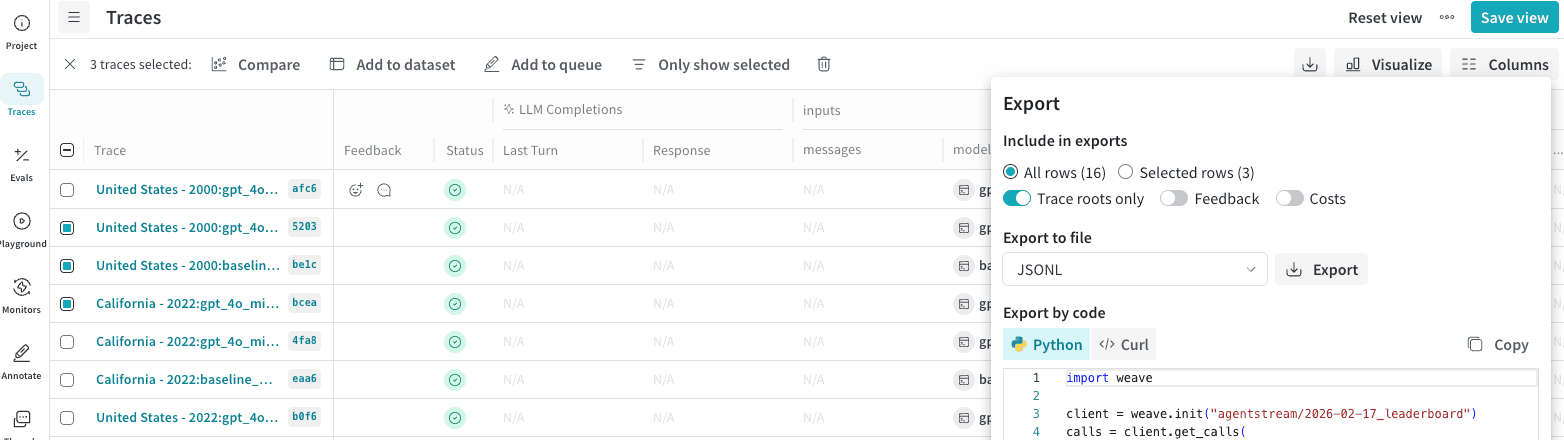
Export Calls from the Weave UI
In the Weave UI, you can export your data in multiple formats. The UI also shows the Python and cURL code that you can use to export the rows programmatically. To export Calls:- Navigate to wandb.ai and select your project.
- In the Weave project sidebar, click Traces.
- Select multiple Calls that you want to export by checking the row.
- In the Traces table toolbar, click the export or download button.
- In the Export modal, choose Selected rows or All rows.
- Click Export.
Fetch Calls programmatically
To filter, sort, or process Calls outside of the UI, fetch them with one of the Weave SDKs or the Service API. Choose the interface that best matches your workflow.- Python
- TypeScript
- HTTP API
To fetch Calls using the Python API, use the
client.get_calls method:Export Call metrics
When you need aggregate insights, such as cost or latency trends, rather than the underlying Call records, use the metrics endpoint described in this section. You can also use the Weave Service API’s POST/calls/stats endpoint to retrieve metrics about your Calls without retrieving the Call data itself. You can retrieve information about your Calls, such as latency and cost, and aggregate them by sum, average, minimum, maximum, and count. For example, you can retrieve:
- Total token usage
- Average latency
- Maximum tokens used
- Total cost
- Minimum input tokens
- Op name
- Trace ID
- Thread ID
- User ID
web_app over two days. Replace [YOUR-TEAM-NAME/YOUR-PROJECT-NAME] with your team and project names:
sum, count, avg, min, max, and count.
The endpoint returns a JSON object. The following example response shows two days’ worth of metrics. Each day (bucket) appears as its own object in the usage_buckets and call_buckets arrays. Each array breaks down the metrics differently:
usage_buckets: Groups Call metrics for each day by the model used.call_buckets: Groups Call metrics for each day regardless of the model used.