이 문서는 대화형 노트북입니다. 로컬에서 실행하거나 다음 링크를 사용할 수 있습니다.
- DSPy: LLM 워크플로를 구축하고 최적화하는 데 사용합니다.
- Weave: LLM 워크플로를 추적하고 프롬프팅 전략을 평가하는 데 사용합니다.
- datasets: HuggingFace Hub에서 BIG-Bench Hard 데이터셋에 액세스하는 데 사용합니다.
이 튜토리얼에서는 LLM 공급업체로 OpenAI API를 사용하므로 OpenAI API 키도 필요합니다. OpenAI 플랫폼에서 회원가입하여 직접 API 키를 발급받을 수 있습니다.
이 섹션에서는 튜토리얼의 이후 DSPy Call이 자동으로 트레이스되고 Weave UI에서 볼 수 있도록 Weave를 구성합니다.
Weave는 DSPy와 통합되어 있습니다. 코드 시작 부분에 weave.init을 포함하면 DSPy 함수가 자동으로 트레이스되며, 이후 Weave UI에서 이를 탐색할 수 있습니다. 자세한 내용은 DSPy용 Weave 인테그레이션 문서를 확인하세요.
이 튜토리얼에서는 weave.Object를 상속한 메타데이터 클래스를 사용해 메타데이터를 관리합니다.
객체 버전 관리: Metadata 객체를 사용하는 함수가 트레이스되면, 해당 객체도 자동으로 버전 관리되고 트레이스됩니다.
weave.Evaluation을 사용해 프롬프팅 전략도 평가할 수 있습니다.
데이터셋을 Weave에 게시했으므로, 이제 나중에 평가하고 최적화할 베이스라인 DSPy 프로그램을 정의할 수 있습니다.
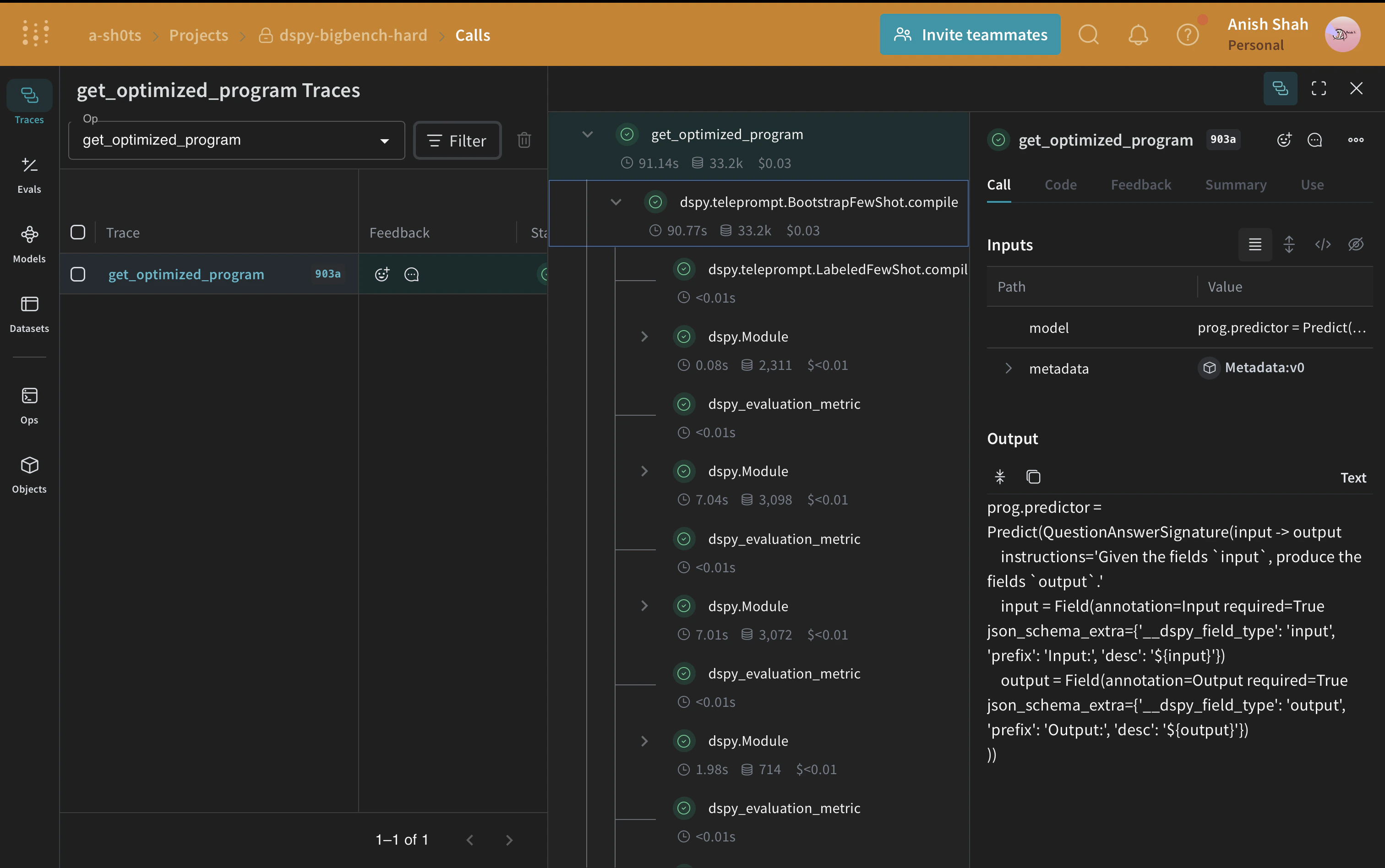
DSPy는 자유 형식 문자열을 직접 조작하는 방식에서 벗어나, 프로그래밍(모듈식 Operator를 조합해 텍스트 변환 그래프를 구성하는 방식)에 더 가깝게 새로운 LM 파이프라인을 구축하도록 돕는 프레임워크입니다. 여기서 컴파일러는 프로그램으로부터 최적화된 LM 호출 전략과 프롬프트를 자동으로 생성합니다.
언어 모델을 설정하려면 dspy.LM을 사용하고, 이를 기본값으로 설정하려면 dspy.configure를 사용하세요.
시그니처는 DSPy 모듈의 입력/출력 동작을 선언적으로 정의하는 명세입니다. DSPy 모듈은 작업에 맞게 적응하는 컴포넌트로, 신경망의 계층과 유사하며 특정 텍스트 변환을 추상화합니다.
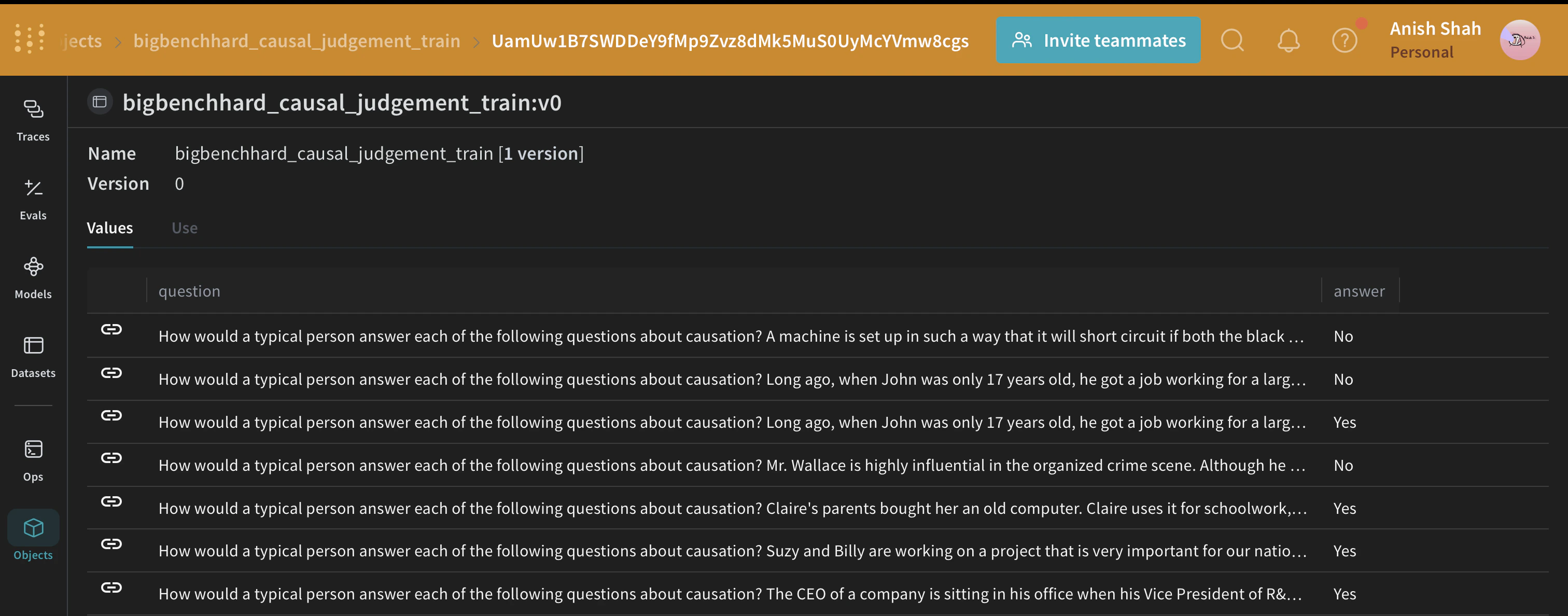
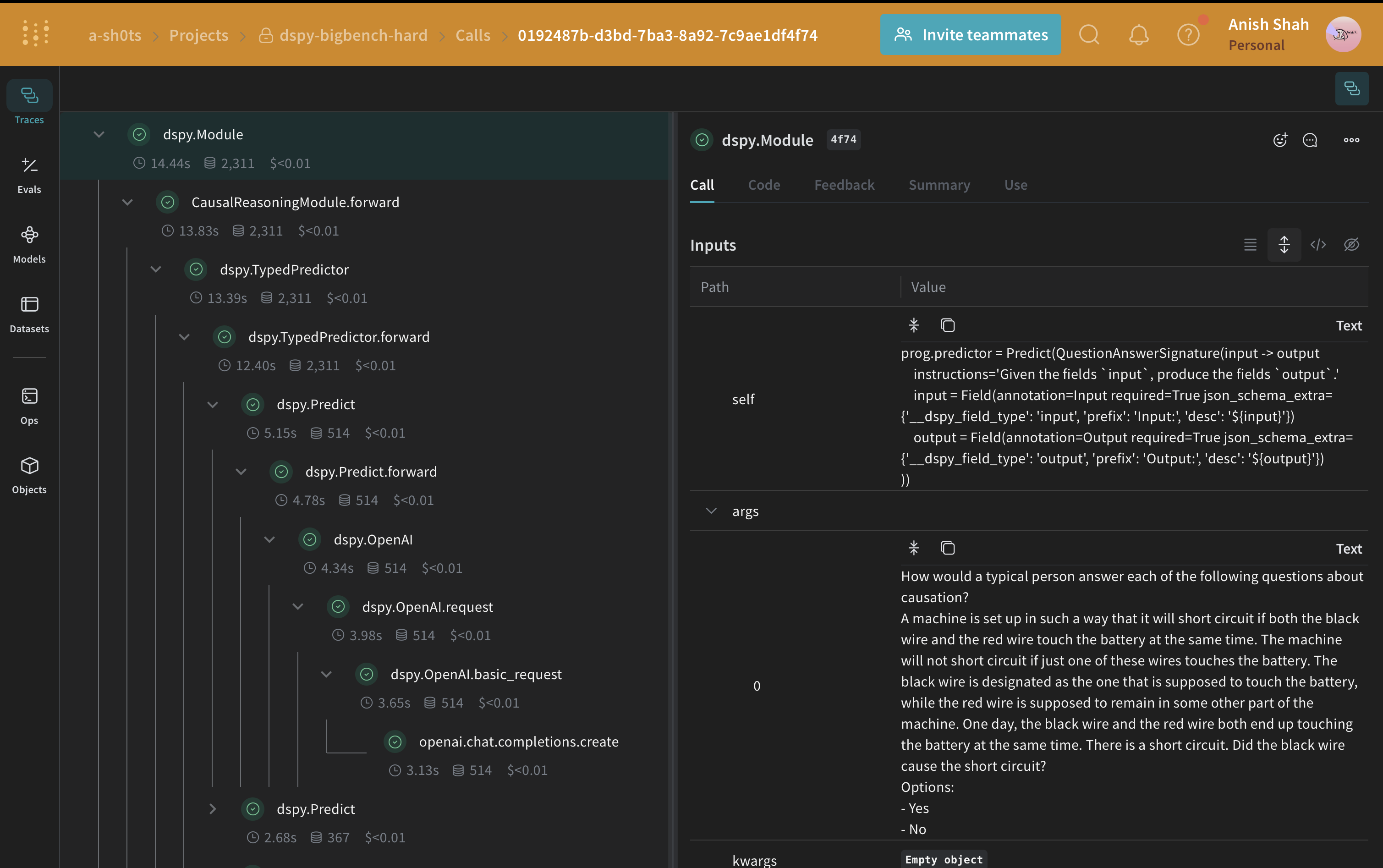
BIG-Bench Hard의 인과 추론 하위 집합에 있는 예시 항목으로 LLM 워크플로(즉, CausalReasoningModule)를 테스트하세요.
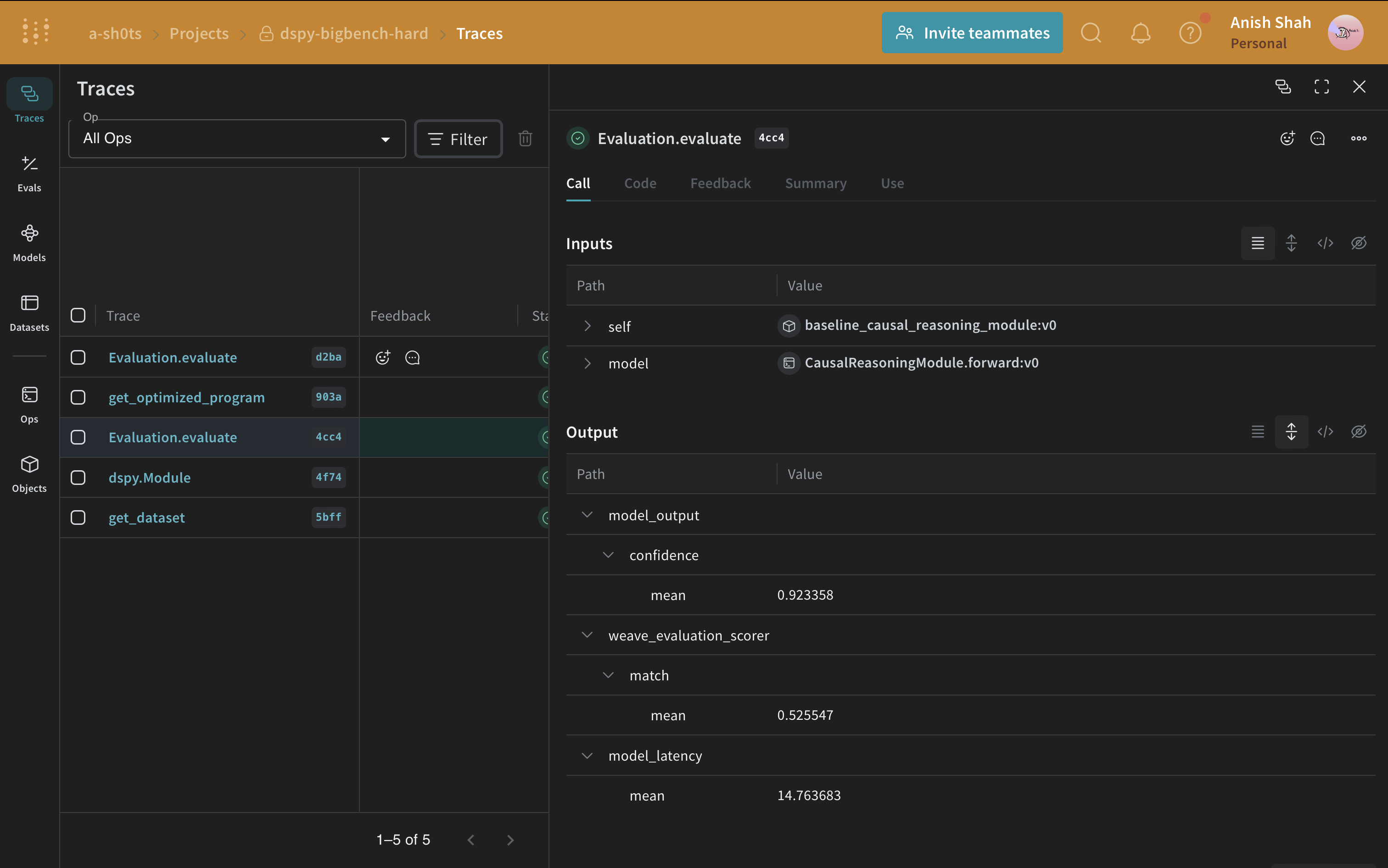
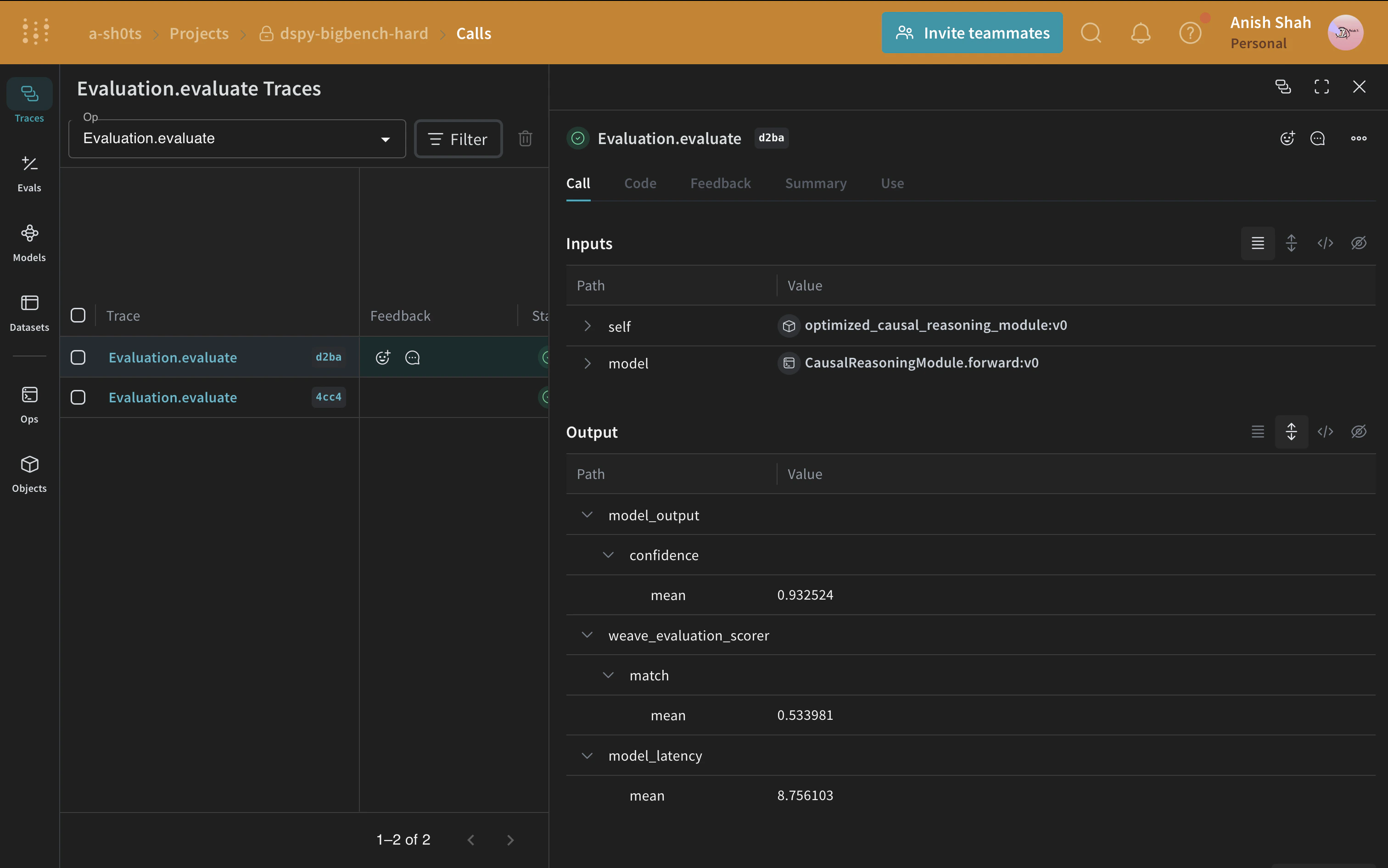
이제 베이스라인 프롬프팅 전략이 있으므로, 예측된 답변이 정답과 일치하는 메트릭과 함께 weave.Evaluation을 사용해 검증 세트에서 평가하세요. Weave는 각 예시를 가져와 애플리케이션에 전달한 다음, 여러 맞춤형 채점 함수로 출력을 평가합니다. 이렇게 하면 애플리케이션의 성능을 보여주는 뷰를 얻을 수 있고, 개별 출력과 점수를 자세히 살펴볼 수 있는 풍부한 UI도 활용할 수 있습니다.
먼저 예측된 답변이 정답과 일치하는지 판별하는 채점 함수를 만드세요. Weave 채점 함수는 모델의 반환 값을 output으로 받고, 데이터셋 예시의 일치하는 키를 추가 인수로 받습니다. 여기서 answer는 데이터셋에서 오고, output은 CausalReasoningModule.forward가 반환한 dict입니다.
다음으로, weave.Evaluation이 호출할 수 있는 트레이스 함수로 모듈을 감쌉니다. 래퍼의 인수 이름은 모델이 사용하는 데이터셋 열 이름과 일치해야 합니다.
이제 평가를 정의하고 실행할 수 있습니다.
Python 스크립트에서 실행하는 경우, 다음 코드를 사용해 평가를 실행할 수 있습니다. 인과 추론 데이터셋으로 평가를 실행하면 OpenAI 크레딧이 약 $0.24 소요됩니다.
인과 추론 평가 데이터셋을 실행하는 데는 OpenAI 크레딧이 약 $0.04 정도 사용됩니다.