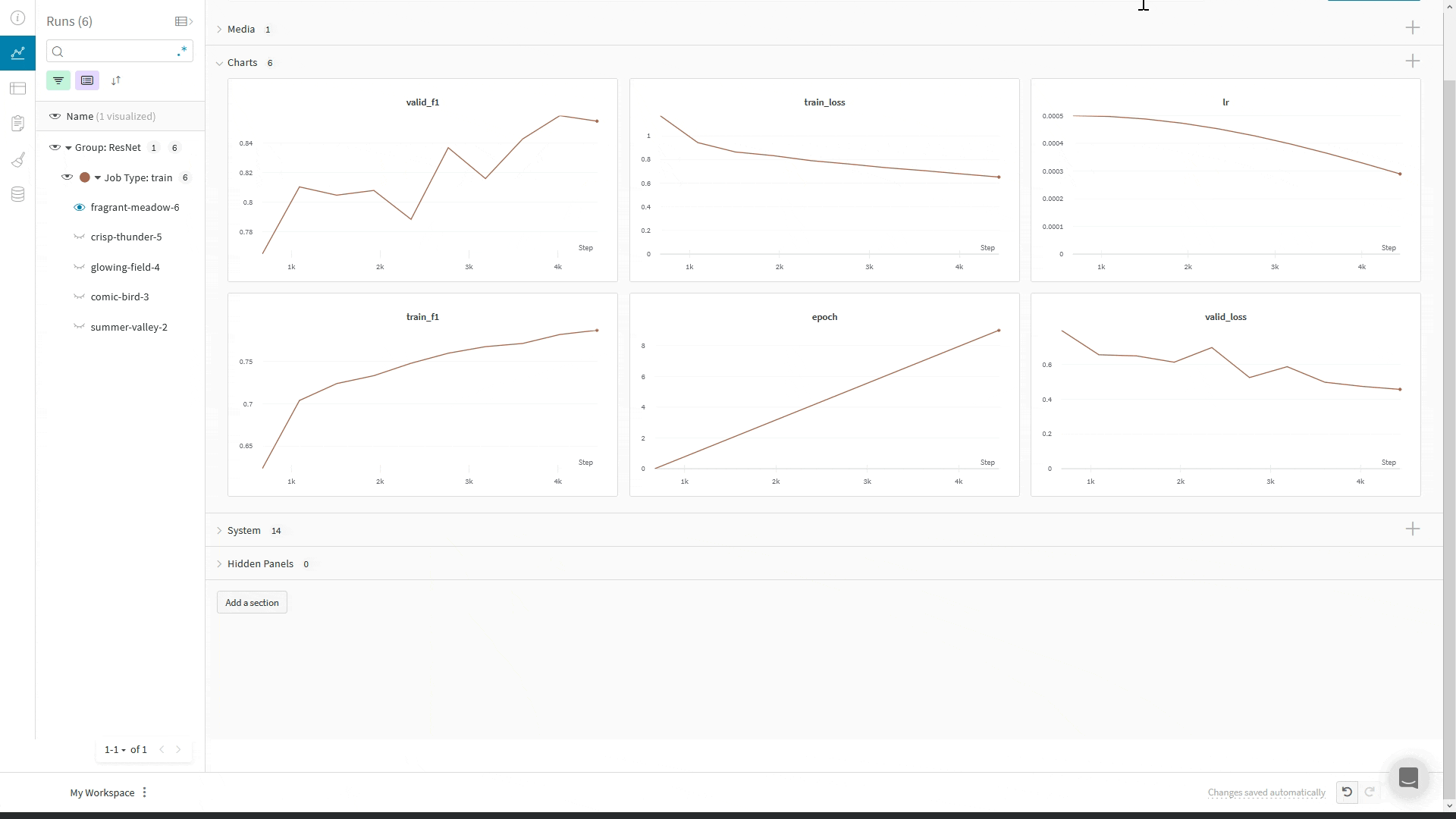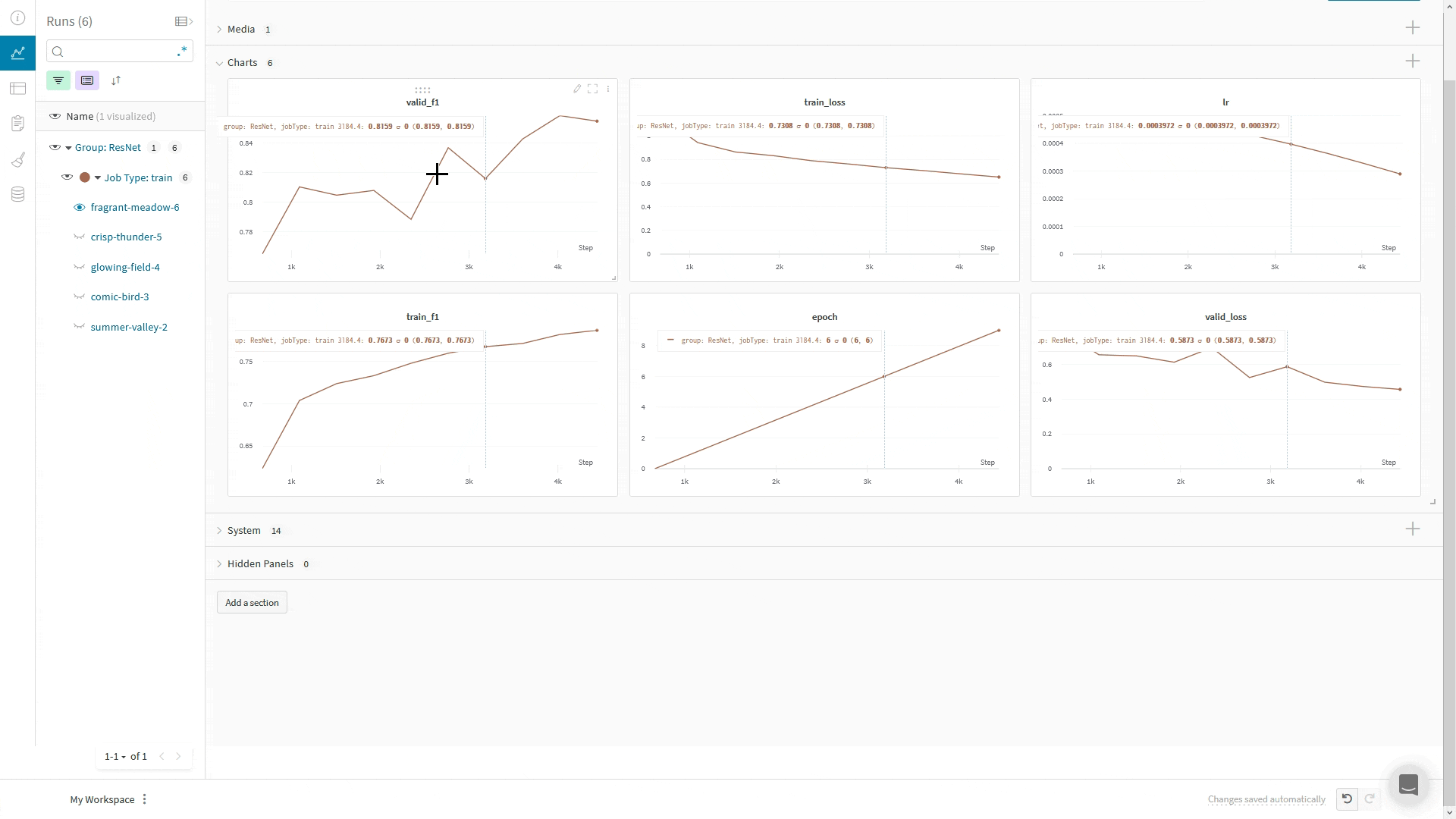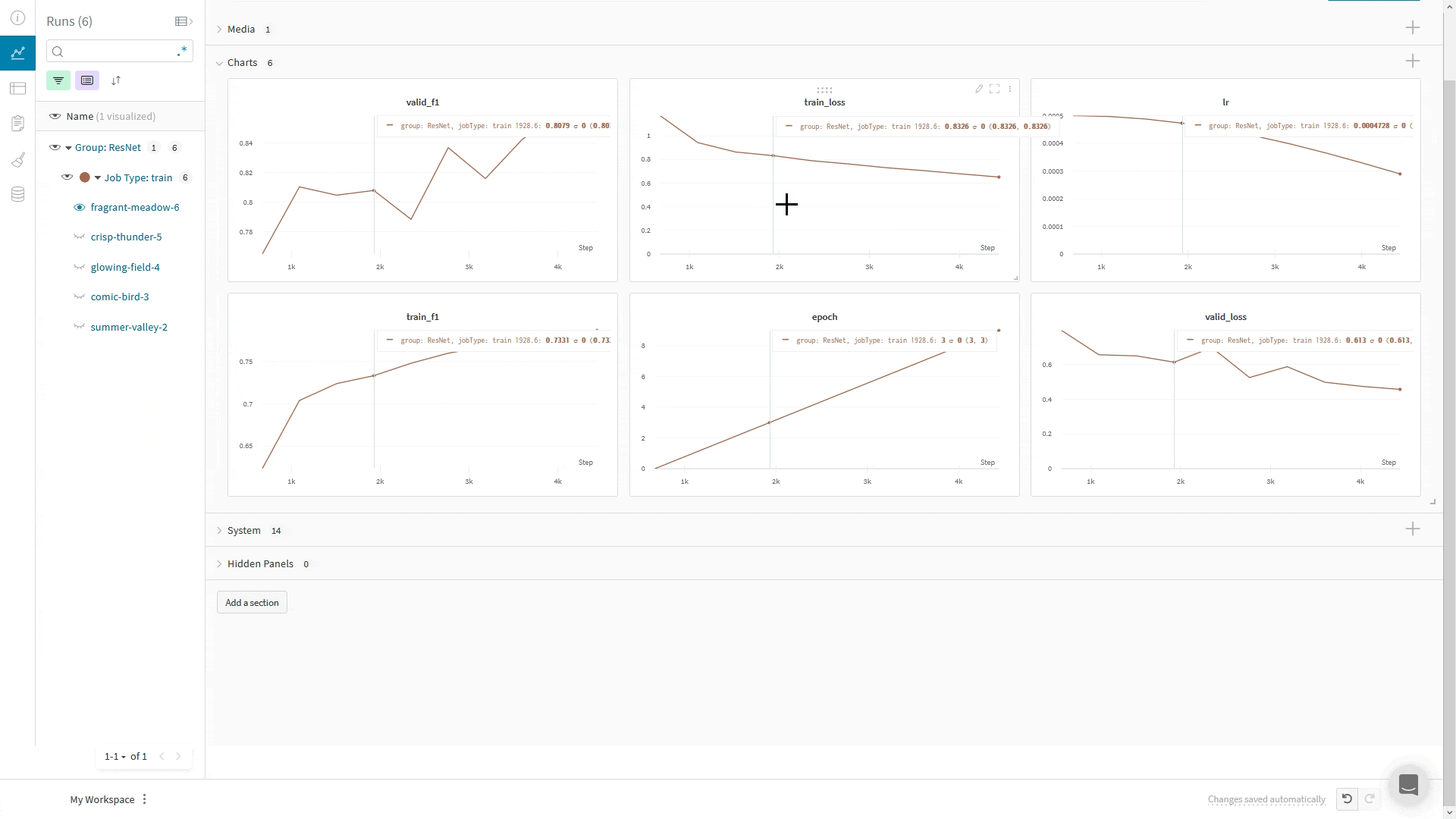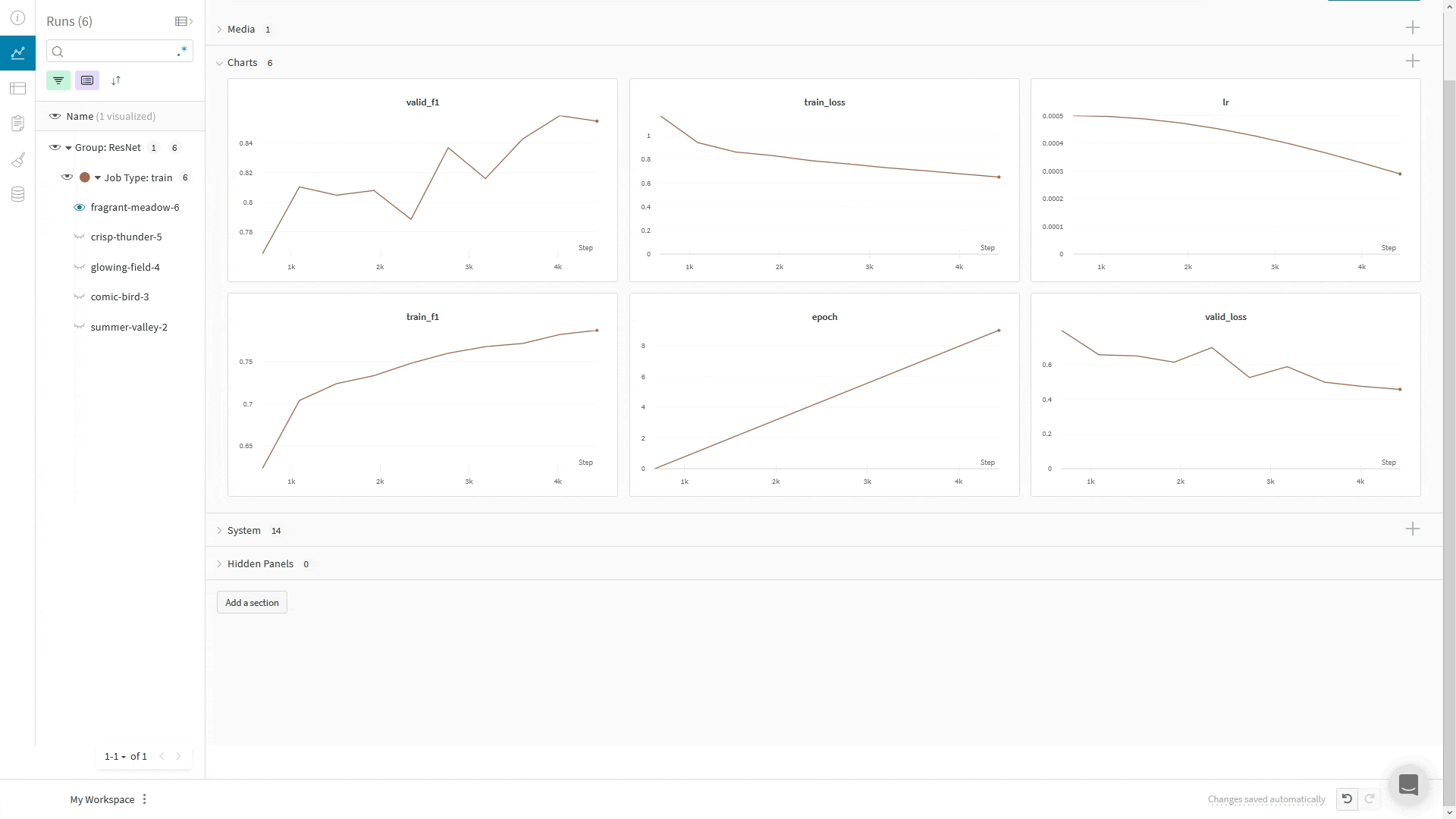
import wandb
from composer import Callback, State, Logger
class LogPredictions(Callback):
def __init__(self, num_samples=100, seed=1234):
super().__init__()
self.num_samples = num_samples
self.data = []
def eval_batch_end(self, state: State, logger: Logger):
"""배치별 예측을 계산하고 self.data에 저장합니다"""
if state.timer.epoch == state.max_duration: #마지막 검증 에포크에서
if len(self.data) < self.num_samples:
n = self.num_samples
x, y = state.batch_pair
outputs = state.outputs.argmax(-1)
data = [[wandb.Image(x_i), y_i, y_pred] for x_i, y_i, y_pred in list(zip(x[:n], y[:n], outputs[:n]))]
self.data += data
def eval_end(self, state: State, logger: Logger):
with wandb.init() as run:
"Create a wandb.Table and logs it"
columns = ['image', 'ground truth', 'prediction']
table = wandb.Table(columns=columns, data=self.data[:self.num_samples])
run.log({'sample_table':table}, step=int(state.timer.batch))
...
trainer = Trainer(
...
loggers=[WandBLogger()],
callbacks=[LogPredictions()]
)